Nhiều năm nghiên cứu mà tôi tưởng là vô ích. Hóa ra chúng không phải vậy.
Tôi có một thư mục trên máy tính gọi là “nghiên cứu cũ.”
Bên trong có hàng trăm tập tin: dữ liệu on-chain, phân tích phân phối token, mẫu hành vi ví cá voi, ghi chú từ những đêm ngồi xem mempool đến 2 giờ sáng. Hầu hết chưa bao giờ được sử dụng lại. Một số tập tin tôi tưởng sẽ nằm đó mãi mãi.
Tôi chưa bao giờ nghĩ chúng có giá trị với ai ngoài tôi.
Cho đến khi tôi đọc một phần của Đạo luật AI EU tháng trước.
Có một chi tiết mà tôi nghĩ hầu hết thị trường đang đánh giá thấp: các công ty triển khai AI sẽ ngày càng cần phải chứng minh nguồn gốc dữ liệu — dữ liệu nào tạo ra đầu ra nào, ai đã đóng góp, ai đã đồng ý sử dụng, có thể kiểm toán và xác minh ở mọi bước.
Tôi ngồi đó đọc và tự hỏi mình:
Có bao nhiêu hệ thống AI ngày nay thực sự có thể làm điều đó?
Hầu như không có gì.
Đó là lúc tôi nhìn thư mục “nghiên cứu cũ” của mình theo một cách hoàn toàn khác.
Bởi vì tôi nhận ra: đây chính là những gì các mô hình AI cần — và ngay bây giờ gần như không có thị trường hợp pháp, minh bạch, có thể xác minh để giao dịch nó.
Dữ liệu hành vi crypto chất lượng cao không nằm trong các bản quét Twitter hay số liệu khám phá khối thô.
Nó sống trong bối cảnh.
Trong những người đã dành nhiều năm để hiểu cấu trúc thị trường, hành vi thanh khoản, chu kỳ hoảng loạn, và các mẫu phối hợp giữa tiền thông minh.
Những gì tôi có không phải được xây dựng bởi một script chạy qua đêm. Nó được xây dựng bằng thời gian.
Và ngay bây giờ, hầu hết loại dữ liệu đó đang nằm chết trên các ổ cứng cá nhân trên toàn thế giới.
Đây là nơi tôi nghĩ hầu hết crypto đang đọc sai câu chuyện AI.
Mọi người đang tranh cãi về mô hình nào thông minh hơn. Nhưng các mô hình đang bị hàng hóa hóa nhanh hơn hầu hết mọi người nghĩ. Mã nguồn mở đang thu hẹp khoảng cách giữa các hệ thống rất nhanh. Tính toán cuối cùng sẽ trở thành thứ mà bất kỳ ai có tiền đều có thể mua.
Nhưng dữ liệu chất lượng cao với nguồn gốc rõ ràng sẽ không như vậy.
Và quy định sẽ khiến nó trở nên khan hiếm hơn.
Đạo luật AI của EU không phải là điểm kết thúc. Nó là khởi đầu của một giai đoạn mà các công ty AI bị buộc phải trả lời: dữ liệu này đến từ đâu, và ai đã đồng ý cho bạn sử dụng nó?
Câu hỏi đó sẽ phá vỡ nhiều mô hình kinh doanh AI hiện tại.
Đó là lúc OpenLedger bắt đầu trở nên thú vị với tôi.
