Hầu hết mọi người sử dụng trí tuệ nhân tạo mà không bao giờ nghĩ đến lớp vô hình bên dưới nó. Một chatbot trả lời câu hỏi ngay lập tức, một công cụ AI viết mã, hoặc một trình tạo hình ảnh tạo ra tác phẩm nghệ thuật trong vài giây. Trải nghiệm cảm thấy mượt mà và gần như không tốn sức. Nhưng đằng sau mỗi hệ thống AI là một khối lượng thông tin khổng lồ do con người tạo ra, được thu thập qua nhiều năm từ các nhà văn, nhà phát triển, nhà nghiên cứu, nghệ sĩ, cộng đồng trực tuyến, và người dùng internet thông thường. Phần kỳ lạ là hầu hết những người đóng góp đó không bao giờ thực sự biết dữ liệu của họ đã được sử dụng như thế nào hoặc liệu họ có được hưởng lợi từ nó hay không.
Trong một thời gian dài, vấn đề này đã bị phớt lờ vì ngành AI phát triển quá nhanh. Các công ty tập trung vào việc xây dựng các mô hình lớn hơn, thu thập nhiều dữ liệu hơn và cải thiện hiệu suất. Các nhà đầu tư quan tâm đến tăng trưởng, người dùng quan tâm đến sự tiện lợi và các nhà phát triển quan tâm đến khả năng. Các câu hỏi xung quanh quyền sở hữu và ghi nhận thường ở đâu đó trong nền vì không có cách nào đơn giản để giải quyết chúng.
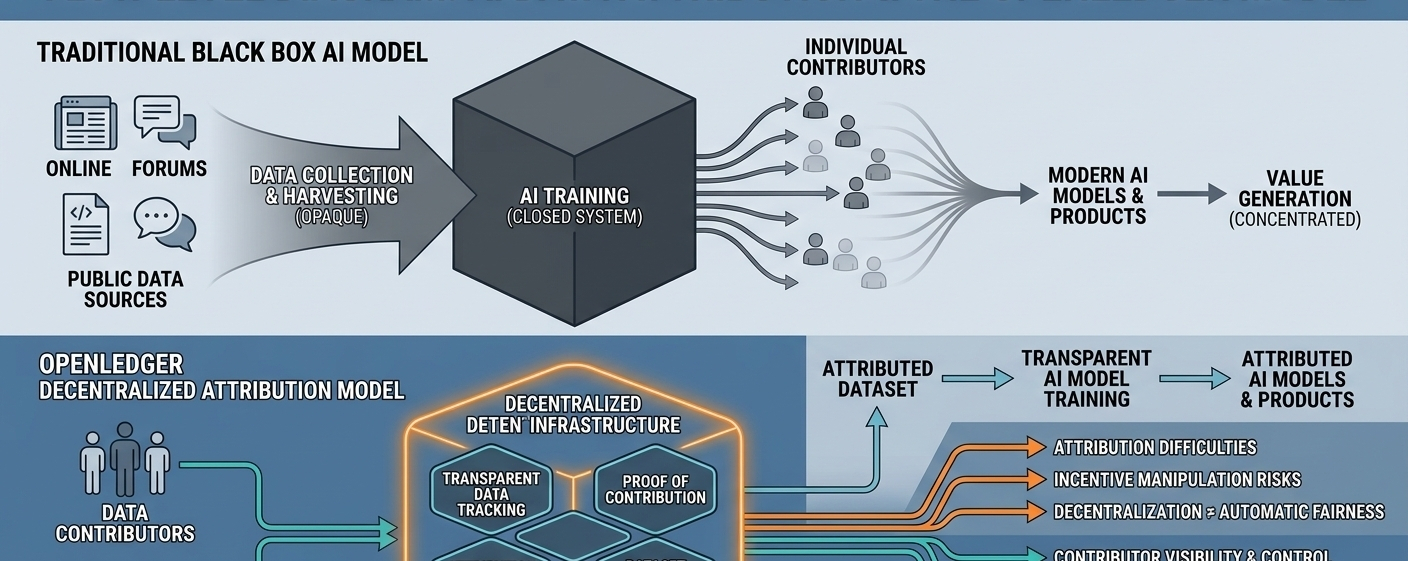
Vấn đề sâu xa hơn là các hệ thống AI hiện đại cực kỳ khó để truy vết. Khi dữ liệu vào một mạng nơ-ron, nó trở thành một phần của một cấu trúc lớn hơn nhiều mà ở đó thông tin hòa trộn lại với nhau. Khác với các cơ sở dữ liệu truyền thống, các mô hình AI không lưu trữ kiến thức trong các thư mục gọn gàng, rõ ràng. Chúng học các mẫu từ khối lượng lớn thông tin cùng một lúc. Điều đó làm cho việc xác định tập dữ liệu hoặc người đóng góp cụ thể nào đã ảnh hưởng đến một đầu ra cuối cùng trở nên khó khăn.
