OpenLedger đang ngồi ở cái góc xấu xí của thị trường AI mà hầu hết mọi người vẫn cố tránh nhắc đến. Không phải những video demo sạch sẽ. Không phải những bảng điều khiển agent bóng bẩy. Không phải những lời hứa lớn về tự động hóa thông minh hơn.
Tôi đã xem bộ phim này quá nhiều lần trong crypto. Một dự án xuất hiện với một ý tưởng kỹ thuật lớn. Thị trường nắm bắt phiên bản dễ nhất của câu chuyện. Các trader biến nó thành một ticker. Các chủ đề biến nó thành tiếng ồn. Rồi sau sáu tháng, mọi người cuối cùng bắt đầu đặt câu hỏi liệu cái thứ đó có thực sự giải quyết được vấn đề gì không. Hầu hết không. Họ chỉ tái chế cùng một chiêu trò với những màu sắc khác nhau.
OpenLedger ít nhất có một vấn đề sắc nét hơn trước mặt.
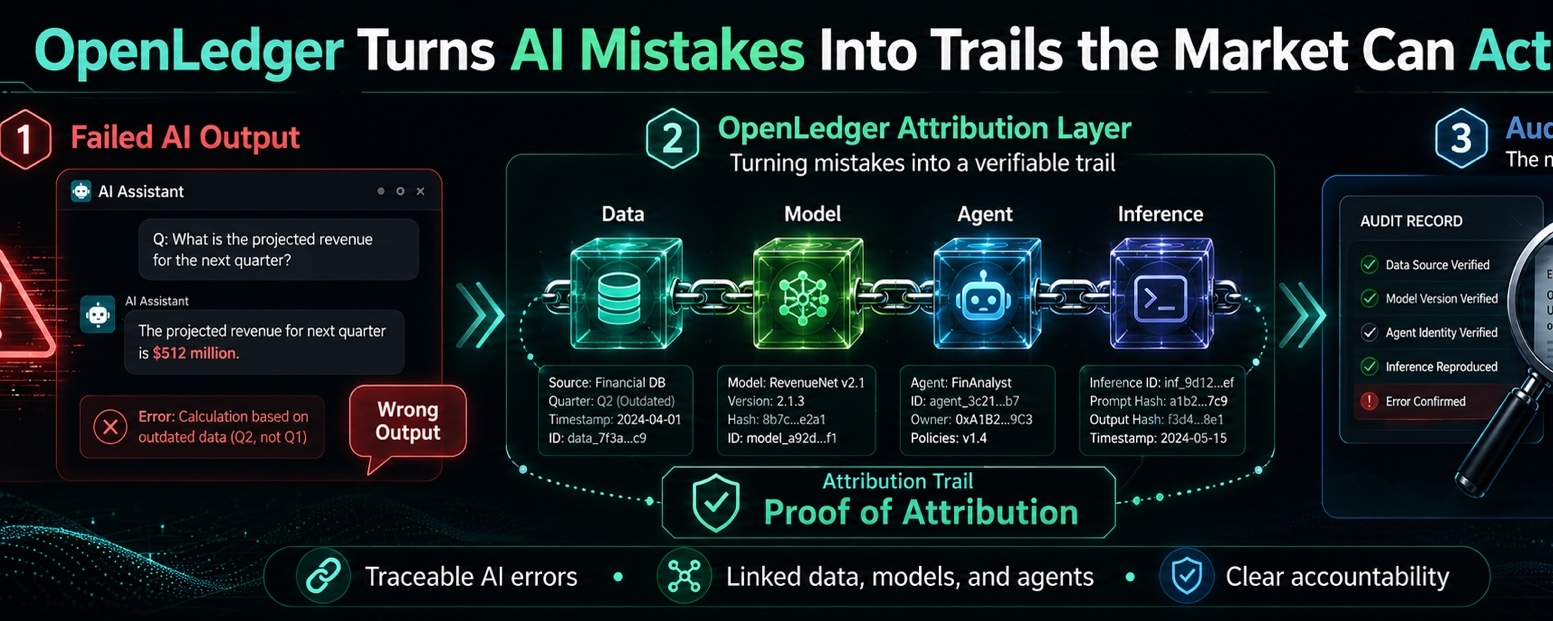
Dự án không chỉ cố gắng đưa hoạt động AI lên chuỗi chỉ vì muốn nghe hiện đại. Phần thú vị hơn là khả năng truy xuất. Khi dữ liệu cung cấp cho một mô hình, khi một mô hình định hình một câu trả lời, khi một đại lý hành động dựa trên câu trả lời đó, OpenLedger muốn những bước đó để lại một bản ghi. Nghe có vẻ khô khan. Tốt. Hầu hết những điều hữu ích trong thị trường này nghe có vẻ khô khan trước khi chúng thực sự quan trọng.
Bởi vì vấn đề thực sự với AI không phải là nó thất bại.
