
Mọi người đang xây dựng cùng một thứ ngay bây giờ.
Thị trường dữ liệu AI. Mạng lưới đóng góp. Hạ tầng đào tạo. Câu chuyện giống hệt nhau: nhiều dữ liệu → mô hình tốt hơn → định giá lớn hơn. Câu chuyện sạch. Logic quen thuộc. Chán như con gián.
Mình nghĩ @OpenLedger đang vô tình xây dựng một cái gì đó kỳ quặc hơn.
Và thị trường vẫn chưa nhận ra điều đó.
Vấn đề mà không ai nói đến
Đây là điều mình luôn để ý: các công ty công nghệ cuồng nhiệt về những gì hệ thống AI có thể học, nhưng gần như không dành thời gian suy nghĩ về những gì những hệ thống đó nên được phép ghi nhớ.
Sự phân biệt đó không quan trọng khi AI tạo ra thơ hay phản hồi từ chatbot. Nhưng nó rất quan trọng khi AI bắt đầu chạm vào quyết định cho vay, quy trình tuân thủ, xác minh danh tính, hoặc hệ thống tư vấn tài chính.
Bởi vì một khi trí thông minh đưa ra quyết định thực sự, ký ức không còn là một tài sản thụ động. Nó trở thành một bề mặt trách nhiệm.
Hầu hết mọi người định hình #OpenLedger như một cơ sở hạ tầng cho việc đóng góp dữ liệu AI. Những người đóng góp cung cấp các bộ dữ liệu. Những người xây dựng tiêu thụ chúng. Các mô hình cải thiện. $OPEN điều phối các động lực. Kịch bản crypto chuẩn.
Nhưng tôi nghĩ câu chuyện thực sự là ngược lại.
Điều gì sẽ xảy ra nếu điểm nghẽn tiếp theo của AI không phải là học — mà là quên?
Hãy nghĩ về cách mà AI hiện đại thực sự hoạt động. Một khi dữ liệu được hấp thụ vào các quy trình đào tạo, nhúng, các lớp truy xuất, hoặc hành vi tinh chỉnh, việc loại bỏ không giống như xóa một tệp. Thông tin khuếch tán.
Việc máy móc quên đi là một lĩnh vực nghiên cứu hoàn toàn thừa nhận một điều không thoải mái: dạy máy móc là dễ. Khiến chúng quên đi một cách chính xác gần như là không thể.
Điều đó có thể chấp nhận được khi AI còn nằm trong các sandbox. Không còn nữa.
Các nhà quản lý ngày càng sắc bén hơn. Các doanh nghiệp đang trở nên thận trọng. AI đang tiến vào các quy trình liên quan đến thanh toán, danh tính, giao tiếp nội bộ, quy định — những bề mặt mà sai sót tốn tiền thật.
Và khi các hệ thống chạm vào hoạt động thực tế, câu hỏi chuyển từ "mô hình này có thể hoạt động không?" sang "mô hình này thực sự đang mang gì về phía trước?"
Câu hỏi khác. Hệ quả lớn hơn.
Đầu tư cơ sở hạ tầng ẩn mà hầu hết mọi người đang bỏ lỡ.
Đây là nơi OpenLedger trở nên thú vị:
Nếu phân bổ trở nên liên tục và có ý nghĩa kinh tế, thì ký ức được giữ lại không còn là cơ sở hạ tầng miễn phí. Nó trở thành một đối tượng kinh tế được quản lý.
Điều đó hoàn toàn đảo ngược cấu trúc động lực.
Hiện tại, các hệ thống AI giữ lại thông tin vì việc giữ lại là hữu ích. Cá nhân hóa tốt hơn, liên tục tốt hơn, đầu ra tốt hơn. Giả định ở đây rất đơn giản: giữ lại ngữ cảnh luôn mang lại lợi ích.
Nhưng trong một mạng lưới mà những người đóng góp có thể được xác định và dòng giá trị được liên kết với nguồn gốc, ký ức bắt đầu mang chi phí.
