
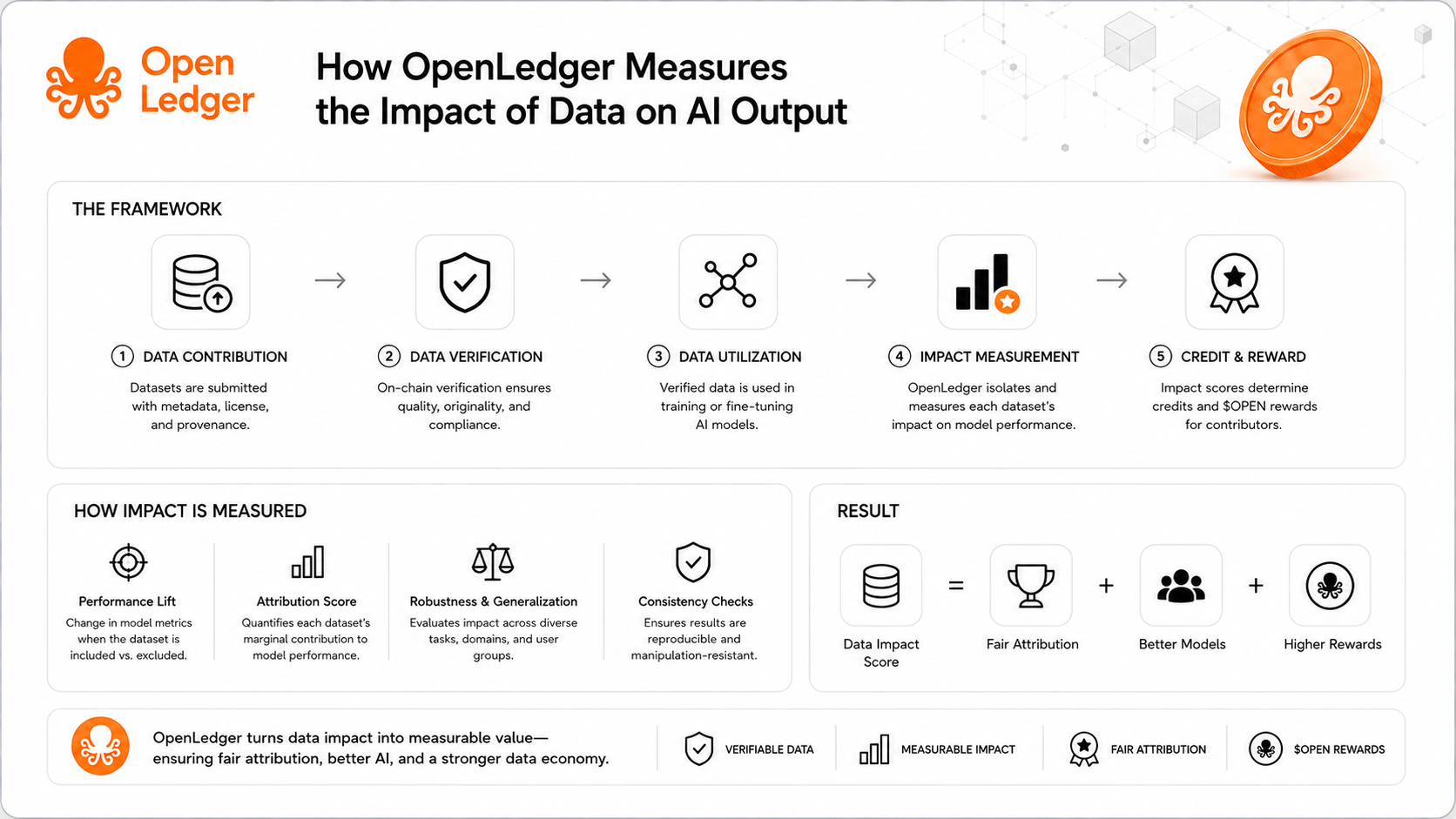
Mình nghĩ phần đáng quan sát nhất ở OpenLedger $OPEN không chỉ là dự án nói về AI hay dữ liệu.
Mà là một câu hỏi khó hơn nhiều:
Làm sao biết dữ liệu nào thật sự ảnh hưởng đến output của AI?
Và reward có được chia đúng cho người đóng góp hay không?
