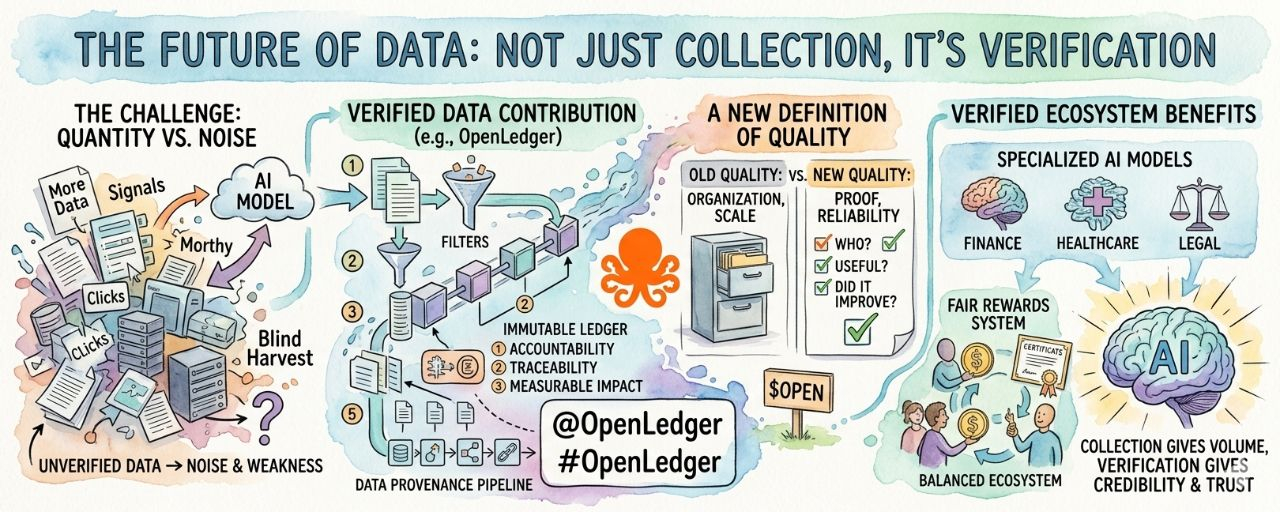
Lâu nay, tôi tin rằng lợi thế lớn nhất trong công nghệ đến từ việc có nhiều dữ liệu. Nhiều người dùng, nhiều cú nhấp chuột, nhiều bản ghi, nhiều cuộc trò chuyện, nhiều tín hiệu. Bất cứ nơi nào tôi nhìn, các công ty đều đua nhau thu thập thông tin ở quy mô khổng lồ như thể chỉ cần số lượng thì có thể tạo ra trí tuệ. Nhưng càng nghiên cứu cách mà các hệ thống AI hiện đại thực sự tiến hóa, tôi càng nhận ra rằng dữ liệu tự nó không còn đủ nữa. Một lượng lớn thông tin có thể nhìn bên ngoài có giá trị nhưng nếu không ai biết nó đến từ đâu, độ tin cậy của nó như thế nào hoặc liệu nó có thực sự cải thiện được một mô hình AI hay không thì dữ liệu đó dần trở thành tiếng ồn thay vì giá trị.
Đó chính là lý do mà các dự án như @OpenLedger đang trở nên ngày càng quan trọng trong tương lai của cơ sở hạ tầng AI. Điều làm cho #OpenLedger thú vị đối với tôi là nó tập trung vào một thứ mà ngành công nghiệp thực sự cần nhưng thường xuyên bị bỏ qua: sự đóng góp dữ liệu đã được xác thực. Thay vì đối xử với dữ liệu như một nguồn tài nguyên vô tận để thu hoạch một cách mù quáng, OpenLedger giới thiệu ý tưởng rằng mỗi đóng góp nên có trách nhiệm, khả năng theo dõi và tác động có thể đo lường. Theo ý kiến của tôi, điều này thay đổi toàn bộ cuộc đối thoại xung quanh trí tuệ nhân tạo.
Hôm nay, internet đã sản xuất nhiều thông tin hơn bất kỳ hệ thống nào có thể xử lý đầy đủ. Vấn đề không phải là sự khan hiếm. Vấn đề là lòng tin. Chúng ta có thể xác minh nguồn gốc của một tập dữ liệu không? Chúng ta có thể chứng minh liệu thông tin nhất định có cải thiện một mô hình hay gây ra thiên lệch không? Các nhà đóng góp có thể được thưởng xứng đáng cho việc cung cấp kiến thức hữu ích không? Những câu hỏi này đang trở nên quan trọng vì AI đang đi sâu hơn vào tài chính, chăm sóc sức khỏe, tự động hóa, giáo dục, nghiên cứu và ra quyết định. Nếu dữ liệu cung cấp cho các hệ thống này không thể được xác thực, thì sự tự tin vào các đầu ra sẽ luôn bị hạn chế.
