OpenLedger là một trong những dự án khiến bạn phải dừng lại một chút, không phải vì lời chào hàng hoàn toàn mới, mà vì vấn đề phía dưới thực sự đủ nghiêm trọng để bạn không thể bỏ qua ngay lập tức.
Và thật lòng mà nói, điều đó hiếm có trong crypto hiện nay.
Sau vài chu kỳ, bạn bắt đầu phát triển một loại dị ứng với những câu chuyện lớn. DeFi sẽ tái xây dựng tài chính. GameFi sẽ thu hút tỷ lệ người dùng tiếp theo. Đất Metaverse sẽ thay thế bất động sản. Chuỗi mô-đun sẽ sửa chữa việc mở rộng. Crypto AI bây giờ là giai đoạn mới nhất, nơi mà mọi dự án đột nhiên khám phá ra rằng nó luôn xoay quanh trí tuệ nhân tạo.
Vì vậy, khi một thứ gọi mình là “chuỗi khối AI”, phản ứng đầu tiên không phải là sự phấn khích. Nó là sự nghi ngờ.
Bạn đọc cụm từ này một lần và não bạn ngay lập tức chuẩn bị cho những cụm từ quen thuộc: trí tuệ phi tập trung, tác nhân mở, chủ quyền dữ liệu, cơ sở hạ tầng có thể mở rộng, quyền sở hữu cộng đồng, sự đồng bộ động lực. Tất cả các thành phần quen thuộc. Tất cả các từ nghe có vẻ quan trọng cho đến khi bạn hỏi điều gì thực sự đang xảy ra bên dưới.
Nhưng OpenLedger ít nhất đang chỉ ra một vấn đề thực sự quan trọng.
AI có một vấn đề đóng góp.
Không phải là một vấn đề thương hiệu. Không phải là một vấn đề token. Một vấn đề đóng góp.
Mọi hệ thống AI hữu ích đều được xây dựng trên dữ liệu, kiến thức, ví dụ, phản hồi, tài liệu, quy trình công việc, nhãn hiệu, sửa chữa và kinh nghiệm miền của người khác. Đó là phần mà mọi người thích bỏ qua. Mô hình được trình bày như sản phẩm, nhưng thực tế mô hình là kết quả cuối cùng của một chuỗi dài các đầu vào vô hình.
Có ai đó đã tạo ra dữ liệu. Có ai đó đã làm sạch nó. Có ai đó đã tổ chức nó. Có ai đó đã đủ hiểu biết về chủ đề để làm cho thông tin trở nên hữu ích. Sau đó, toàn bộ điều đó được hấp thụ vào một mô hình, và khi nó ở bên trong, sự đóng góp ban đầu trở nên gần như không thể nhìn thấy.
Đó là thỏa thuận kỳ lạ của AI hiện đại. Mọi người đều đóng góp vào lớp trí tuệ, nhưng chỉ một vài nền tảng nắm giữ hầu hết giá trị.
OpenLedger đang cố gắng xây dựng quanh khoảng trống đó.
Ý tưởng cơ bản là dữ liệu, mô hình, và tác nhân AI không nên chỉ nổi lềnh bềnh như những đối tượng số mơ hồ. Chúng nên có thể truy tìm. Chúng nên có nguồn gốc. Chúng nên được kết nối với những người hoặc cộng đồng đã tạo ra chúng. Và nếu chúng tạo ra giá trị sau này, nên có một cơ chế để thưởng cho những người đóng góp đứng sau chúng.
Điều đó nghe có vẻ hiển nhiên khi bạn nói chậm lại. Nó cũng nghe có vẻ cực kỳ khó khăn khi bạn nghĩ về cách AI thực sự hoạt động.
Bởi vì việc ghi nhận AI rất rối rắm.
Một mô hình không trả lời một câu hỏi chỉ bằng cách kéo một tệp từ kệ. Nó không nói, “Phản hồi này đến 12% từ bộ dữ liệu của Ali, 8% từ báo cáo kiểm toán này, và 3% từ bài viết trên diễn đàn đó.” Ít nhất là không một cách tự nhiên. Đầu ra được hình thành bởi dữ liệu đào tạo, tinh chỉnh, trọng số, lời nhắc, nhúng, hệ thống truy xuất, bộ điều hợp, và bất cứ điều gì khác đã được gắn vào hệ thống.