Đây mới là điểm quyết định Proof of Attribution có giá trị thật hay chỉ dừng ở một ý tưởng nghe hợp lý.
Trong AI, việc đo “dataset nào tạo ra ảnh hưởng bao nhiêu” không hề đơn giản.
Nghe qua thì có vẻ chỉ cần xem model đã dùng dữ liệu nào để train, rồi chia reward theo phần đóng góp.
Nhưng thực tế phức tạp hơn nhiều.
Một bộ dữ liệu nhỏ vẫn có thể cực kỳ quan trọng nếu nó chứa thông tin hiếm.
Ngược lại, một bộ dữ liệu rất lớn có thể không tạo thêm nhiều giá trị nếu phần lớn thông tin trong đó đã bị trùng với dữ liệu khác.
Đây là lý do mình thấy bài toán attribution trong AI khó hơn nhiều so với việc ghi nhận giao dịch thông thường trên blockchain.
Cách chính xác nhất về mặt lý thuyết là thử train model nhiều lần.
Một lần dùng đầy đủ dữ liệu.
Một lần bỏ từng dataset ra.
Rồi so sánh kết quả.
Nếu bỏ một dataset mà model kém đi rõ rệt, có thể nói dataset đó có ảnh hưởng lớn.
Nhưng cách này gần như không thực tế với model lớn.
Chi phí train quá cao.
Thời gian quá dài.
Và nếu có hàng nghìn hoặc hàng triệu điểm dữ liệu thì không thể lặp lại quy trình đó mãi.
Các phương pháp khác như Shapley value hay Influence Function có thể giúp ước lượng ảnh hưởng của dữ liệu.
Nhưng chúng cũng có trade-off riêng.
Có cách thì quá đắt.
Có cách thì thiếu ổn định.
Có cách hoạt động tốt trong nghiên cứu nhỏ nhưng khó scale lên môi trường production.
Nói đơn giản, hiện tại chưa có phương pháp nào vừa rẻ, vừa chính xác, vừa mở rộng tốt cho mọi mô hình AI lớn.
Vì vậy, khi nhìn vào OpenLedger, mình không kỳ vọng Proof of Attribution phải giải được bài toán này một cách hoàn hảo ngay từ đầu.
Điều mình quan tâm hơn là dự án đang chọn hướng tiếp cận nào.
Theo cách mình hiểu, OpenLedger $OPEN không cố đo ảnh hưởng dữ liệu theo kiểu tuyệt đối.
Dự án tập trung nhiều hơn vào việc ghi nhận lineage.
Tức là theo dõi dữ liệu nào được dùng trong quá trình training.
Dữ liệu đến từ Datanet nào.
Được sử dụng trong bước nào.
Và có vai trò ra sao trong pipeline tạo ra model.
Cách này thực tế hơn.
Thay vì phải tính lại từ đầu mỗi khi model chạy inference, hệ thống có thể dùng lịch sử sử dụng dữ liệu trong quá trình huấn luyện như một tín hiệu để phân bổ reward.
Nó không hoàn hảo.
Nhưng có thể chạy được ở quy mô lớn hơn.
Và trong thế giới hạ tầng, một cơ chế đủ tốt nhưng vận hành được đôi khi quan trọng hơn một cơ chế rất đẹp trên lý thuyết nhưng không thể triển khai.
Điểm đáng nói là blockchain trong trường hợp này không chỉ dùng để thanh toán.
Nó trở thành lớp ghi nhận đóng góp.
Nếu dữ liệu được đưa vào Datanets, được dùng để fine-tune hoặc hỗ trợ model tạo ra giá trị, Proof of Attribution có thể giúp lưu lại dấu vết đó rõ ràng hơn.
Người đóng góp dữ liệu ít nhất có cơ sở để biết dữ liệu của mình không biến mất trong một chiếc hộp đen AI.
Nhưng mình cũng nghĩ đây là phần OpenLedger sẽ bị thử thách mạnh nhất.
Nếu reward chỉ dựa quá nhiều vào “dữ liệu được dùng bao nhiêu”, hệ thống có thể gặp vấn đề.
Người đóng góp có thể tìm cách đưa thật nhiều dữ liệu vào để tăng tỷ trọng, thay vì tập trung vào chất lượng.
