Hôm qua mình mở tài liệu OpenLedger với ý định chỉ quét qua vài mục và đóng tab lại. Thay vào đó, mình lại bị cuốn vào một thứ hoàn toàn khác.
Vài ngày trước, bộ nhớ điện thoại của mình đầy, nên mình bắt đầu xóa những bức ảnh trùng lặp. Cùng một bức ảnh nằm ở đó ba, bốn, thậm chí năm lần trong các thư mục khác nhau. Thật lãng phí không gian.
Khi đọc về OpenLoRA và ModelFactory, khoảnh khắc ngẫu nhiên đó lại lóe lên trong đầu mình. Điều ở lại với mình không phải là các mô hình lớn hơn hay các thuật ngữ kỹ thuật. Đó là ý tưởng rằng có thể nhiều hệ thống cứ liên tục xây dựng lại và chạy đi chạy lại những thứ giống nhau.
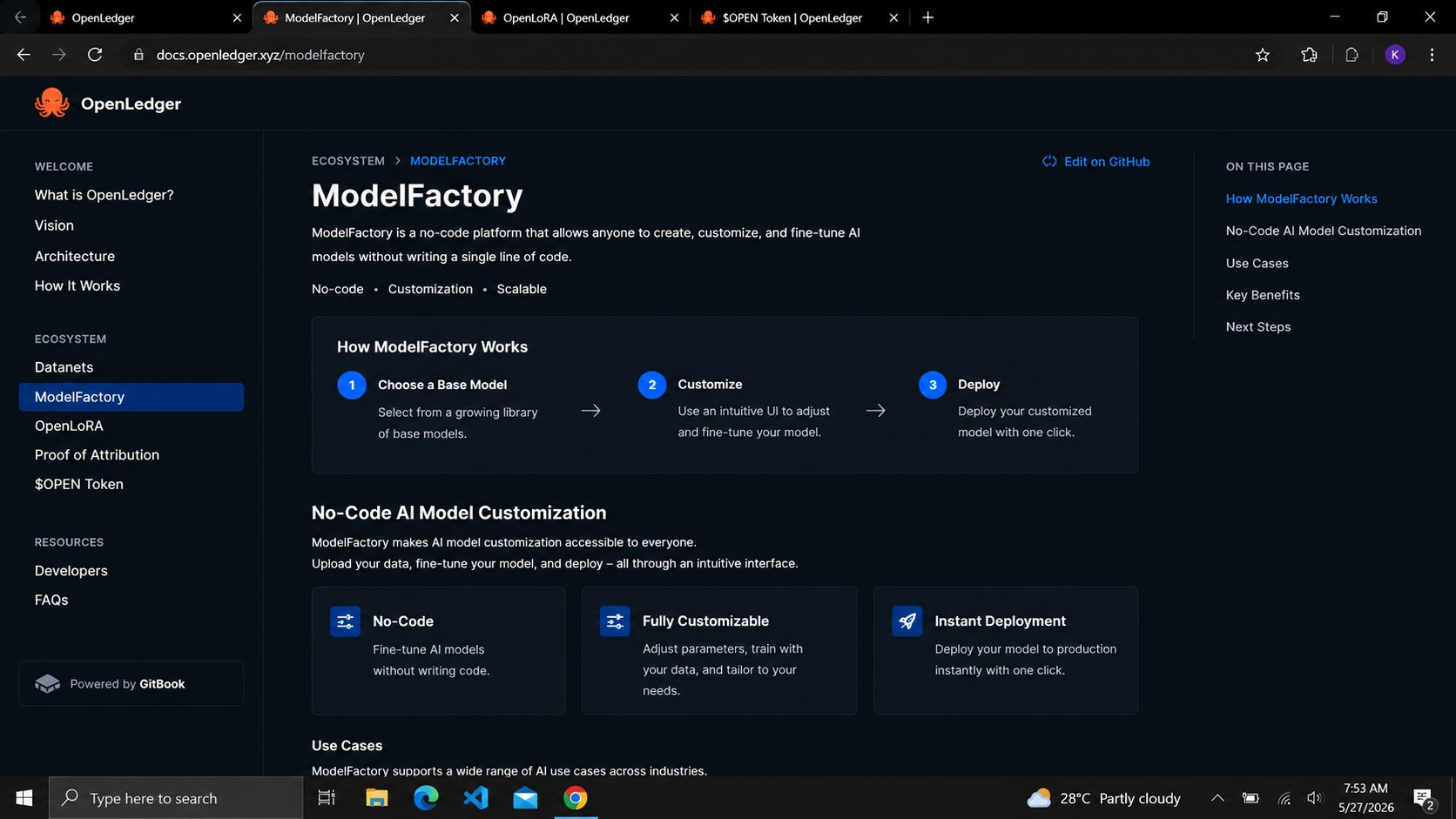
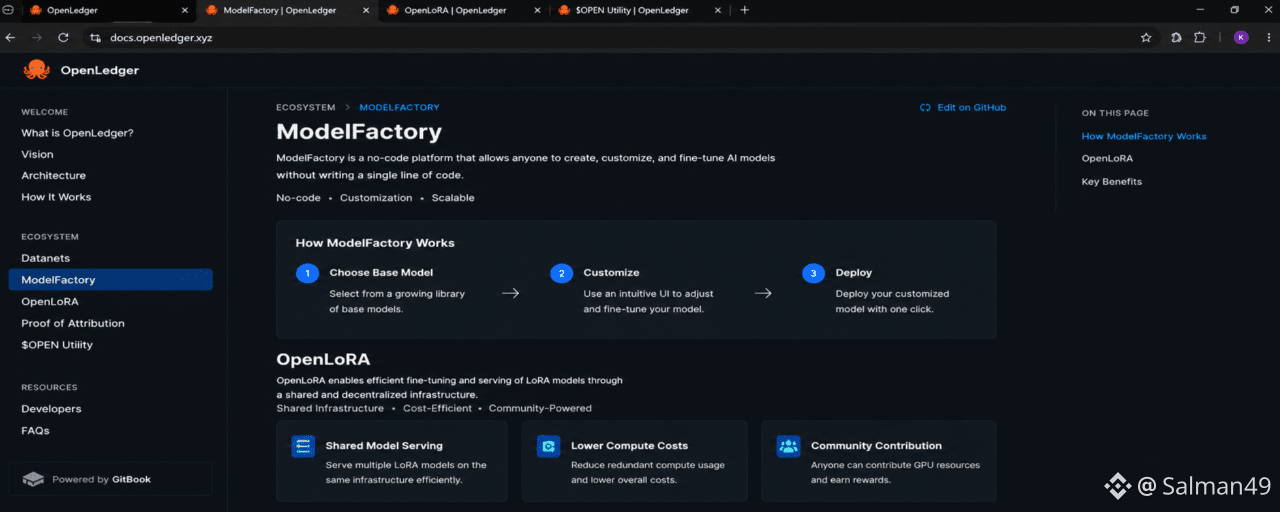
Một chi tiết làm tôi dừng lại lâu hơn. ModelFactory được xây dựng dựa trên việc tùy chỉnh mô hình không cần mã thay vì buộc mỗi nhà phát triển phải trải qua các thiết lập thủ công phức tạp.