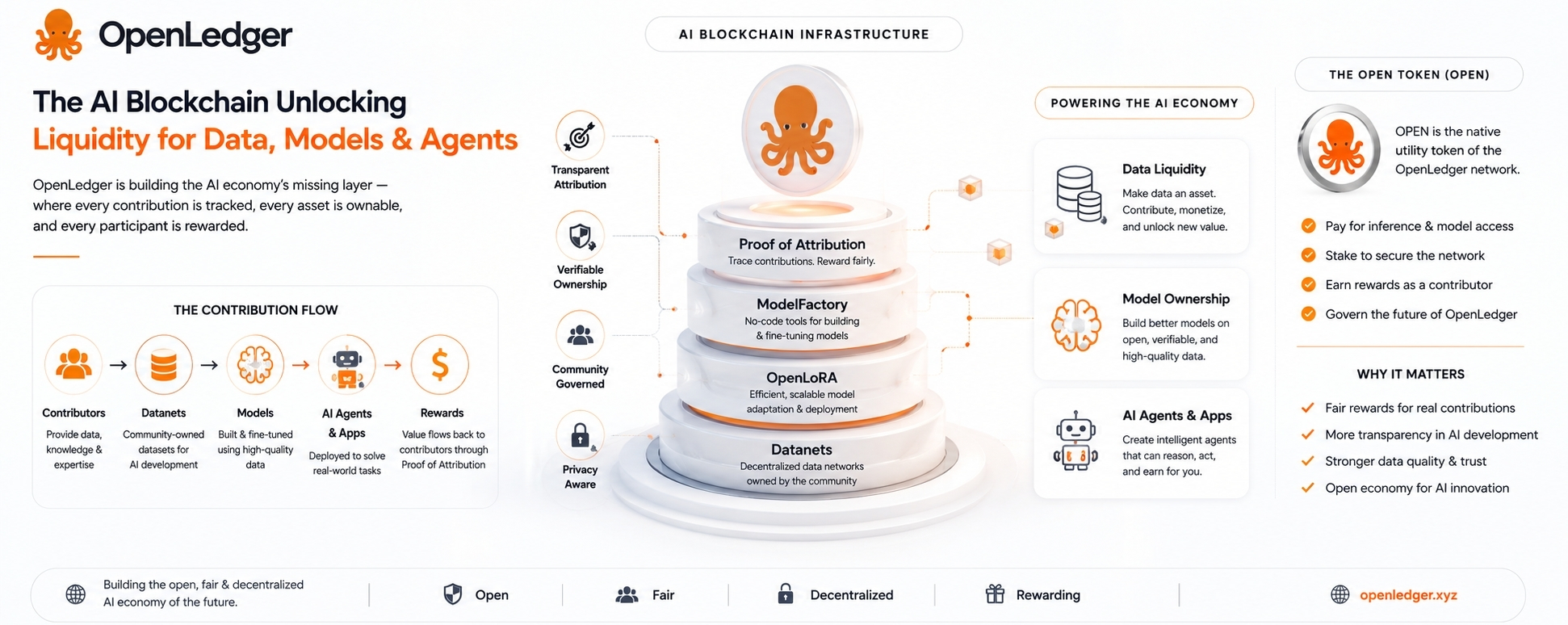
Vì vậy, khi OpenLedger nói về Chứng minh Ghi nhận, đó là phần đáng chú ý nhưng cũng là phần xứng đáng nhất với sự hoài nghi.
Ý tưởng là xác định dữ liệu nào đã ảnh hưởng đến một đầu ra AI và thưởng cho những người đóng góp dựa trên ảnh hưởng đó. Nếu nó hoạt động, điều đó có ý nghĩa. Nếu nó trở nên mơ hồ và chỉ là cử chỉ, nó chỉ là một hệ thống điểm hóa token hóa khác với ngôn ngữ tốt hơn.
Đó là ranh giới mà OpenLedger phải đi qua.
Tuy nhiên, cách khung không phải là trống rỗng. AI cần một lớp kế toán tốt hơn. Hiện tại, internet đầy giá trị mà các hệ thống AI tiêu thụ, nén và kiếm tiền. Đầu ra cảm thấy sạch sẽ, nhưng lịch sử đầu vào thì mờ mịt. Và khi các tác nhân AI trở nên phổ biến hơn, sự mờ mịt đó trở thành một vấn đề lớn hơn.
