
I keep coming back to the same thought when I look at OpenLedger most of what powers modern AI is still invisible, and that invisibility is not accidental—it’s structural.
Every time I use or observe an AI system, I can’t help noticing how clean the output feels compared to the messy reality underneath it. There’s this vast pipeline of scraped text, curated datasets, human labeling, model tuning, reinforcement signals, and feedback loops. It all gets compressed into something that looks effortless. But the effort never disappears; it just moves out of sight.
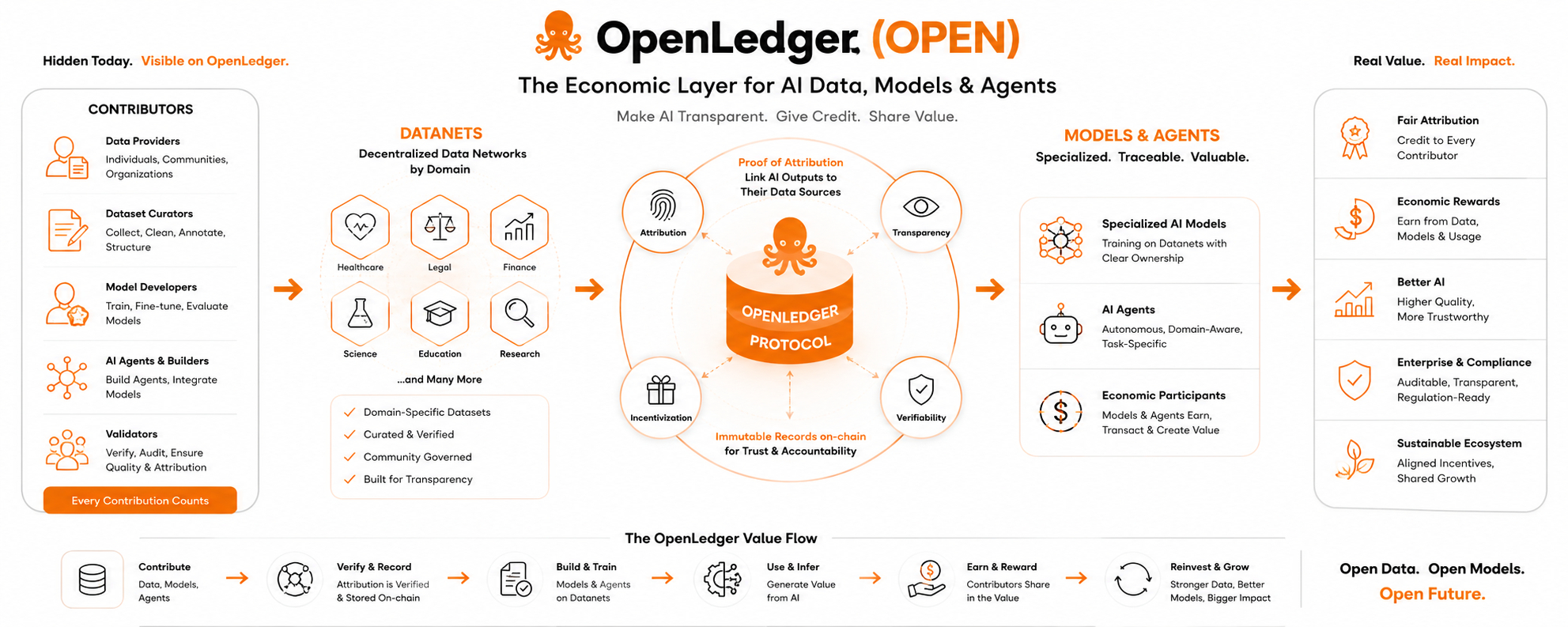
OpenLedger (OPEN) is trying to bring that hidden layer back into view, not as a philosophical exercise but as a functioning system. The idea, as I understand it, is to treat data, models, and even AI agents as part of an economic structure where contribution is recorded and value can be traced back to its origin.
I find myself thinking about how strange the current situation is. Data is arguably the most important raw material of the AI era, yet most contributors never see any downstream benefit once their information is absorbed into a model. It is extracted, refined, and then monetized somewhere far above them in the stack. OpenLedger is essentially challenging that flow.
The way they frame it is through something they call Datanets, which are decentralized data networks built around specific domains. I don’t see this as just another crypto abstraction. It feels closer to an attempt to organize knowledge the way supply chains organize physical goods. Instead of shipping products, you’re tracking information inputs and how they influence model behavior.
What stands out to me is the emphasis on attribution. OpenLedger talks about Proof of Attribution as a way to connect outputs from AI systems back to the datasets that influenced them. If that actually works at scale, it changes how we think about credit in machine intelligence. Right now, credit is almost entirely concentrated at the model level. Everything beneath that is treated as infrastructure cost, not intellectual contribution.
I’ve seen enough of the AI ecosystem to know how quickly that imbalance can grow. The more powerful models become, the more they rely on massive and diverse datasets, yet the less visible those datasets become in public discourse. It creates a kind of economic silence beneath the surface of very loud innovation.
OpenLedger (OPEN), at least in its design, tries to break that silence.
Another part I keep reflecting on is their focus on specialized models instead of chasing one general intelligence system. That direction feels more grounded than the usual narrative around artificial general intelligence. In reality, most valuable AI systems today are already specialized. They are tuned for specific industries, workflows, or decision environments.
When I look at OpenLedger’s approach, I see an attempt to formalize that reality. Instead of one massive model doing everything, you get smaller, domain-specific models trained on curated datasets with clear ownership structures. That alone feels more aligned with how real-world industries operate. A legal AI doesn’t need the same training as a medical AI, and neither should be built on indistinct, untraceable data sources.
There is also something interesting about how they treat models and agents as economic participants. In traditional systems, models are static artifacts. You deploy them, and they respond. In the OpenLedger framing, models become part of a network where usage, inference, and contribution can all be measured and potentially rewarded. That blurs the line between infrastructure and economy in a way that feels very Web3 in spirit, but also very pragmatic if you think about where AI is heading.
I keep thinking about regulation too. Governments are starting to ask harder questions about training data, transparency, and accountability. Even outside regulation, enterprises are becoming more cautious about deploying systems they cannot audit. That pressure alone is likely to force change in how AI systems are built.
OpenLedger (OPEN) seems to be positioning itself exactly at that pressure point. If AI systems need to become more auditable, then the infrastructure underneath them has to evolve. You can’t bolt transparency on top of an already opaque system and expect it to hold.
Of course, I’m also aware of how difficult this kind of system is to build in practice. Coordinating data contribution, verifying attribution, maintaining decentralized infrastructure, and keeping performance high enough for real-world AI workloads is not a small task. A lot of projects in this space struggle when theory meets engineering reality.
Still, I find the direction interesting because it is not trying to compete with frontier AI labs directly. It is not saying “we will build a better model.” Instead, it is saying “we will build a system where models can be built more fairly, more transparently, and with clearer ownership of inputs.”
That distinction matters.
When I zoom out, OpenLedger feels less like a single product and more like an attempt to redefine the economic layer beneath AI. If AI is becoming infrastructure for decision-making, then the question of who gets paid for the raw material behind those decisions is not a side issue. It becomes central.
I don’t think it is clear yet how far this model can go or how widely it will be adopted. But I also don’t think it’s a coincidence that these questions are being asked now, at the exact moment AI systems are moving from experimental tools into foundational economic infrastructure.
OpenLedger (OPEN) is one of those projects that sits slightly ahead of the conversation. Not because it has all the answers, but because it is asking a question the rest of the industry is only starting to no