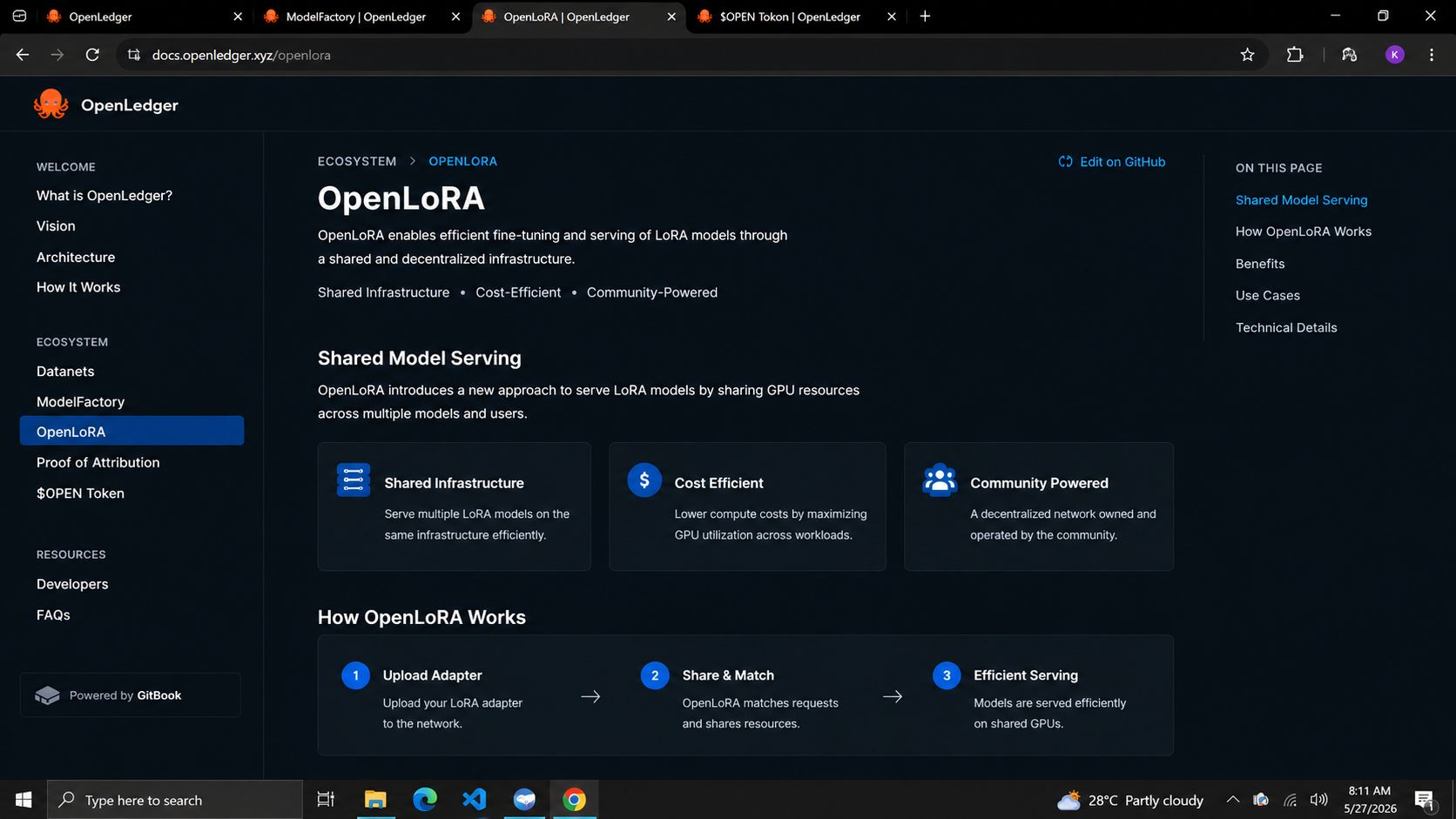
Sau đó, OpenLoRA đã đẩy ý tưởng đi xa hơn. Cơ sở hạ tầng chia sẻ. Phục vụ chung. Giảm thiểu chi phí tính toán lặp lại thay vì các thiết lập mô hình tách biệt chạy riêng lẻ ở khắp nơi.
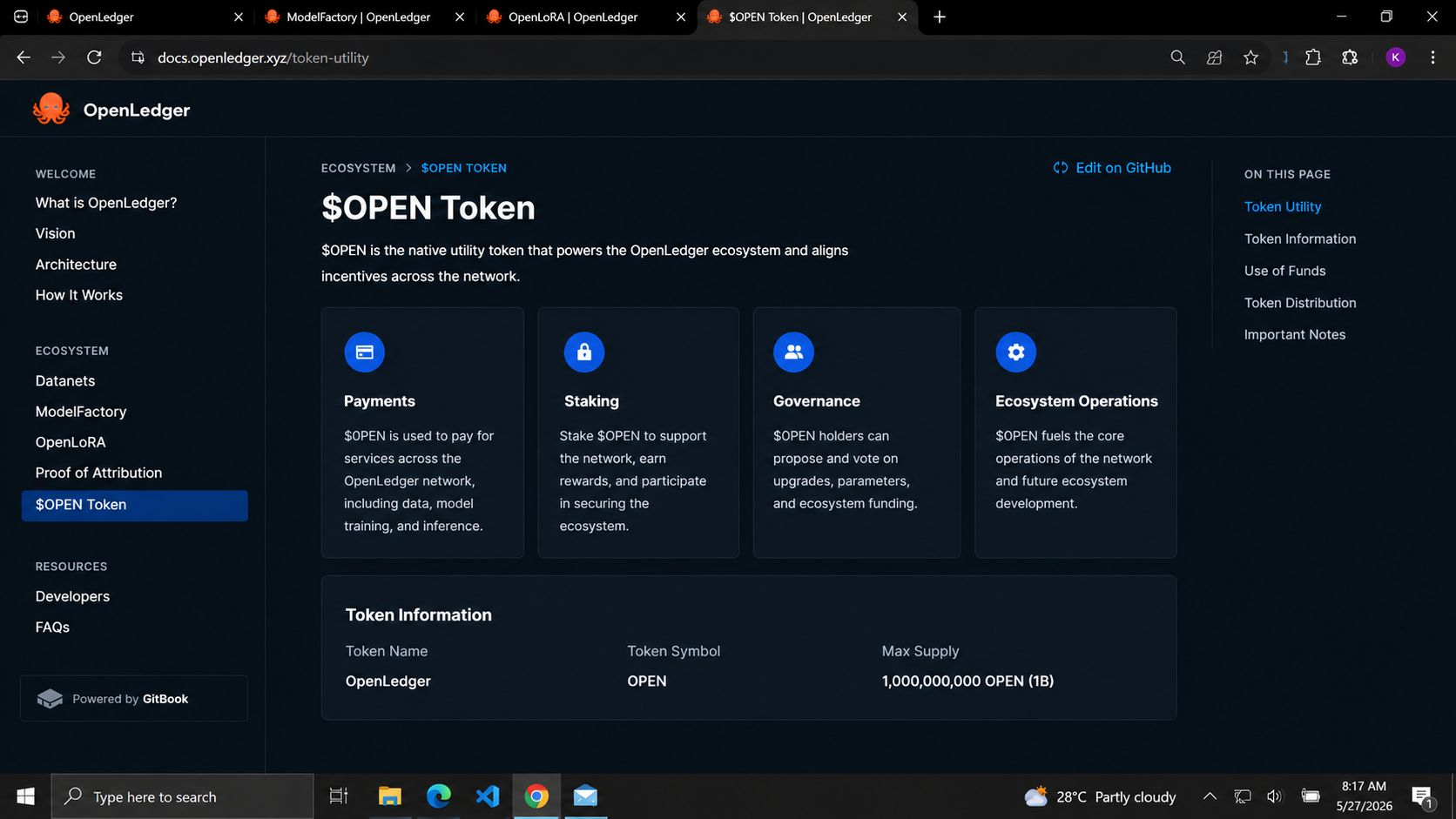
Và bên dưới tất cả điều đó, $OPEN không được định vị như một token ngẫu nhiên gắn với một xu hướng. Tài liệu kết nối nó trực tiếp với hoạt động trong hệ sinh thái như thanh toán, staking, quản trị và hoạt động mạng với tổng cung tối đa là 1B OPEN.
Ý kiến cá nhân của tôi? Có thể sự chuyển mình lớn tiếp theo sẽ không đến từ việc tạo ra nhiều thứ hơn.
Có thể nó sẽ đến từ việc nhận ra có bao nhiêu sự lặp lại không cần thiết đã tồn tại.
Nguồn: Tài liệu OpenLedger. Không phải lời khuyên tài chính. DYOR. @OpenLedger #OpenLedger