Nếu một tác nhân AI giúp kiểm toán một hợp đồng thông minh, kiến thức an ninh của nó đến từ đâu?
Nếu một trợ lý giao dịch AI nhận ra một mẫu, dữ liệu của ai đã giúp dạy nó?
Nếu một công cụ AI pháp lý xem xét một hợp đồng, tài liệu nào đã hình thành lý luận của nó?
Nếu một trợ lý y tế đưa ra một gợi ý, kiến thức nào đã nằm dưới câu trả lời đó?
Đây không còn là những câu hỏi triết lý nữa. Chúng trở thành những câu hỏi kinh tế ngay khi mọi người bắt đầu trả tiền cho đầu ra.
Đó là lý do tại sao Datanets của OpenLedger lại thú vị.
Một Datanet cơ bản là một mạng lưới dữ liệu thuộc sở hữu cộng đồng được xây dựng quanh một chủ đề hoặc trường hợp sử dụng cụ thể. Thay vì dữ liệu bị thu thập một cách âm thầm bởi một công ty tập trung, các đóng góp có thể thêm thông tin hữu ích vào một lớp dữ liệu chia sẻ. Dữ liệu đó sau đó có thể được sử dụng để đào tạo hoặc tinh chỉnh các mô hình.
Về lý thuyết, bạn có thể có một Datanet cho các lỗ hổng hợp đồng thông minh, một cái khác cho tài liệu pháp lý, một cái khác cho quy trình làm việc trong chăm sóc sức khỏe, một cái khác cho dữ liệu bản đồ, một cái khác cho phân tích rủi ro DeFi, và cứ như vậy.
Ý tưởng không chỉ là thu thập dữ liệu. Mọi người đều thu thập dữ liệu. Ý tưởng là giữ một hồ sơ về ai đã đóng góp cái gì, sau đó kết nối đóng góp đó với việc sử dụng mô hình trong tương lai.
Đó là phần cảm thấy nghiêm túc hơn so với những gì thường thấy trong quảng cáo “AI cộng token”.
Bởi vì nếu AI chuyên biệt thực sự là hướng đi của thị trường, thì dữ liệu chuyên biệt trở nên cực kỳ giá trị. Các mô hình tổng quát đã đủ tốt cho các nhiệm vụ rộng lớn. Cuộc chiến tiếp theo không phải là ai có thể khiến một chatbot nói những điều hay ho. Nó là ai có thể xây dựng các mô hình hiểu sâu về các miền cụ thể.
Một AI tổng quát có thể giải thích rủi ro hợp đồng thông minh. Một mô hình chuyên biệt được đào tạo dựa trên dữ liệu lỗ hổng thực sự có thể giúp phát hiện nó.
Một AI tổng quát có thể nói về tài chính. Một mô hình chuyên biệt được đào tạo dựa trên hành vi thị trường có cấu trúc và dữ liệu rủi ro có thể trở nên hữu ích hơn.
Một AI tổng quát có thể tóm tắt nội dung chăm sóc sức khỏe. Một mô hình lâm sàng chuyên biệt, giả sử quyền riêng tư và tuân thủ được xử lý đúng cách, có thể làm điều gì đó có giá trị hơn nhiều.
Vì vậy, OpenLedger đang nhắm vào một xu hướng thực sự: sự chuyển mình từ AI tổng quát sang trí tuệ theo miền cụ thể.
Nhưng một lần nữa, việc thực thi là quan trọng.
Crypto có thói quen biến mọi vấn đề hợp lệ thành một nền kinh tế token được thiết kế quá mức. Đôi khi token là cần thiết. Đôi khi nó chỉ là băng dính cho một thị trường có thể hoạt động mà không cần đến nó.
OPEN, token bản địa, được cho là sẽ nằm trong nền kinh tế OpenLedger. Nó có thể được sử dụng cho phí mạng, truy cập mô hình, thanh toán suy diễn, staking, quản trị, và phần thưởng cho người đóng góp. Điều đó có ý nghĩa về mặt cấu trúc. Nếu mạng lưới thực sự được sử dụng, token có vai trò.
