OpenLedger is one of those projects where I do not want to rush into the usual clean narrative.
I’ve seen too many of those already.
AI layer. Data economy. Better models. On-chain intelligence. Same words, recycled until they lose weight. Most projects enter this lane with a nice diagram, a few big claims, and then slowly disappear into the same noise they were trying to rise above.
So with OpenLedger, I’m not looking for the pretty version.
I’m looking for the part that survives the grind.
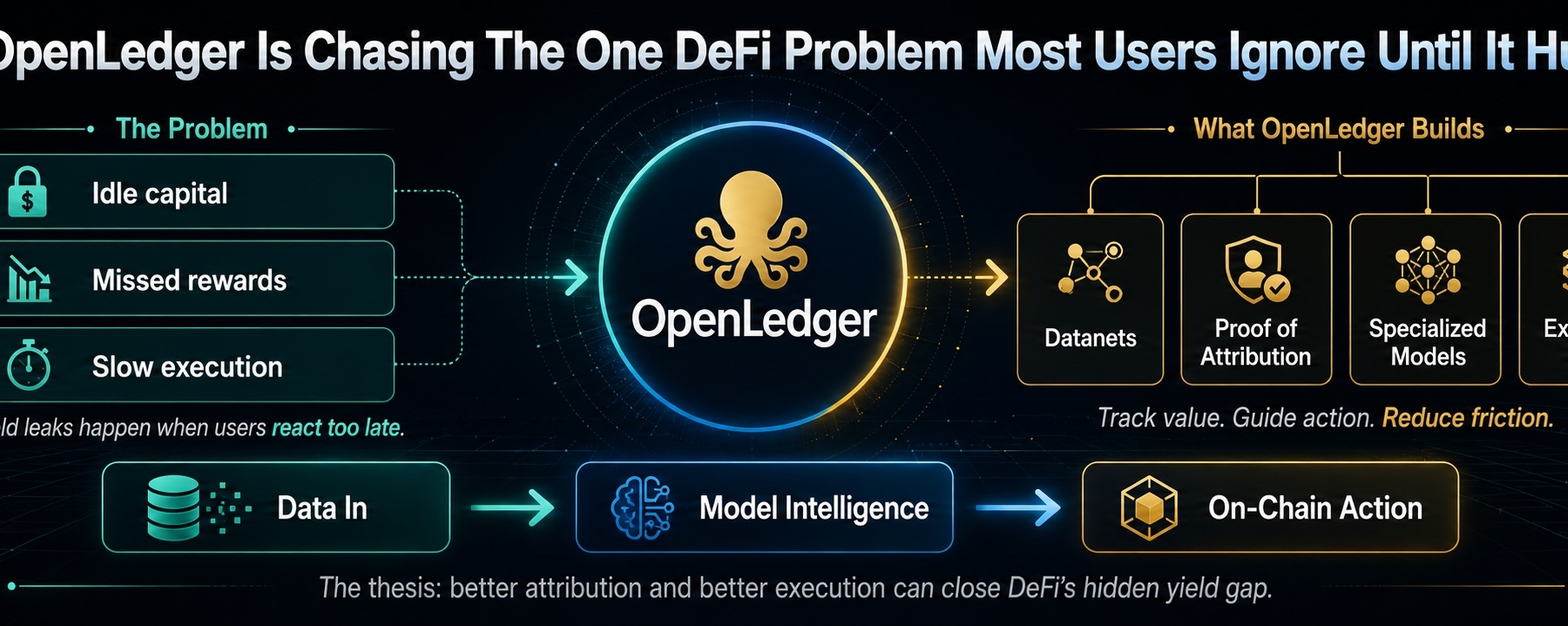
And honestly, the part that still feels worth watching is simple: OpenLedger is trying to deal with the gap between data, AI output, and actual value. Not in a vague “AI will change crypto” way. More like, who contributed the data, who benefits from it, what did the model actually produce, and can any of that be tracked without turning into another black box?
That matters.
Because right now, most AI systems eat data like it came from nowhere. People contribute. Communities produce value. Models improve. Then the credit disappears somewhere inside the machine.
OpenLedger is trying to make that loop more visible.
Data comes in.
Models use it.
Outputs are created.
Value should be traced back.
Simple idea. Hard execution.
That is usually where projects break.
I like the direction, but I’m not going to pretend this is easy. Attribution sounds clean when you write it down. In the real world, data quality is messy, incentives get gamed, contributors chase rewards, and builders only care if the infrastructure saves them time or makes them money.
That is the friction.
OpenLedger can have Datanets, Proof of Attribution, specialized models, and all the right architecture, but the market will still ask the same brutal question: does this actually get used?
Not talked about.
Used.
There is a difference.
The DeFi angle makes the project more interesting because yield leakage is real. I’ve watched this happen for years. People do not always lose money because they are stupid. They lose edge because they are tired. They miss rotations. They forget rewards. They stay in dead pools too long. They chase a number that looked good yesterday but is already drained today.
That is DeFi.
A constant grind.
Too many dashboards. Too many chains. Too many pools. Too much noise pretending to be opportunity.
OpenLedger fits into this problem if its intelligence layer can help users act better, not just read better. DeFi does not need more explanations. It needs cleaner execution. It needs systems that can understand timing, risk, capital movement, and user intent without making everything feel heavier than it already is.
But here’s the thing.
AI that only suggests is easy.
AI that touches execution is a different beast.
Once a model starts influencing real on-chain action, every mistake becomes expensive. Bad routing. Poor timing. Weak risk checks. Wrong assumptions. Delayed response. One small failure and users stop trusting the system.
That is why OpenLedger’s attribution side matters more than people think.
If an AI output affects a decision, I want to know where it came from. What data shaped it. What model produced it. Why the action made sense at that moment. If none of that is visible, then we are just back to trusting a shiny black box with a crypto label on it.
And I’m tired of black boxes.
OpenLedger’s stronger idea is not that AI can exist on-chain. Everyone is saying some version of that now. The stronger idea is that AI value should be traceable. Data should not vanish. Contribution should not be invisible. Outputs should not float around without context.
That is a real problem.
Still, a real problem does not automatically make a winning project.
The real test, though, is whether OpenLedger can make all of this feel useful without making users feel like they need to study the whole system first. Most people do not care about infrastructure until it starts removing pain from their day.
Can it help builders create better specialized models?
Can it make data contribution feel worth it?
Can it create outputs that people trust?
Can it connect AI with DeFi execution in a way that feels safe, not chaotic?
That is what I’m watching.
Not the slogan.
Not the category.
Not the polished thread.
The moment this actually breaks into usage.
Because OpenLedger is sitting in a serious lane. Data ownership, AI attribution, model specialization, DeFi execution — these are not small things. They are heavy pieces. Useful pieces, maybe. But heavy.
And heavy infrastructure takes time.
It does not pump just because the idea sounds good. It has to earn relevance slowly. Through builders. Through integrations. Through users who come back because the system actually helped them, not because the market was bored and needed a new AI name for the week.
That is where I still have my doubts.
Not about the concept.
The concept makes sense.
My doubt is around the usual crypto problem: can the project turn a smart structure into something people actually depend on?
Because if OpenLedger can do that, the yield leak angle becomes only the first visible use case. The bigger play is attribution and execution. A system where intelligence is not just produced, but tracked, verified, and used in a way that creates real value.
That is a much better story than “AI plus crypto.”
But it has to prove itself in the mud.
The market is exhausted. Users are exhausted. Builders are exhausted. Everyone has heard big promises before. Nobody wants another clean pitch deck with no weight behind it.
OpenLedger has the right problem in front of it.