Và một khi ký ức mang chi phí, việc quên đi trở nên hợp lý.
Hãy tưởng tượng một trợ lý AI doanh nghiệp được đào tạo dựa trên các tương tác khách hàng độc quyền. Sau sáu tháng, một khách hàng thu hồi quyền dữ liệu. Hoặc quy định thay đổi. Hoặc công ty quyết định rằng một số tương tác lịch sử nhất định tạo ra rủi ro pháp lý.
Vấn đề không chỉ là xóa bỏ nhật ký. Mà là quyết định xem trí thông minh được hình thành từ những tương tác đó nên giữ nguyên hoạt động hay không.
Ngành y tế làm cho tình hình này càng tồi tệ hơn. Các hệ thống tài chính cũng vậy.

Tại sao câu chuyện này lại quan trọng bây giờ
Cơn sốt áp dụng AI đang tạo ra một cuộc khủng hoảng niềm tin mà không ai muốn thảo luận.
Các tổ chức không ghét AI. Họ ghét sự không chắc chắn mà họ không thể hoạt động hóa. Và ký ức được giữ lại mà không có phân bổ tạo ra chính xác sự không chắc chắn đó.
Đó là lý do tại sao tôi nghĩ $OPEN có thể không cạnh tranh ở nơi mà hầu hết mọi người nghĩ.
Không phải tính toán. Không phải quyền truy cập mô hình. Không phải thị trường dữ liệu.
Cơ sở hạ tầng để đàm phán những gì các hệ thống AI được phép nhớ, chúng nhớ bao lâu, và ai được công nhận về mặt kinh tế trong khi ký ức đó còn sống.
Đó là một luận điểm ít hào nhoáng hơn nhiều. Đó chính xác là lý do tại sao nó có thể quan trọng.
Kịch bản Bò
Nếu luận điểm này diễn ra:
Mỗi triển khai AI trong doanh nghiệp cần cơ sở hạ tầng phân bổ.
Hiệu ứng mạng càng gia tăng khi nhiều hệ thống tích hợp hơn.
Tiện ích của token vượt ra ngoài đầu cơ thành sự cần thiết trong hoạt động.
OpenLedger trở thành "cơ sở hạ tầng nhàm chán" thu hút giá trị khổng lồ.
Các câu chuyện về cơ sở hạ tầng thường có giá trị lâu dài. Hãy hỏi những nhà đầu tư sớm vào đám mây.
Kịch bản Gấu
Rủi ro thực thi là có thật. Việc phân bổ là khá khó khăn về mặt kỹ thuật. Việc máy móc quên đi thực sự rất khó.
Kinh tế token có thể tự làm phức tạp. Cơ sở hạ tầng tư nhân thường thắng vì sự đơn giản trong hoạt động quan trọng hơn sự tinh khiết về khái niệm.
