Tôi đã làm việc cho AI nhiều năm mà không nhận được một xu nào.
Mỗi lần tìm kiếm, mỗi cú click, mỗi giây thêm trên một trang đều trở thành dữ liệu huấn luyện cho mô hình của người khác. Không thông báo. Không thanh toán. Chỉ là điều khoản dịch vụ mà không ai đọc.
Không ai gọi đó là khai thác vì sản phẩm vẫn cảm thấy miễn phí.
Đối với các trader, mọi thứ còn sâu hơn nữa. Luồng lệnh, thời điểm vào lệnh, mô hình kích thước — những thứ mất nhiều năm để phát triển — có thể âm thầm trở thành dữ liệu huấn luyện hành vi ngay khi chúng đi qua một nền tảng có lớp AI phía dưới.
OpenLedger đang cố gắng xây dựng một mô hình khác.
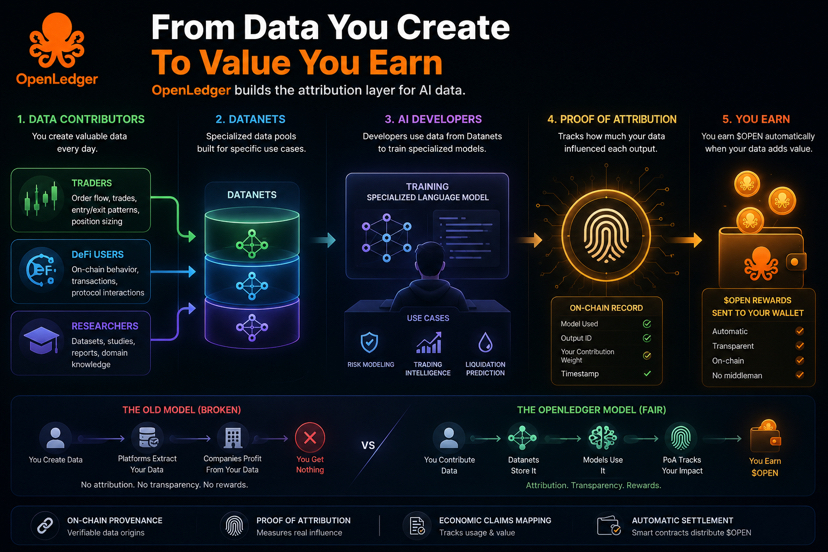
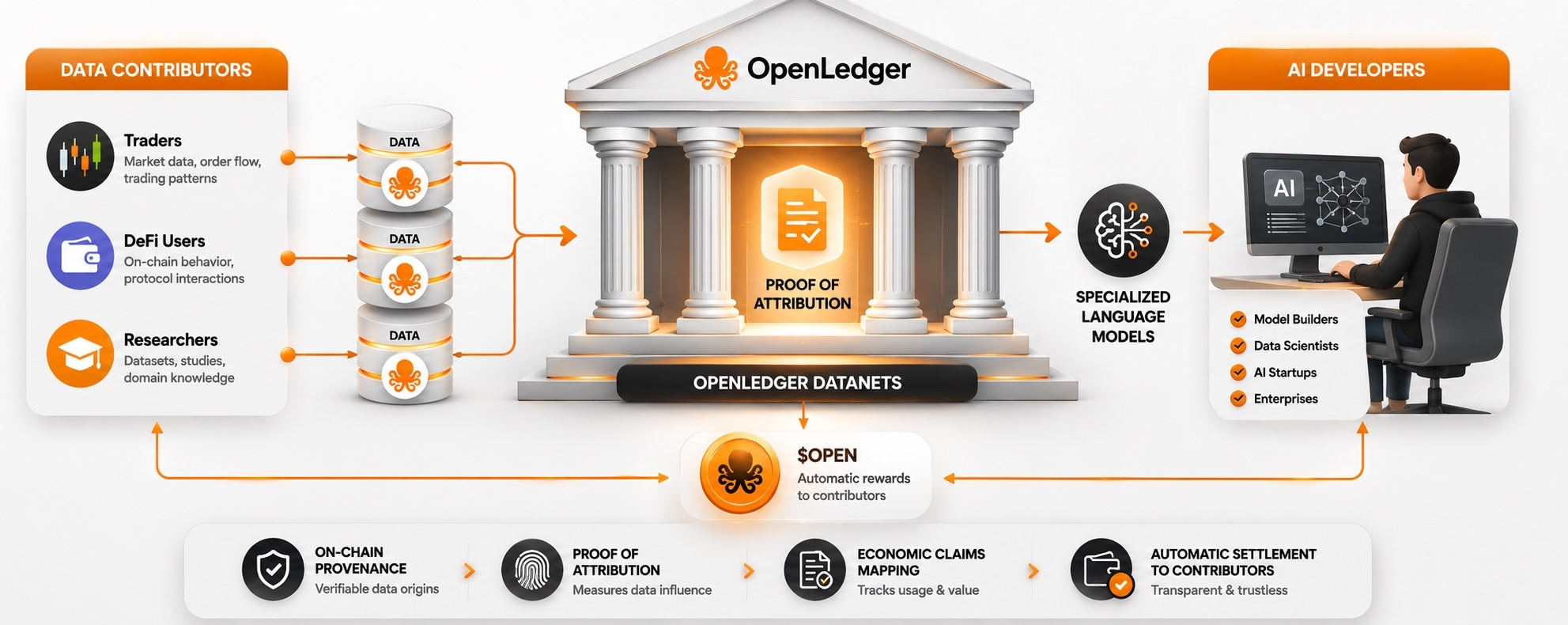
Thay vì các nền tảng thu thập dữ liệu sau cánh cửa đóng kín, họ đã xây dựng Datanets — các hồ dữ liệu chuyên biệt nơi những người đóng góp tải lên thông tin một cách có chủ ý. Hành vi giao dịch DeFi. Lịch sử thanh lý. Mô hình tỷ lệ tài trợ trên các nền tảng. Bất kỳ bộ dữ liệu nào hữu ích cho việc đào tạo các mô hình AI theo miền cụ thể.
