
Vài năm trước, internet cảm giác như một thư viện vô tận cho AI.
Cần kiến thức? Thu thập thêm nhiều website. Tập hợp thêm văn bản. Đào tạo các mô hình lớn hơn.
Công thức đã hoạt động, cho đến khi những vết nứt bắt đầu xuất hiện.
Khi AI trở nên phổ biến, web từ từ thay đổi. Nội dung kém chất lượng tăng lên. Thông tin được tạo ra bởi AI bắt đầu nuôi dưỡng các hệ thống AI khác. Âm thanh hỗn loạn gia tăng. Độ tin cậy trở nên khó đo lường.
Bỗng nhiên, nhiều dữ liệu không còn có nghĩa là trí tuệ tốt hơn.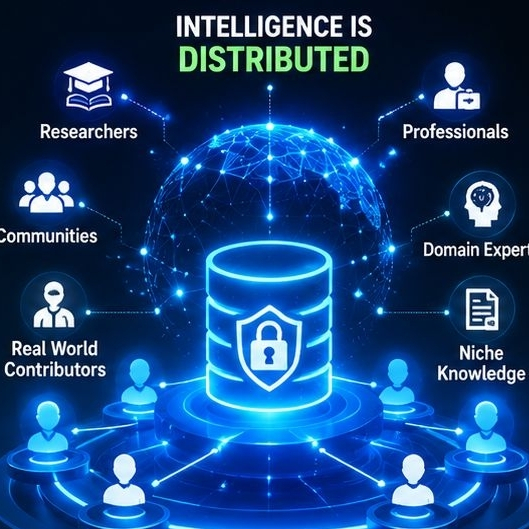
Đó là nơi cuộc trò chuyện xung quanh dữ liệu AI phân quyền bắt đầu.
Không phải vì phân quyền nghe có vẻ thú vị, mà vì trí tuệ ngày càng phụ thuộc vào kiến thức con người đáng tin cậy và chuyên biệt.
Mô hình cũ giả định rằng một vài nền tảng tập trung có thể thu thập và kiểm soát hầu hết dữ liệu hữu ích. Nhưng chuyên môn không chỉ tồn tại ở một nơi. Nó hiện diện trong các cộng đồng, ngành công nghiệp, nhà nghiên cứu, chuyên gia ngách, và những người đóng góp thực tế ở khắp nơi.
Câu hỏi trở nên khó để bỏ qua:
Làm sao bạn tổ chức thông tin con người giá trị mà không hoàn toàn phụ thuộc vào các hệ thống khép kín?
Đó là lý do tại sao dữ liệu AI phân quyền lại quan trọng.
Mục tiêu không chỉ là thu thập thêm thông tin. Nó là tạo ra các hệ thống mà dữ liệu tốt hơn trở nên dễ dàng để tìm kiếm, tổ chức và duy trì thông qua sự tham gia phân tán.
Tất nhiên, phân quyền mang lại những vấn đề của riêng nó. Kiểm soát chất lượng trở nên khó khăn hơn. Sự phối hợp trở nên lộn xộn.
Vẫn vậy, nếu AI tương lai phụ thuộc vào chuyên môn đáng tin cậy thay vì tiếng ồn trên internet, các hệ thống quản lý dữ liệu có thể âm thầm trở nên quan trọng không kém gì các mô hình chính nó.