Và có một câu hỏi về nhu cầu: tại sao áp lực hữu cơ bền vững tồn tại thay vì đầu cơ tạm thời?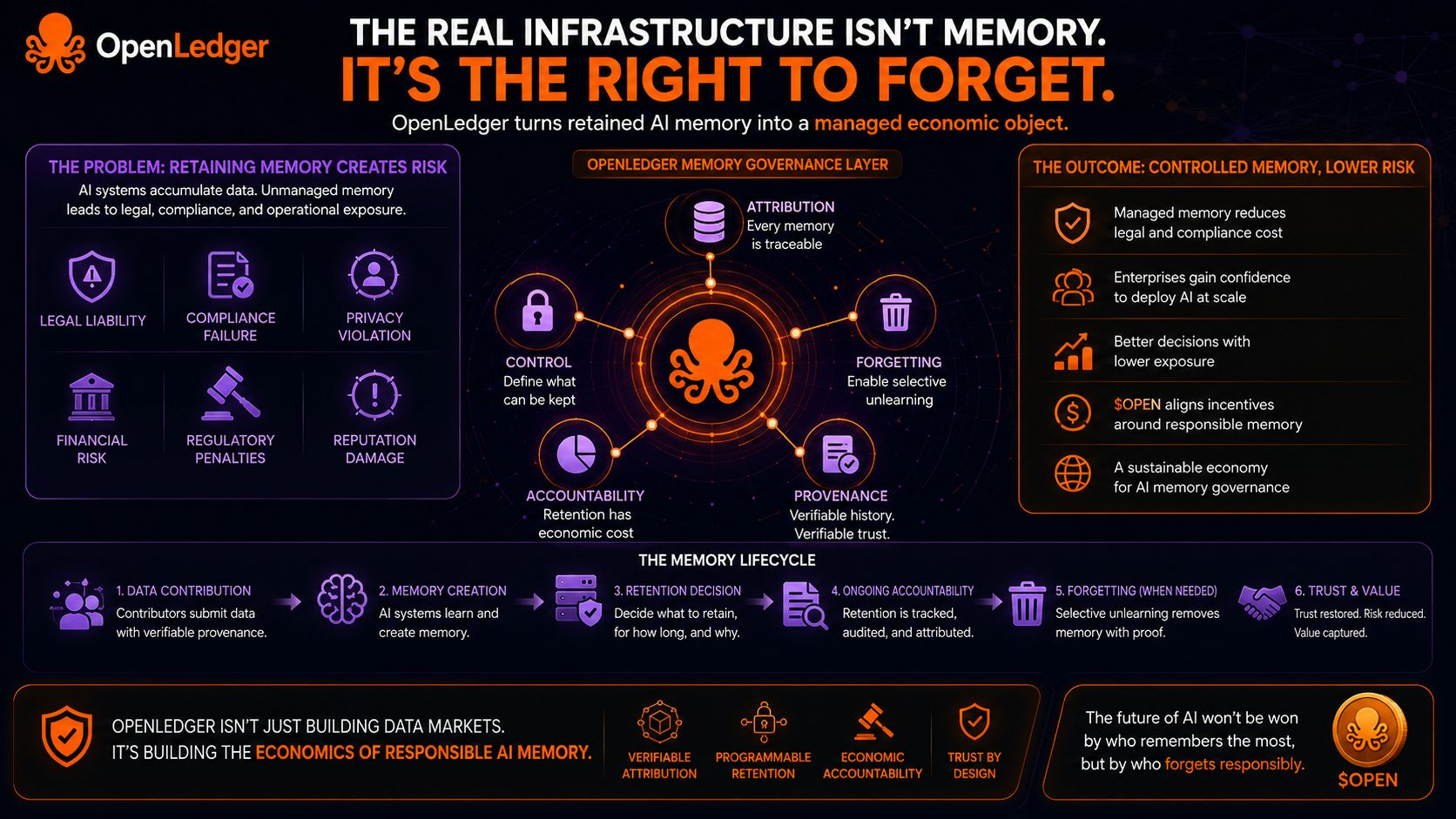
Kết luận Đối kháng
Thị trường AI vẫn hành xử như trí thông minh là tài sản khan hiếm.
Tôi ngày càng nghĩ rằng trách nhiệm có thể trở nên khan hiếm hơn trí thông minh.
Nếu tôi đúng, @OpenLedger không chỉ là token hóa các đóng góp dữ liệu. Nó đang xây dựng cơ sở hạ tầng quản trị ký ức cho các hệ thống AI cần quên đi một cách đúng đắn.
Hãy tự hỏi bản thân: trong 12 tháng tới, các doanh nghiệp sẽ quan tâm nhiều hơn đến chất lượng mô hình hay trách nhiệm quyết định?
Bởi vì nếu là cái sau, chúng ta đang định giá sai những gì mà cơ sở hạ tầng thực sự quan trọng.
#OpenLedger #AIInfrastructure #CryptoAi #DecentralizedAI #DataEconomy