Các nhà phát triển rút ra từ những nguồn đó để đào tạo các Mô hình Ngôn ngữ Chuyên biệt cho các trường hợp sử dụng cụ thể. Khi các mô hình đó tạo ra đầu ra sử dụng dữ liệu được đóng góp, Proof of Attribution theo dõi ảnh hưởng trên chuỗi và OPEN được phân phối tự động cho những người đóng góp. Không có quy trình thanh toán thủ công. Không có chia sẻ doanh thu mờ ám. Hợp đồng thông minh xử lý việc ghi nhận và thanh toán trực tiếp.
Thiết kế kỹ thuật của PoA thú vị hơn cả phần thưởng bản thân.
Nó không hoạt động trên hệ thống đơn giản tải lên-nhiều-kiếm-nhiều. Nó đo lường trọng số đóng góp, không phải khối lượng đóng góp. Một bộ dữ liệu nhỏ hơn mà liên tục định hình hành vi của mô hình có thể kiếm được nhiều hơn một bộ dữ liệu khổng lồ mà chỉ thay đổi đầu ra một chút. Những người đóng góp không chỉ cung cấp đầu vào thô. Họ đang giữ một mức độ rủi ro kinh tế đối với chính hiệu suất của mô hình.
Đó là phần đã thu hút sự chú ý của tôi. Không phải token. Mà là cơ chế.
Hầu hết các dự án AI trong crypto chỉ dừng lại ở lớp quan sát — bảng điều khiển, công cụ cảm xúc, hệ thống cho người dùng biết nên nhìn vào đâu. OpenLedger đang cố gắng hoạt động sâu hơn trong ngăn xếp: lớp hạ tầng nơi dữ liệu được thu thập, xác minh, ghi nhận và biến đổi thành thứ mà các mô hình thực sự có thể học hỏi.
Công việc hạ tầng thường bị bỏ qua vì nó trông nhàm chán ở giai đoạn đầu. Cho đến khi toàn bộ ngăn xếp phụ thuộc vào nó.
Nhưng câu hỏi thực sự không phải là ghi nhận. Đó là kiểm soát chất lượng.
PoA có thể theo dõi xem dữ liệu có ảnh hưởng đến đầu ra của mô hình hay không. Điều đó không có nghĩa là dữ liệu đó hữu ích, chính xác hoặc sạch sẽ. Động lực cho những người đóng góp vẫn là tài chính, và động lực tài chính thường tối ưu cho quy mô trước khi chất lượng. Một Datanet mở không có sự quản lý mạnh mẽ sẽ nhanh chóng đầy tiếng ồn. Và một mô hình chuyên biệt được đào tạo trên dữ liệu ô nhiễm không trở nên thông minh. Nó trở nên tự tin mà hẹp hòi.
Đó là phần mà tôi vẫn đang theo dõi cẩn thận.
Không phải là whitepaper. Không phải công bố hợp tác. Môi trường sản xuất sau khi các nhà phát triển thực sự bắt đầu xây dựng trên các Datanets thực tế ở quy mô lớn. Đó là lúc chúng ta tìm ra liệu các cơ chế lọc có đủ mạnh để duy trì chất lượng tín hiệu theo thời gian hay không.
Hành vi của các nhà phát triển sau khi phát hành Studio sẽ tiết lộ nhiều hơn bất kỳ phân tích tokenomics nào có thể.
Nhưng bất kể OpenLedger có thành công hay không, vấn đề cơ bản sẽ không biến mất.
Hiện tại, nền kinh tế AI vận hành dựa trên một mô hình: người dùng tạo ra dữ liệu, các nền tảng thu thập dữ liệu đó, các công ty kiếm tiền từ nó, những người đóng góp không nhận được gì. Đó là thỏa thuận mặc định của internet trong nhiều thập kỷ vì chưa bao giờ có một lựa chọn khả thi nào khác.
Nếu Proof of Attribution thực sự hoạt động ở quy mô — nơi những người đóng góp nhận được giá trị tương ứng với việc dữ liệu của họ định hình đầu ra của một mô hình, mà không có một bên trung gian tập trung quyết định sự chia sẻ — thì kinh tế của AI bắt đầu thay đổi theo một cách có ý nghĩa. Không chỉ cho crypto. Mà cho toàn bộ mối quan hệ giữa các nền tảng, mô hình và những người tạo ra trí thông minh cơ bản mà các hệ thống đó phụ thuộc vào.
Tôi không biết liệu OPEN cuối cùng có trở thành dự án giải quyết vấn đề này hay không.
Hạ tầng là có thật. Kiến trúc thì đầy tham vọng. Ngành công nghiệp rõ ràng cần một câu trả lời tốt hơn cho quyền sở hữu dữ liệu hơn là cái mà nó có hôm nay. Nhưng khoảng cách giữa một cơ chế hoạt động và một hệ sinh thái bền vững là nơi mà hầu hết các dự án thất bại.
Vẫn đáng để theo dõi.
Không phải vì hành động giá cả.
Bởi vì nếu mô hình này hoạt động, dữ liệu không còn là thứ tiêu hao mà bắt đầu trở thành tài sản.