Tất nhiên nó thất bại.
Vấn đề là thất bại thường không có dấu vết sạch. Một mô hình đưa ra câu trả lời sai. Một quy trình làm việc bị hỏng. Một người dùng mất tiền, thời gian, niềm tin, hoặc cả ba. Rồi thì mọi người bắt đầu đổ lỗi lẫn nhau. Ứng dụng đổ lỗi cho mô hình. Lớp mô hình đổ lỗi cho dữ liệu. Nguồn dữ liệu bị ẩn. Đường đi của đại lý không rõ ràng. Ai cũng chỉ chỉ vào một nơi khác. Không ai nắm giữ bản đồ đầy đủ.
Đó là khoảng trống mà OpenLedger đang cố gắng lấp đầy.
Ý tưởng Proof of Attribution của nó cơ bản là đặt ra một câu hỏi khó: nếu một đầu ra AI bị ảnh hưởng bởi dữ liệu nhất định, có thể theo dõi ảnh hưởng đó không? Nếu câu trả lời là hữu ích, người đóng góp nên được thưởng. Tốt. Đó là phần sạch. Nhưng tôi quan tâm hơn đến phần bẩn. Điều gì xảy ra khi câu trả lời không tốt? Điều gì xảy ra khi dữ liệu yếu, lỗi thời, thiên lệch, bị sao chép, hoặc âm thầm có hại? Hệ thống có thể cho thấy điều đó không, hay nó chỉ hoạt động khi câu chuyện thuận lợi?
Đó là nơi tôi bắt đầu chú ý.
Thị trường thích những câu chuyện thưởng. Ai cũng muốn nói về tiềm năng. Những người đóng góp được trả tiền. Các mô hình cải thiện. Các đại lý trở nên hữu ích hơn. Tuyệt. Nhưng tôi đã có đủ thời gian để biết thử thách thực sự thường đến khi có điều gì đó bị hỏng. Khi một hệ thống phải giải thích một thất bại, không chỉ ăn mừng một thành công.
Nếu OpenLedger có thể biến các đầu ra AI thất bại thành những dấu vết có thể đọc được, thì nó đang làm việc trên một cái gì đó thực sự có thể quan trọng. Không phải vì nó làm cho AI hoàn hảo. Nó sẽ không. Không ai nghiêm túc nên tin điều đó. Nhưng vì các đầu ra xấu cần có trí nhớ. Chúng cần ngữ cảnh. Chúng cần một cách để cho thấy dữ liệu nào đã chạm vào chúng, con đường mô hình nào đã hình thành chúng, hành vi của đại lý nào đã đưa chúng tiến về phía trước, và ai đã gắn kết kinh tế với kết quả.
Điều đó không phải là hào nhoáng.
Điều đó là cần thiết.
Hãy nghĩ về một đại lý AI đưa ra quyết định sai lầm trong một quy trình tài chính. Có thể nó đọc rủi ro sai. Có thể nó dựa vào tập dữ liệu sai. Có thể mô hình là tốt nhưng lớp truy xuất kéo ra rác. Có thể đại lý thực hiện quá nhanh vì giao diện được thiết kế cho tốc độ thay vì thận trọng. Trong thiết lập ngày nay, thất bại đó trở thành một cái nhìn mờ mịt sau cái chết. Ảnh chụp màn hình, nhật ký, phỏng đoán, lý do.
Với cách tiếp cận của OpenLedger, đầu ra thất bại có thể trở thành một cái gì đó gần giống như một dấu vết kiểm toán. Không phải là chứng cứ hoàn hảo. Không phải là câu trả lời trong phòng xử án. Nhưng là một điểm khởi đầu tốt hơn so với “AI đã nói vậy.”
Đó là một tiêu chuẩn thấp, thành thật mà nói. Nhưng thị trường được xây dựng trên những tiêu chuẩn thấp được vượt qua vào thời điểm đúng.
Ngành AI hiện đang vào giai đoạn khó khăn. Sự phấn khích dễ dàng đã bắt đầu nhạt dần. Mọi người đã thấy đủ chatbot, đủ demo của các đại lý, đủ các lời hứa về năng suất. Giai đoạn tiếp theo sẽ xấu hơn. Mọi người sẽ bắt đầu hỏi về chi phí, độ chính xác, sự tin tưởng, tuân thủ, trách nhiệm, và cách sử dụng thực tế. Họ sẽ hỏi ai được trả tiền khi AI hoạt động, và ai sẽ bị chất vấn khi nó không hoạt động.
OpenLedger dường như được xây dựng quanh lớp thứ hai đó.
