
I’ve honestly seen enough AI narratives promising “data ownership” and “fair AI economies” to become naturally skeptical 🔄📊
Every cycle repeats the same idea in slightly different packaging: contribute your data, help train AI, receive rewards, participate in the future of decentralized intelligence.
It sounds reasonable on the surface.
If AI models depend on human-generated data, then contributors should theoretically receive part of the value created later. Simple logic. Almost too simple 👀🧩
But the more I think about it, the more I feel the real problem in AI economies was never data scarcity.
It’s attribution.
More specifically: who controls how data influence is measured, and who defines how value flows back through the system.
That’s the lens I keep returning to when looking at OpenLedger 🚀⚡
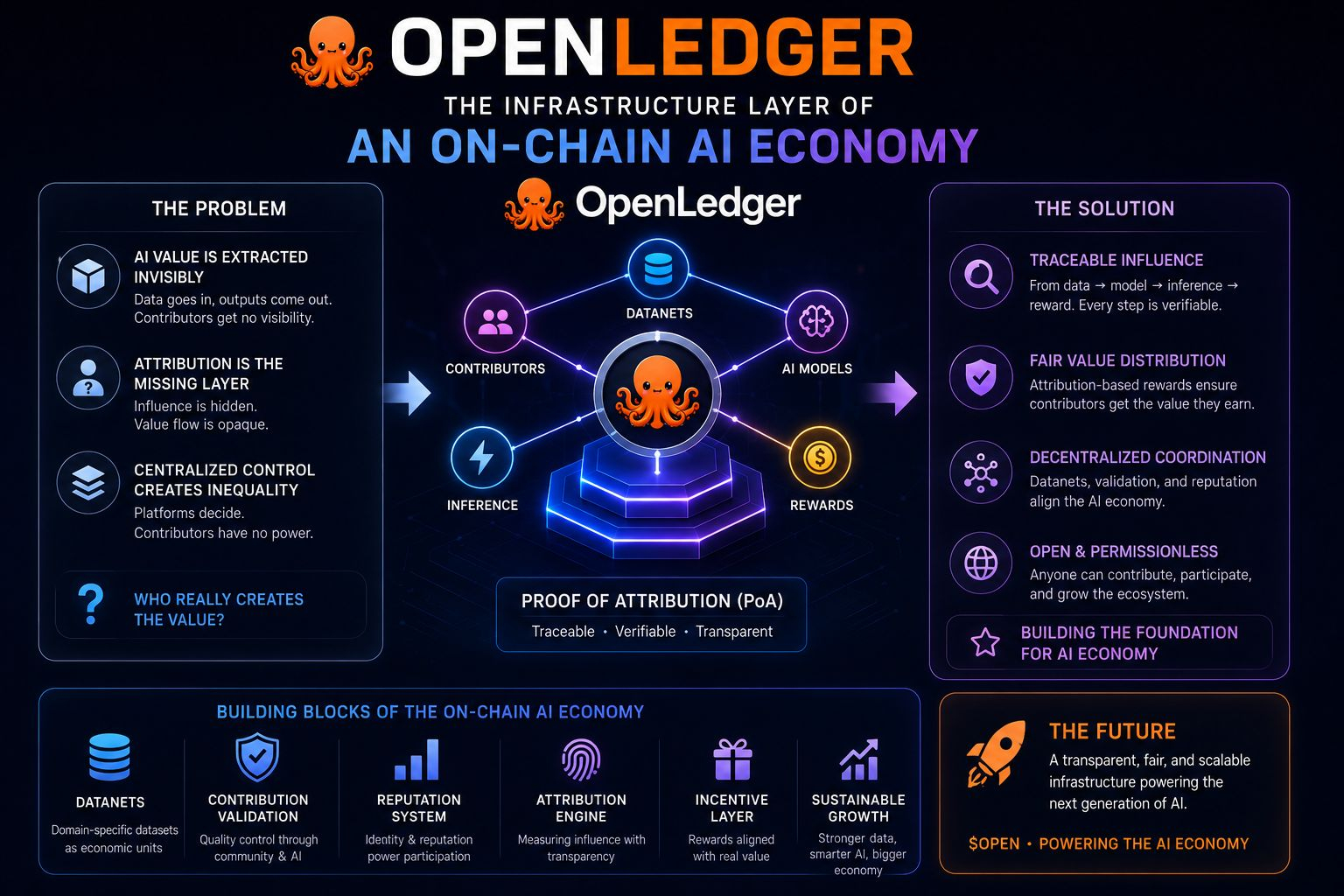
From what I understand, OpenLedger isn’t only building AI models or inference infrastructure. They seem to be building an on-chain coordination layer where datasets, models, inference activity, and reward distribution become traceable parts of the same economic system.