Nhưng cụm từ “nếu mạng lưới thực sự được sử dụng” đang làm rất nhiều công việc ở đây.
Một token không tạo ra nhu cầu chỉ bằng việc tồn tại. Một thị trường không trở nên có giá trị chỉ vì một bảng điều khiển nói rằng các đóng góp có thể kiếm được. Phần khó khăn là khiến mọi người đóng góp dữ liệu chất lượng cao, khiến các nhà phát triển xây dựng các mô hình từ dữ liệu đó, khiến người dùng trả tiền cho những mô hình đó, và đảm bảo phần thưởng chảy theo cách cảm thấy công bằng hơn là ngẫu nhiên.
Đó là nơi nhiều dự án crypto gặp khó khăn.
Họ có thể thiết kế các động lực cho làn sóng đầu tiên. Họ có thể thu hút những người đóng góp sớm. Họ có thể làm cho các biểu đồ (candlestick) trông sống động. Nhưng giá trị dài hạn chỉ đến khi hệ thống tạo ra điều gì đó mà người ngoài vòng lợi ích thực sự muốn.
Tương lai của OpenLedger phụ thuộc vào việc nó có thể sản xuất các hệ thống AI hữu ích, không chỉ là các bộ dữ liệu được gán nhãn tốt.
ModelFactory là một phần trong nỗ lực đó. Nó nhằm mục đích làm cho việc tinh chỉnh dễ dàng hơn, đặc biệt cho những người không muốn xử lý cơ sở hạ tầng học máy nặng nề. Đó là một hướng đi tốt vì hầu hết các chuyên gia miền không phải là kỹ sư ML.
Người hiểu các hợp đồng pháp lý có thể không biết cách tinh chỉnh một mô hình.
Nhà giao dịch hiểu cấu trúc thị trường có thể không biết cách triển khai hạ tầng suy diễn.
Nhà nghiên cứu an ninh hiểu các lỗ hổng có thể không muốn quản lý các bộ điều hợp và GPU.
Nếu OpenLedger có thể giúp những người này biến kiến thức thành tài sản AI hữu dụng, điều đó có ý nghĩa.
OpenLoRA là một phần thực tiễn khác. Các mô hình chuyên biệt rất hữu ích, nhưng việc chạy chúng có thể trở nên tốn kém. Tinh chỉnh dựa trên LoRA đã trở thành một trong những con đường thực tế hơn để tạo ra nhiều biến thể mô hình nhẹ. Nếu OpenLedger có thể hỗ trợ triển khai hiệu quả nhiều mô hình đã được tinh chỉnh, điều đó sẽ cung cấp cho hệ sinh thái một nền tảng thực tiễn hơn.
Đây là nơi dự án bắt đầu trông ít giống như một trò chơi kể chuyện thuần túy và nhiều hơn như một nỗ lực xây dựng một hệ thống sản xuất AI hoàn chỉnh.
Dữ liệu được đưa vào thông qua Datanets.
Các mô hình được tạo ra hoặc tinh chỉnh thông qua các công cụ như ModelFactory.
OpenLoRA giúp với việc triển khai.
Các tác nhân và ứng dụng AI nằm ở trên cùng.
Chuỗi ghi lại sự đóng góp, sử dụng, và phần thưởng.
Đó là bản đồ, ít nhất.
Liệu lãnh thổ có trông như vậy hay không lại là một câu hỏi khác.
Phần khó nhất vẫn là việc ghi nhận. Viết “Chứng minh Ghi nhận” trong một tài liệu trắng thì dễ. Khó hơn nhiều để khiến các đóng góp tin rằng hệ thống đang đo lường ảnh hưởng một cách chính xác. Nếu phần thưởng quá mơ hồ, mọi người sẽ mất hứng thú. Nếu hệ thống có thể bị lợi dụng, dữ liệu kém chất lượng sẽ tràn vào. Nếu chỉ những người đóng góp lớn hưởng lợi, góc độ cộng đồng sẽ yếu đi. Nếu việc ghi nhận quá đắt hoặc quá chậm, các nhà phát triển có thể tránh xa nó.