Các nỗ lực trước đây để giải quyết vấn đề này thường chỉ tập trung vào một phần của quy trình. Một số dự án đã thử nghiệm các hệ thống lưu trữ phi tập trung. Những dự án khác đã khám phá các thị trường AI dựa trên blockchain hoặc học tập liên kết. Các nhà nghiên cứu cũng đã thử nghiệm với việc đánh dấu bản quyền cho các tập dữ liệu và tạo ra các hệ thống đào tạo minh bạch. Nhưng hầu hết những ý tưởng này đã gặp khó khăn khi chuyển từ lý thuyết sang sử dụng thực tế. Thách thức kỹ thuật hóa ra lớn hơn nhiều so với mong đợi.
Đây là không gian mà OpenLedger đang cố gắng định vị bản thân. Thay vì xây dựng một chatbot AI khác hoặc cạnh tranh trực tiếp với các nhà cung cấp mô hình lớn, dự án tập trung vào hạ tầng xung quanh chính AI. Lập luận rộng hơn của nó rất đơn giản: nếu dữ liệu do con người tạo ra đóng vai trò quan trọng trong sự phát triển của AI, thì nên có những hệ thống tốt hơn để theo dõi các đóng góp và hiểu cách giá trị di chuyển qua mạng.
Một trong những ý tưởng chính đứng sau OpenLedger là cái gọi là “Chứng minh Quyền sở hữu.” Nói một cách đơn giản, đây là một nỗ lực để kết nối những người đóng góp dữ liệu với cách mà các hệ thống AI sử dụng thông tin sau này. Dự án muốn tạo ra một cấu trúc mà trong đó các tập dữ liệu, hoạt động của mô hình và đầu ra có thể được liên kết minh bạch hơn thay vì biến mất vào một chiếc hộp đen.
Ban đầu, ý tưởng này nghe có vẻ hợp lý vì các ngành kỹ thuật số khác đã dựa vào các hệ thống ghi nhận. Các nền tảng âm nhạc theo dõi lượt phát và tiền bản quyền. Các cộng đồng phần mềm giám sát các đóng góp mã. Các nhà sáng tạo nội dung trên các nền tảng xã hội ngày càng mong đợi các công cụ sở hữu và kiếm tiền. So với những ngành đó, AI vẫn hoạt động với các hệ thống ghi nhận đóng góp surprisingly yếu.
OpenLedger cũng giới thiệu khái niệm “Datanets,” được thiết kế như những môi trường có tổ chức để thu thập các tập dữ liệu chuyên biệt. Thay vì hoàn toàn phụ thuộc vào các nguồn dữ liệu tập trung lớn, dự án gợi ý rằng các cộng đồng và người đóng góp có thể xây dựng những hệ sinh thái dữ liệu tập trung hơn cho các ngành hoặc trường hợp sử dụng cụ thể.
Điều này quan trọng vì AI đang dần rời xa việc chỉ thu thập một khối lượng lớn nội dung trực tuyến chung. Các hệ thống AI chuyên biệt hiện cần thông tin chính xác và được tuyển chọn hơn. Các mô hình chăm sóc sức khỏe cần kiến thức y tế đáng tin cậy. Các hệ thống AI pháp lý phụ thuộc vào các tài liệu pháp lý có cấu trúc. Các công cụ AI doanh nghiệp thường cần dữ liệu hoạt động riêng tư. Trong những tình huống này, chất lượng quan trọng hơn số lượng.
Một phần thú vị khác của OpenLedger là sự tập trung vào việc ghi nhận trong quá trình suy diễn, không chỉ trong đào tạo. Hầu hết người dùng AI không bao giờ biết nguồn thông tin bên ngoài nào đã ảnh hưởng đến các câu trả lời mà họ nhận được. OpenLedger cố gắng làm cho những mối quan hệ đó trở nên rõ ràng hơn. Mục tiêu không chỉ là tính minh bạch, mà còn là khả năng những người đóng góp có thể cuối cùng hưởng lợi khi dữ liệu của họ được sử dụng tích cực.
Dự án cũng khám phá tính hiệu quả thông qua các hệ thống như OpenLoRA, tập trung vào các bộ chuyển đổi mô hình AI nhẹ thay vì đào tạo các mô hình riêng biệt lặp đi lặp lại. Tư duy đứng sau cách tiếp cận này rất thực tiễn. Hạ tầng AI đang trở nên ngày càng đắt đỏ, và các hệ thống mô-đun có thể cung cấp cách thức linh hoạt hơn để hỗ trợ các ứng dụng AI chuyên biệt mà không cần phải xây dựng lại mọi thứ từ đầu.