Một dataset lớn nhưng nhiễu có thể được thưởng nhiều hơn một dataset nhỏ nhưng rất giá trị.
Nếu chuyện đó xảy ra, incentive sẽ lệch.
Mình lấy ví dụ đơn giản.
Một bộ dữ liệu y tế nhỏ về một loại bệnh hiếm có thể chỉ chiếm tỷ trọng rất thấp trong toàn bộ quá trình training.
Nhưng khi model cần trả lời đúng về chính bệnh đó, bộ dữ liệu nhỏ này lại có ảnh hưởng rất lớn.
Nếu cơ chế attribution không nhìn ra điều này, người đóng góp dữ liệu hiếm sẽ bị trả thưởng thấp hơn giá trị thật họ tạo ra.
Ngược lại, một dataset lớn nhưng toàn thông tin phổ biến có thể không giúp model cải thiện nhiều.
Vì những gì nó cung cấp đã xuất hiện ở nhiều nguồn khác.
Nếu hệ thống vẫn thưởng cao chỉ vì nó lớn, đó là tín hiệu không tốt cho thị trường dữ liệu.
Theo mình, hướng hợp lý hơn là OpenLedger cần kết hợp nhiều lớp tín hiệu.
Lineage tracking là nền tảng cần thiết, nhưng có thể chưa đủ.
Hệ thống nên có thêm các tín hiệu liên quan đến chất lượng model.
Độ cải thiện performance trên từng domain.
Mức độ độc đáo của dữ liệu.
Và khả năng dữ liệu đó giúp model xử lý tốt hơn trong những trường hợp cụ thể.
Nói cách khác, attribution không nên chỉ hỏi:
“Dataset này được dùng bao nhiêu?”
Mà nên hỏi thêm:
“Dataset này giúp model tốt hơn ở đâu?”
Đây là điểm rất quan trọng nếu OpenLedger muốn thu hút dữ liệu chuyên ngành thật sự chất lượng.
Người có dữ liệu tốt sẽ không muốn tham gia nếu họ cảm thấy dữ liệu của mình bị đánh đồng với dữ liệu số lượng lớn nhưng giá trị thấp.
Một thị trường dữ liệu bền vững cần reward đúng người đóng góp đúng giá trị.
Ít nhất là đủ gần với giá trị thật để tạo động lực dài hạn.
Mình không nghĩ Proof of Attribution cần chính xác tuyệt đối mới có ý nghĩa.
Trong thực tế, chỉ cần nó tốt hơn mô hình hiện tại là đã đáng chú ý.
Hiện tại, nhiều người tạo dữ liệu gần như không được ghi nhận gì.
Dữ liệu đi vào model.
Model tạo ra giá trị.
Còn người đóng góp ban đầu bị tách khỏi toàn bộ phần upside phía sau.
Nếu OpenLedger giúp dữ liệu được truy vết rõ hơn, đóng góp được đo lường tốt hơn, và reward được phân phối công bằng hơn so với hiện tại, đó đã là một bước tiến.
Tuy nhiên, mình sẽ không đánh giá Proof of Attribution chỉ bằng mô tả trong tài liệu hay narrative AI x blockchain.
Thứ mình muốn nhìn thấy là dữ liệu production dài hạn.
Dữ liệu chất lượng cao có thật sự nhận reward tốt hơn dữ liệu kém không?
Contributor có tiếp tục đóng góp sau khi thấy cơ chế phân phối hoạt động không?
Model được train từ Datanets có tạo ra giá trị thực tế đủ rõ không?
Đó mới là bài test thật.
Với mình, OpenLedger đang đi vào một vấn đề rất đúng của AI:
Giá trị của dữ liệu cần được ghi nhận tốt hơn.
Nhưng phần khó nhất vẫn nằm ở cách đo giá trị đó.
Nếu Proof of Attribution đủ chính xác để tạo incentive đúng hướng, OpenLedger sẽ có một lợi thế rất đáng chú ý.
Còn nếu attribution bị lệch, toàn bộ mô hình reward phía sau cũng sẽ bị lệch theo.
Đây là lý do mình vẫn theo dõi OpenLedger không phải vì tokenomics hay số liệu bề mặt.
Mà vì cơ chế attribution này có thể chứng minh được trong thực tế hay không.
@OpenLedger #OpenLedger $OPEN