Cũng có vấn đề về quyền riêng tư. Một số dữ liệu AI quý giá nhất là nhạy cảm. Dữ liệu chăm sóc sức khỏe, hồ sơ tài chính, tài liệu pháp lý, quy trình làm việc doanh nghiệp — đây không phải là những thứ mà mọi người tùy tiện ném vào một mạng lưới mở. OpenLedger sẽ cần các con đường cấp phép mạnh mẽ, quyền riêng tư và tuân thủ nếu nó muốn có sự chấp nhận nghiêm túc vượt ra ngoài các bộ dữ liệu gốc crypto.
Sau đó có vấn đề thị trường. Crypto AI thì đông đúc. Mỗi tuần lại có một nền tảng tác nhân khác, chợ dữ liệu, mạng suy diễn, lớp tính toán phi tập trung, hoặc giao thức sở hữu mô hình. Một số thì có suy nghĩ. Nhiều cái chỉ là vỏ bọc kể chuyện. Các nhà đầu tư và người dùng thì đã mệt mỏi, dù họ vẫn đuổi theo vòng quay tiếp theo.
Vì vậy, OpenLedger cần phải chứng minh rằng cơ chế cốt lõi của nó thực sự quan trọng.
Không phải trong lý thuyết.
Trong sử dụng.
Liệu ai đó có thể xây dựng một mô hình tốt hơn nhờ vào OpenLedger không?
Liệu một người đóng góp có thể kiếm được vì dữ liệu của họ thực sự cải thiện một đầu ra không?
Liệu một nhà phát triển có thể ra mắt một tác nhân AI nhanh hơn hoặc rẻ hơn không?
Liệu một người dùng có thể tin tưởng vào nguồn gốc của những gì họ đang tương tác không?
Liệu hệ thống có thể thu hút dữ liệu mà trước đây không xuất hiện ở đâu khác không?
Đó là những câu hỏi quan trọng.
Và có thể đó là lý do tại sao OpenLedger xứng đáng được theo dõi mà không bị cuốn đi.
Nó không tự động mang tính cách mạng. Nó không đảm bảo trở thành lớp nền tảng của quyền sở hữu AI. Nó không miễn nhiễm với các vấn đề crypto thông thường như đầu cơ, hoạt động bị khuyến khích quá mức, và lạm phát kể chuyện.
Nhưng nó đang xoay quanh một vấn đề thực sự.
AI đang tạo ra giá trị khổng lồ từ những đầu vào vô hình. Hệ thống hiện tại không có cách công bằng hoặc minh bạch để theo dõi những đầu vào đó. OpenLedger đang cố gắng xây dựng lớp thiếu hụt đó bằng cách sử dụng các đường ray blockchain, logic ghi nhận, và các động lực token.
Có thể điều đó sẽ hiệu quả. Có thể không.
Nhưng vấn đề thực sự đủ để nỗ lực này xứng đáng với nhiều hơn một cái lắc đầu nhanh chóng.
Cách rõ ràng nhất để nghĩ về OpenLedger là: nó muốn cung cấp cho AI một bộ nhớ kinh tế.
Không chỉ là bộ nhớ theo nghĩa mô hình, mà còn là bộ nhớ của sự đóng góp. Ai đã thêm dữ liệu? Ai đã hình thành mô hình? Ai đã xây dựng tác nhân? Ai xứng đáng nhận được một phần khi hệ thống trở nên hữu ích?
Đó là một ý tưởng hấp dẫn, đặc biệt trong một thế giới mà AI đang trở nên mạnh mẽ hơn và tập trung hơn cùng một lúc.
Người hoài nghi trong tôi vẫn muốn có bằng chứng. Sử dụng thực tế. Các đóng góp thực tế. Các mô hình thực tế. Nhu cầu thực tế. Không chỉ là các chiến dịch, điểm, phát hành token và ảnh chụp màn hình của các đối tác trong hệ sinh thái.
Nhưng nhà nghiên cứu trong tôi hiểu tại sao danh mục này lại quan trọng.
Nếu giai đoạn tiếp theo của AI được xây dựng dựa trên dữ liệu chuyên biệt và các tác nhân tự động, thì quyền sở hữu và ghi nhận không phải là các tính năng phụ. Chúng trở thành cơ sở hạ tầng.
OpenLedger đang đặt cược vào điều đó.
Và sau khi đọc đủ các tài liệu trắng để biết những điều này thường sụp đổ thành tiếng ồn, cái này ít nhất để lại một câu hỏi đáng lưu tâm: