Mình có một observation về cách các data economy lớn được build trong lịch sử.
Không có data economy nào được build vì người tạo ra data tự nguyện share. Tất cả đều được build vì một bên đủ mạnh để aggregate data — và bên kia không có choice.
Và đó là lý do @OpenLedger thesis vừa compelling vừa khó — vì họ đang cố reverse dynamic đó.
Facebook build social graph không phải vì user muốn donate data cho Zuckerberg. User muốn kết nối với bạn bè — data là byproduct. Facebook aggregate byproduct đó và monetize. User không có choice vì network effect đã lock in.
Google build search data không phải vì people muốn train Google AI. People muốn find information — search behavior là byproduct. Google aggregate và monetize. Không có alternative đủ lớn để switch to.
AI company build training data tương tự. Creator muốn share work — data là byproduct. AI scrape byproduct đó, train model, monetize output. Creator không có mechanism để opt out meaningfully.
@OpenLedger đang build mechanism để reverse dynamic đó — give creator visibility và royalty over byproduct of their work. $OPEN là settlement currency cho reversal đó.
Tự phản biện: reversing incumbent data dynamic cần power shift thật sự. Creator movement, regulatory pressure, legal precedent — tất cả cần align cùng lúc. History cho thấy data incumbent rất resilient — user keep using Facebook dù biết data bị exploit.
@OpenLedger cần answer một câu hỏi chưa ai solve: làm sao make creator care enough để act differently.
Đó là harder problem than building attribution mechanism.
#openledger $WLD $NEAR
Bài viết
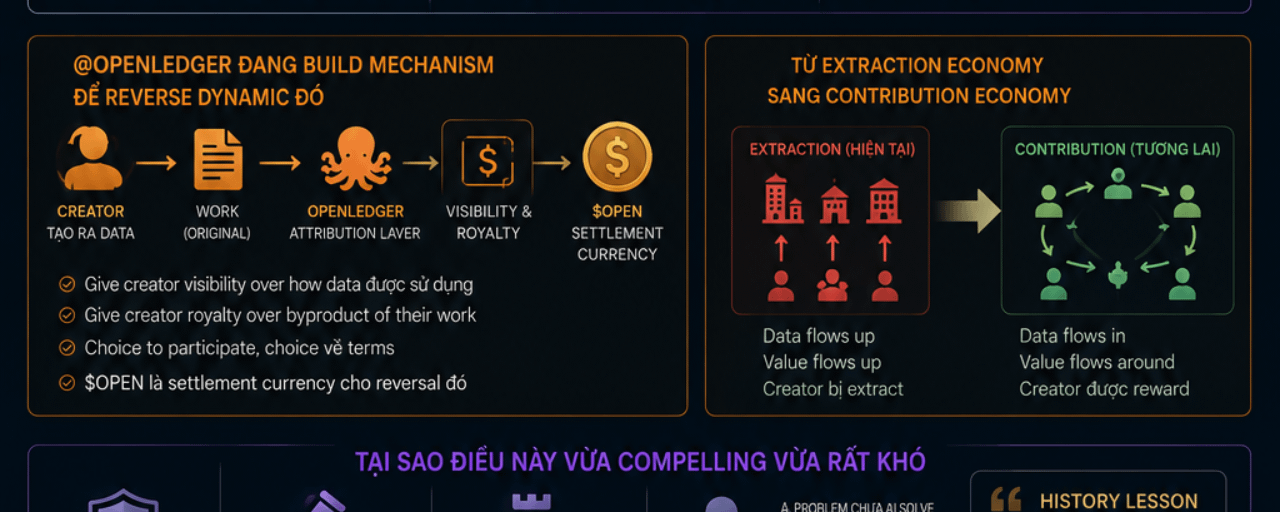
OpenLedger đang cố reverse dynamic mà Facebook và Google đã build trong nhiều thập kỷ
Tuyên bố miễn trừ trách nhiệm: Bao gồm cả quan điểm của bên thứ ba. Đây không phải lời khuyên tài chính. Có thể bao gồm nội dung được tài trợ. Xem Điều khoản & Điều kiện.