Tuy nhiên, vẫn có những giới hạn rõ ràng đối với tầm nhìn này. Việc ghi nhận trong các hệ thống AI vẫn là một trong những vấn đề kỹ thuật khó khăn nhất trong ngành. Mạng nơ-ron không hoạt động như các phương trình toán học đơn giản mà ở đó mỗi đầu ra có một nguồn gốc rõ ràng. Kiến thức bên trong những hệ thống này được phân phối qua hàng tỷ tham số, khiến việc ghi nhận hoàn hảo trở nên cực kỳ khó khăn.
Cũng có vấn đề về động lực. Bất kỳ mạng mở nào thưởng cho những đóng góp cuối cùng cũng phải đối mặt với spam, thao túng và các bài nộp chất lượng thấp. Một số người tham gia sẽ tự nhiên cố gắng khai thác hệ thống để nhận thưởng thay vì đóng góp dữ liệu có ý nghĩa. Duy trì chất lượng trong khi giữ cho việc tham gia mở là khó khăn hơn nhiều trong thực tế so với lý thuyết.
Quản trị tạo ra một thách thức khác. Nhiều dự án phi tập trung bắt đầu với những hứa hẹn về sự công bằng và tham gia cộng đồng, nhưng ảnh hưởng thường trở nên tập trung giữa những người bên trong ban đầu hoặc những người tham gia có kỹ thuật cao. OpenLedger có thể gặp phải những vấn đề tương tự theo thời gian vì các hệ thống phi tập trung không tự động loại bỏ các mất cân bằng quyền lực.
Các mối lo ngại về quyền riêng tư cũng vẫn chưa được giải quyết. Sự minh bạch hoàn toàn có thể nghe có vẻ hấp dẫn trong lý thuyết, nhưng nhiều tổ chức không thoải mái khi phải phơi bày dữ liệu đào tạo nhạy cảm hoặc quy trình nội bộ. Các ngành như tài chính, chăm sóc sức khỏe và an ninh doanh nghiệp thường ưu tiên quyền riêng tư và kiểm soát hoạt động hơn là sự cởi mở. Tìm kiếm sự cân bằng giữa tính minh bạch và bảo mật sẽ không dễ dàng.
Ngay cả khi có những lo ngại này, OpenLedger phản ánh một sự chuyển mình lớn hơn đang diễn ra trong ngành AI. Các cuộc trò chuyện đang dần chuyển từ hiệu suất mô hình đơn thuần sang những câu hỏi sâu hơn về quyền sở hữu, trách nhiệm và mối quan hệ dữ liệu. Khi hệ thống AI trở nên tích hợp hơn vào cuộc sống hàng ngày, những câu hỏi đó càng trở nên khó bị bỏ qua.
Những người có thể hưởng lợi nhiều nhất từ các hệ thống như vậy là những người đóng góp nhỏ hơn, hiện tại nhận được ít sự công nhận trong nền kinh tế AI. Các nhà nghiên cứu độc lập, cộng đồng ngách và các chuyên gia chuyên biệt thường tạo ra thông tin có giá trị mà không có bất kỳ khả năng nhìn thấy nào về cách công việc của họ được sử dụng sau này. Một lớp ghi nhận minh bạch có thể cho phép những người đóng góp đó tham gia nhiều hơn vào hệ sinh thái.
Cùng lúc đó, không có đảm bảo rằng hạ tầng phi tập trung tự động tạo ra sự công bằng. Những người tham gia có nguồn lực tốt hơn, tập dữ liệu lớn hơn hoặc kiến thức kỹ thuật mạnh mẽ có thể vẫn chiếm ưu thế trong hệ thống. Các mạng mở có thể phân phối quyền lực theo cách khác mà không nhất thiết tạo ra quyền truy cập bình đẳng cho tất cả mọi người tham gia.
Điều làm cho OpenLedger trở nên thú vị không phải là nó tuyên bố giải quyết mọi vấn đề xung quanh quyền sở hữu AI. Điểm quan trọng hơn là nó làm nổi bật một điểm yếu đã tồn tại dưới bề mặt của ngành. Các hệ thống AI hiện đại phụ thuộc rất nhiều vào kiến thức do con người tạo ra, tuy nhiên các cơ chế ghi nhận và tham gia vẫn cảm thấy chưa hoàn thiện.
Khi trí tuệ nhân tạo tiếp tục phát triển, cuộc tranh luận lớn nhất có thể cuối cùng sẽ chuyển khỏi việc công ty nào xây dựng mô hình thông minh nhất. Câu hỏi khó hơn có thể trở thành liệu những người đóng góp kiến thức cho các hệ thống này có còn ẩn danh hay không, hoặc liệu hạ tầng AI trong tương lai sẽ cuối cùng bắt đầu coi việc đóng góp dữ liệu là điều đáng được công nhận theo cách có ý nghĩa.