And honestly, that’s a much more ambitious direction than simply launching “another AI coin.”
The interesting part is how Proof of Attribution (PoA) changes the framing.
Instead of treating AI as a black box that magically generates outputs, OpenLedger tries to create a traceable relationship between: data → model contribution → inference → reward 🌍📈
At least conceptually, that’s extremely important.
Because most current AI systems extract value invisibly. Data enters the model. Outputs leave the model. Nobody really sees how influence flows internally, and contributors rarely understand how much value their participation actually created.
OpenLedger seems to be trying to expose that hidden layer.
But this is exactly where my skepticism also begins 🧠🔧
The entire architecture quietly assumes something very difficult:
that the influence of data inside AI systems can be measured accurately enough to distribute economic value fairly.
And I’m not fully convinced that problem is as solvable as people think.
Most AI outputs are not generated from one isolated dataset or one clean contribution source. They emerge from overlapping embeddings, millions of parameter adjustments, retrieval layers, fine-tuning behavior, contextual weighting, and inference interactions happening simultaneously ⚡🧩
Influence inside machine learning systems is rarely linear.
So when a protocol assigns attribution scores or contribution rewards, it’s not measuring “objective truth.” It’s measuring influence through a designed estimation framework.
That distinction matters a lot more than most narratives admit.
Because once attribution becomes financial infrastructure, whoever defines the attribution model indirectly defines the economy itself 👀📊
And I think this is where OpenLedger becomes more interesting than typical AI narratives.
Most people see: “AI + revenue sharing + data ownership.”
What I see is: an attempt to transform influence into something economically measurable.
That’s a completely different challenge.
The Datanets architecture makes this even more visible 🌐🚀
At first glance, Datanets sound like decentralized datasets organized by domain: finance, medical, technical knowledge, specialized sectors, etc.
But the deeper implication is that OpenLedger is trying to turn datasets into economic coordination units.
Not just storage.
Not just AI training material.
But active infrastructure layers where contributors participate, receive validation, build reputation scores, and eventually compete for attribution-based rewards.
And honestly, I think this changes user behavior significantly.
Because once economic incentives appear, the competitive edge no longer comes purely from “having useful data.” The edge shifts toward understanding how the system evaluates usefulness itself 🔄⚙️
That’s where things become complicated.
If attribution models are imperfect — and realistically they probably always will be to some extent — then reward distribution may consistently favor certain contribution patterns over others, even when actual influence is harder to isolate precisely.
And paradoxically, a transparent but flawed attribution system could sometimes create more structural distortion than having no attribution at all.
That’s the part I rarely see discussed seriously inside AI x Crypto conversations.
People love the narrative of transparent AI economies because it feels morally intuitive: contributors deserve rewards.
I agree with that direction conceptually.
But once you operationalize attribution inside large-scale AI systems, you quickly realize transparency itself depends on abstractions, assumptions, weighting models, and estimation methods 📈💡
The system may appear transparent while still simplifying a much more chaotic underlying reality.
And maybe that’s why I don’t really see OpenLedger as “just an AI coin.”
It feels more like infrastructure attempting to solve one of the hardest unanswered problems in AI economies:
“How do you convert data influence into programmable economic value?”
That’s much deeper than token narratives.
Of course, architecture diagrams and tokenomics alone prove nothing.
The real test only starts once the system handles:
noisy datasets,
overlapping attribution,
adversarial contribution behavior,
competing Datanets,
and real economic pressure at scale 👀⚡
That’s usually where elegant theories meet operational reality.
Still, I think OpenLedger is one of the few AI projects currently exploring this problem seriously instead of simply selling automation hype.
Not necessarily because they already solved it.
But because they seem willing to confront how messy AI value distribution actually becomes once real incentives enter the system 🧠🌍🔧
And honestly, that’s the part I’ll keep watching most closely.