Mạng lưới dữ liệu của dự án được thiết kế để hỗ trợ AI chuyên biệt. Điều đó quan trọng vì các mô hình chung thường quá rộng. Rộng có thể hữu ích, nhưng rộng cũng có thể lười biếng. Nếu bạn đang xây dựng cho tài chính, pháp luật, chăm sóc sức khỏe, nghiên cứu, hoặc hoạt động doanh nghiệp, bạn cần dữ liệu sắc nét hơn. Bạn cần ngữ cảnh lĩnh vực. Bạn cần ít fluff hơn. Đề xuất của OpenLedger là những người đóng góp có thể giúp xây dựng những lớp dữ liệu mạnh mẽ hơn và nhận giá trị khi đầu vào của họ quan trọng.
Tôi thích ý tưởng đó trong lý thuyết.
Nhưng lý thuyết thì rẻ ở đây. Rẻ đau đớn.
Thử thách thực sự, tuy nhiên, là liệu OpenLedger có thể ngăn chặn hệ thống thưởng trở thành một trang trại khác không. Bất kỳ khi nào crypto thưởng cho sự đóng góp, mọi người bắt đầu tối ưu hóa cho phần thưởng thay vì chất lượng. Họ tải lên rác. Họ sao chép công việc. Họ nhồi nhét hệ thống với những tài liệu ít giá trị. Họ săn lùng phát thải. Cùng một cơn mệt mỏi cũ. Nếu OpenLedger không thể phân tách dữ liệu hữu ích khỏi tiếng ồn, lớp ghi nhận trở thành một cái bảng điều khiển đẹp trên một hồ bơi bẩn.
Đó là phần tôi sẽ theo dõi chặt chẽ.
Không phải là những thông báo to nhất. Không phải là sự xoay vòng của người ảnh hưởng. Không phải là cây nến token hàng ngày. Tôi sẽ theo dõi xem liệu hệ thống có thu hút được những người xây dựng nghiêm túc và những người đóng góp dữ liệu nghiêm túc không. Tôi sẽ theo dõi xem liệu các đại lý sử dụng OpenLedger có trở nên tốt hơn một cách nghĩa đen nhờ vào lớp ghi nhận không. Tôi sẽ theo dõi xem liệu các đầu ra thất bại có thể thực sự được kiểm tra theo cách giúp ai đó sửa chữa hệ thống không.
Bởi vì đó là nơi mà dự án hoặc kiếm được vị trí của nó hoặc lụi tàn vào đống token AI.
$OPEN chỉ quan trọng nếu mạng lưới quan trọng. Tôi biết điều đó nghe có vẻ hiển nhiên, nhưng thị trường này quên những điều hiển nhiên mỗi chu kỳ. Một token có thể hoạt động dựa trên câu chuyện một thời gian. Tính thanh khoản có thể khiến bất cứ điều gì trông sống động trong vài tuần. Nhưng nếu hệ thống cơ bản không tạo ra nhu cầu thực sự, biểu đồ cuối cùng sẽ bắt đầu nói lên sự thật theo cách tàn nhẫn của nó.
Và sự thật thường rất chậm.
OpenLedger có cơ hội tốt hơn so với các đề xuất AI tái chế trung bình vì nó đang chạm vào một vấn đề sẽ không biến mất. Trách nhiệm AI sẽ ngày càng nặng nề hơn. Khi các đại lý đi sâu hơn vào các quy trình làm việc thực tế, thất bại sẽ trở nên đắt đỏ hơn. Người dùng sẽ yêu cầu chứng minh. Doanh nghiệp sẽ yêu cầu đường dẫn kiểm toán. Những người xây dựng sẽ cần giải thích không chỉ tại sao điều gì đó hoạt động, mà còn tại sao điều gì đó lại thất bại.
Đó là nơi mà ghi nhận ngừng trở thành một tính năng kỹ thuật đẹp và bắt đầu trở thành cơ sở hạ tầng sinh tồn.
Tuy nhiên, tôi chưa sẵn sàng để vỗ tay quá sớm. Tôi đã theo dõi quá nhiều dự án biến một ý tưởng tốt thành một token, rồi biến token thành toàn bộ sản phẩm. OpenLedger phải tránh cái bẫy đó. Sản phẩm phải dẫn dắt. Sử dụng phải dẫn dắt. Chất lượng dữ liệu phải dẫn dắt. Token nên di chuyển xung quanh hoạt động thực tế, không mang toàn bộ câu chuyện trên lưng.
Tuy nhiên, có điều gì đó ở đây.
Một hệ thống nơi đầu ra của AI có trí nhớ. Nơi dữ liệu không biến mất sau khi được sử dụng. Nơi những người đóng góp có thể được thưởng, nhưng cũng nơi những đầu vào yếu có thể bị chất vấn. Nơi một câu trả lời xấu không đơn giản biến mất vào bóng tối với mọi người nhún vai.
Đó là phần tôi liên tục quay lại.
OpenLedger không bán AI hoàn hảo. Ít nhất, đó không phải là phiên bản đáng được coi trọng. Phiên bản đáng theo dõi lạnh lùng hơn nhiều: AI sẽ thất bại, và ai đó cần xây dựng bản ghi về cách nó thất bại.