Đây là nơi mà tôi nghĩ rằng hướng đi của OpenLedger trở nên mạnh mẽ. Dự án không chỉ nói về sự phát triển của AI. Nó đang giải quyết lớp thiếu sót của tính minh bạch trong chính sự phát triển AI. Ý tưởng rằng các nhà đóng góp dữ liệu, các nhà xây dựng mô hình và các thành viên trong hệ sinh thái có thể hoạt động trong một khuôn khổ xác thực tạo ra một nền tảng vững chắc hơn nhiều so với hệ thống hiện tại, nơi mà các nền tảng khổng lồ thu thập thông tin với rất ít trách nhiệm.
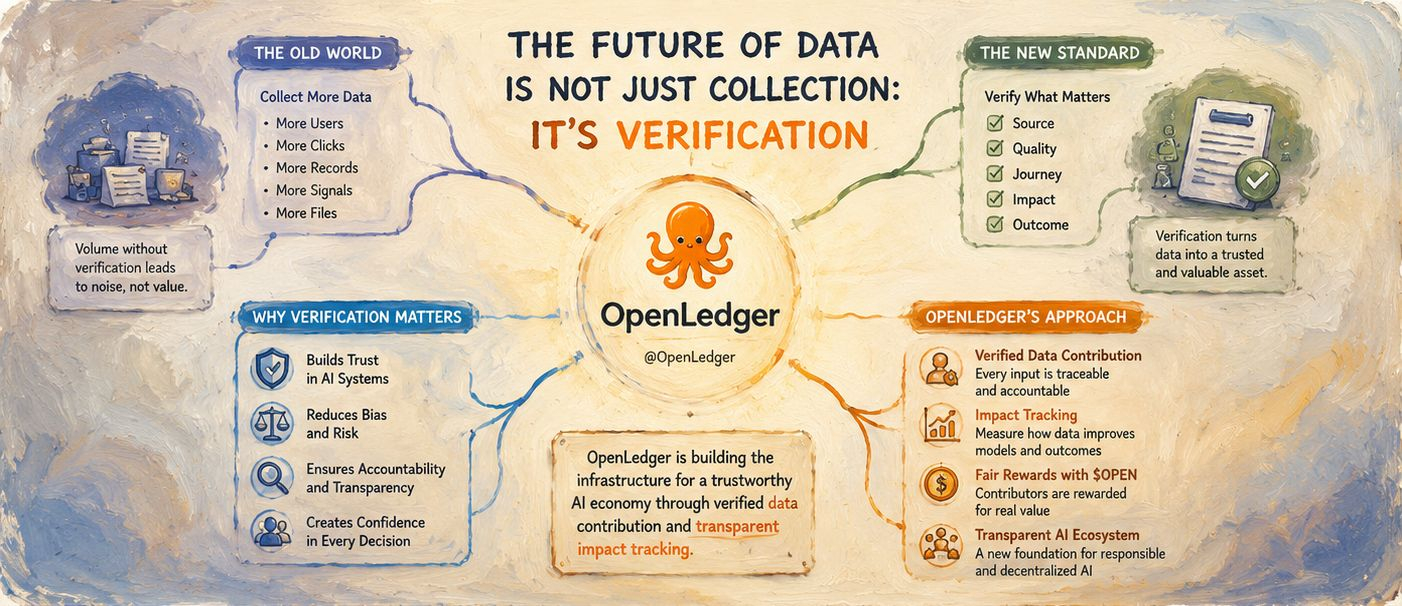
Một điều mà tôi thấy thú vị là cách xác thực hoàn toàn thay đổi ý nghĩa của “dữ liệu chất lượng cao.” Trong các hệ thống cũ, chất lượng chủ yếu có nghĩa là tổ chức, định dạng, quy mô hoặc tính liên quan. Nhưng trong tương lai, chất lượng cũng có nghĩa là bằng chứng. Ai đã đóng góp thông tin? Nó có hữu ích không? Nó có cải thiện kết quả không? Nó có đáng tin cậy theo thời gian không? Những câu hỏi này đang trở nên thiết yếu cho các hệ thống AI mà mọi người thực sự tin tưởng.
Đối với tôi, OpenLedger đại diện cho sự chuyển đổi này từ việc thu thập dữ liệu đơn giản sang trách nhiệm dữ liệu. Nó giống như một sự chuyển mình khỏi mô hình internet cũ, nơi các nền tảng vô tận hấp thụ thông tin mà không đo lường đúng đắn sự đóng góp hoặc độ tin cậy. Thay vào đó, các hệ sinh thái AI đã được xác thực tạo ra một cấu trúc nơi dữ liệu có ngữ cảnh, lịch sử, quyền sở hữu và giá trị có thể đo lường.
Tôi cũng nghĩ điều này quan trọng vì nền kinh tế AI trong tương lai sẽ có thể trở nên cực kỳ chuyên biệt. Các ngành công nghiệp khác nhau sẽ yêu cầu các mô hình khác nhau được đào tạo trên thông tin cực kỳ đáng tin cậy. AI tài chính không thể chấp nhận các tập dữ liệu yếu. AI chăm sóc sức khỏe không thể dựa vào các nguồn không chắc chắn. Tự động hóa pháp lý không thể hoạt động trên thông tin không thể xác minh. Trong tất cả các lĩnh vực này, khả năng truy xuất và xác thực các đường ống dữ liệu trở nên quan trọng hơn việc chỉ tăng quy mô.