Lúc đầu tôi đã hoài nghi theo phản xạ — AI x blockchain, câu chuyện quen thuộc, bộ bài đẹp. Nhưng khi tôi đặt nó vào bối cảnh quy định ở trên, logic bắt đầu thay đổi.
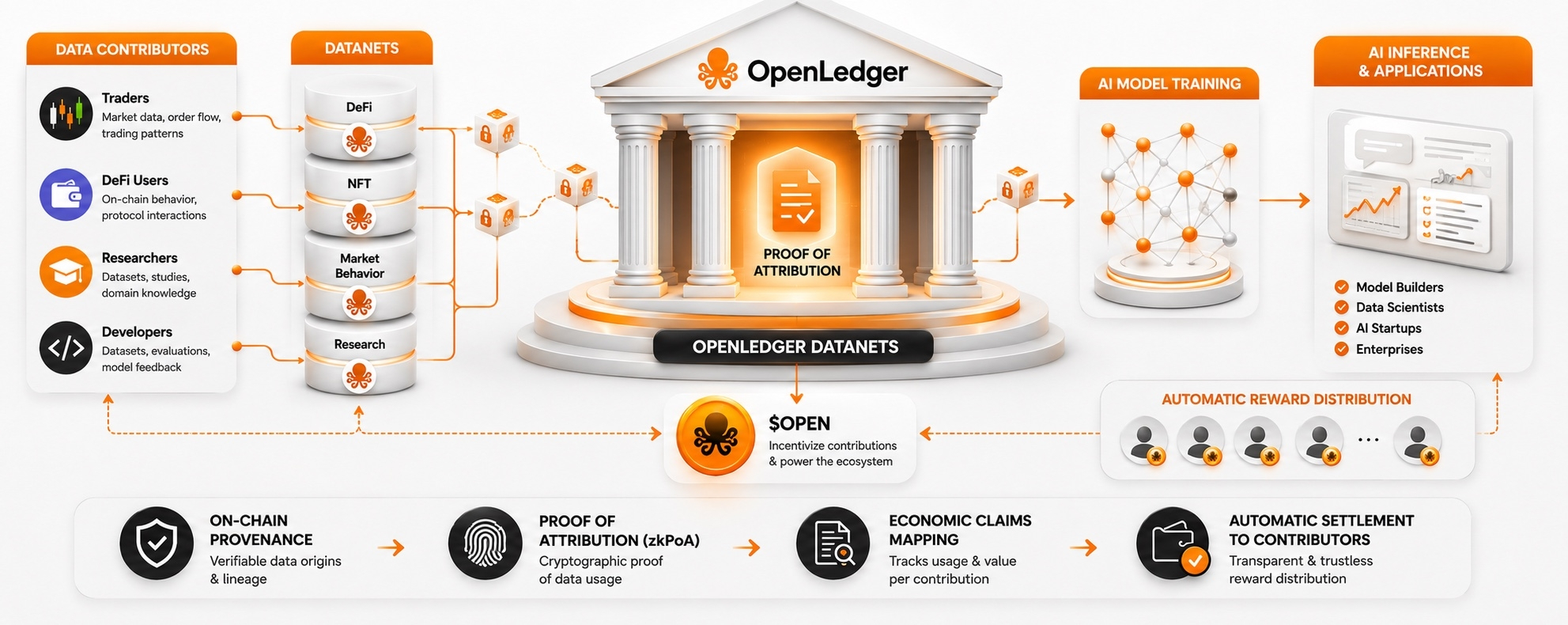
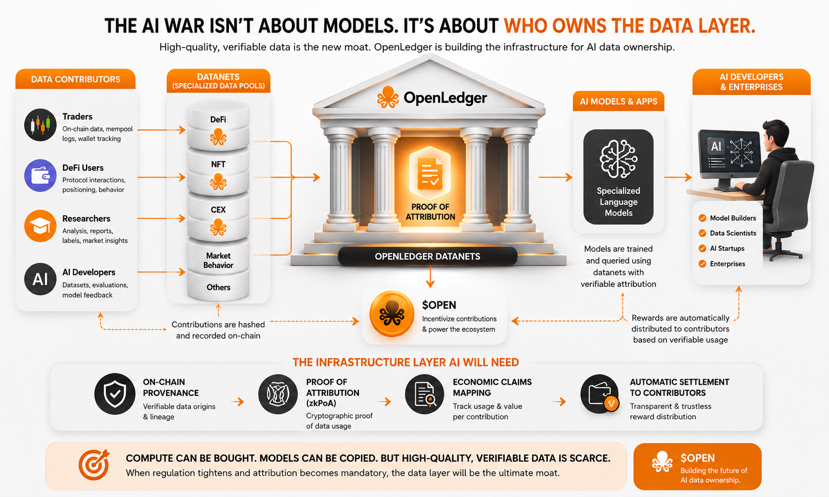
Proof of Attribution về cơ bản biến các đóng góp dữ liệu thành thứ có thể xác minh, kiểm toán, và theo dõi trên chuỗi.
Cụ thể hơn: dữ liệu được đóng góp vào Datanets — các bể dữ liệu theo miền cụ thể, nơi mỗi đóng góp được băm và ghi lại trên chuỗi. Khi một mô hình được đào tạo và truy vấn, hệ thống truy tìm lại dấu vết xác thực và tự động phân phối phần thưởng cho các đóng góp viên đúng.
Nghe có vẻ đơn giản. Nhưng vấn đề thực sự là: trong một mô hình với hàng tỷ tham số, dữ liệu không được lưu trữ dưới dạng file — nó được học và phân phối qua các lớp. Không có cách nào rõ ràng để biết một tập dữ liệu nào đã ảnh hưởng đến đầu ra nào.
OpenLedger đang giải quyết vấn đề này với zkPoA — Zero-Knowledge Proof of Attribution. Các đóng góp viên có thể chứng minh dữ liệu của họ đã được sử dụng mà không cần tiết lộ toàn bộ lịch sử đào tạo. Di động qua các chuỗi, có thể xác minh mà không cần phát lại toàn bộ lịch sử.
Tôi không biết liệu nó có hoạt động hoàn hảo ở quy mô lớn hay không. Không ai đã giải quyết được điều đó. Nhưng đây là lần đầu tiên tôi thấy ai đó cố gắng giải quyết vấn đề đúng — thay vì chỉ nói về nó.
Nếu điều này hoạt động ở quy mô lớn: các file trong thư mục “nghiên cứu cũ” của tôi không còn là những ghi chú vô dụng.
Chúng trở thành tài sản.
Không phải vì câu chuyện. Mà vì lần đầu tiên tôi thấy blockchain giải quyết một vấn đề sở hữu và tuân thủ mà AI thực sự sẽ phải đối mặt.
Trong lịch sử công nghệ, lớp chiến thắng hiếm khi là lớp hào nhoáng nhất.
TCP/IP không sexy. AWS S3 cũng không sexy.
Cho đến khi mọi thứ bắt đầu chạy trên chúng.
Cơ sở hạ tầng xác thực dữ liệu có thể giống nhau. Không ai nói nhiều về nó — cho đến ngày AI không thể triển khai hợp pháp mà không có nó.
Tôi không biết liệu OpenLedger sẽ là người chiến thắng cuối cùng. Nhưng tôi khá chắc chắn rằng trận chiến thực sự của nền kinh tế AI sẽ diễn ra ở lớp dữ liệu — không phải lớp mô hình.
Và lần đầu tiên sau nhiều năm, thư mục “nghiên cứu cũ” trên máy tính của tôi bắt đầu trông giống như một tài sản hơn là một đống file bị lãng quên.
$OPEN xung quanh $0.18. Không phải lời khuyên tài chính. Chỉ là góc nhìn của một người vừa nhận ra rằng nhiều năm nghiên cứu có thể không bao giờ là vô dụng.