Đó là lý do tại sao tôi tin rằng các dự án như @OpenLedger có thể trở nên ngày càng liên quan khi cơ sở hạ tầng AI phát triển. Thế hệ tiếp theo của các nền tảng AI có thể không phải là những hệ thống có tập dữ liệu thô lớn nhất. Họ có thể là những hệ thống thực sự có thể chứng minh tính đáng tin cậy và tính hữu ích của kiến thức mà họ sử dụng. Sự xác thực có thể trở nên có giá trị hơn cả việc thu thập.
Một lý do khác mà ý tưởng này nổi bật với tôi là vì OpenLedger kết nối các động lực với chất lượng đóng góp. Trong nhiều hệ thống truyền thống, các nhà đóng góp cung cấp giá trị trong khi các nền tảng tập trung thu thập hầu hết các phần thưởng. Nhưng các mô hình đóng góp đã được xác thực tạo ra khả năng cho một hệ sinh thái cân bằng hơn, nơi sự tham gia hữu ích thực sự có thể được công nhận và thưởng. Điều đó cảm thấy bền vững hơn cho nền kinh tế AI dài hạn.
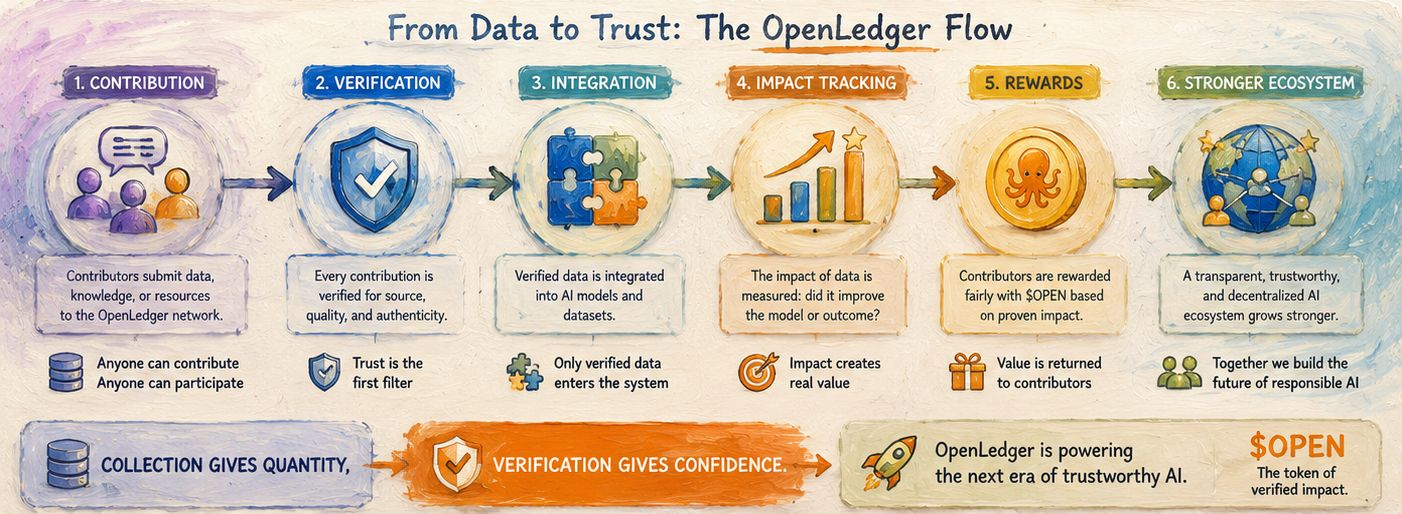
Từ góc nhìn của tôi, tương lai của dữ liệu không còn là về việc tích lũy vô tận nữa. Internet đã giải quyết được vấn đề số lượng. Thách thức tiếp theo là lòng tin. Lòng tin vào nguồn gốc của thông tin, lòng tin vào cách nó được sử dụng và lòng tin rằng các hệ thống được xây dựng dựa trên nó có thể được tin cậy.
Đó là lý do tại sao khái niệm đứng sau #OpenLedger cảm thấy quan trọng đối với tôi. Việc thu thập mang lại cho các hệ thống AI khối lượng, nhưng sự xác thực mang lại cho chúng độ tin cậy. Việc thu thập làm đầy cơ sở dữ liệu nhưng sự xác thực tạo ra sự tin tưởng. Và khi AI trở nên tích hợp hơn vào đời sống hàng ngày, lòng tin cuối cùng sẽ trở nên có giá trị hơn cả quy mô đơn thuần.
Cuối cùng, tôi tin rằng tương lai thuộc về các hệ thống không chỉ thu thập kiến thức mà còn có thể chứng minh tại sao kiến thức đó quan trọng. Đó mới là sự chuyển mình thực sự đang diễn ra trong AI ngay bây giờ, và các dự án như #OpenLedger cùng với $OPEN đang định vị mình trực tiếp xung quanh sự chuyển mình đó.
#OpenLedger
$OPEN
