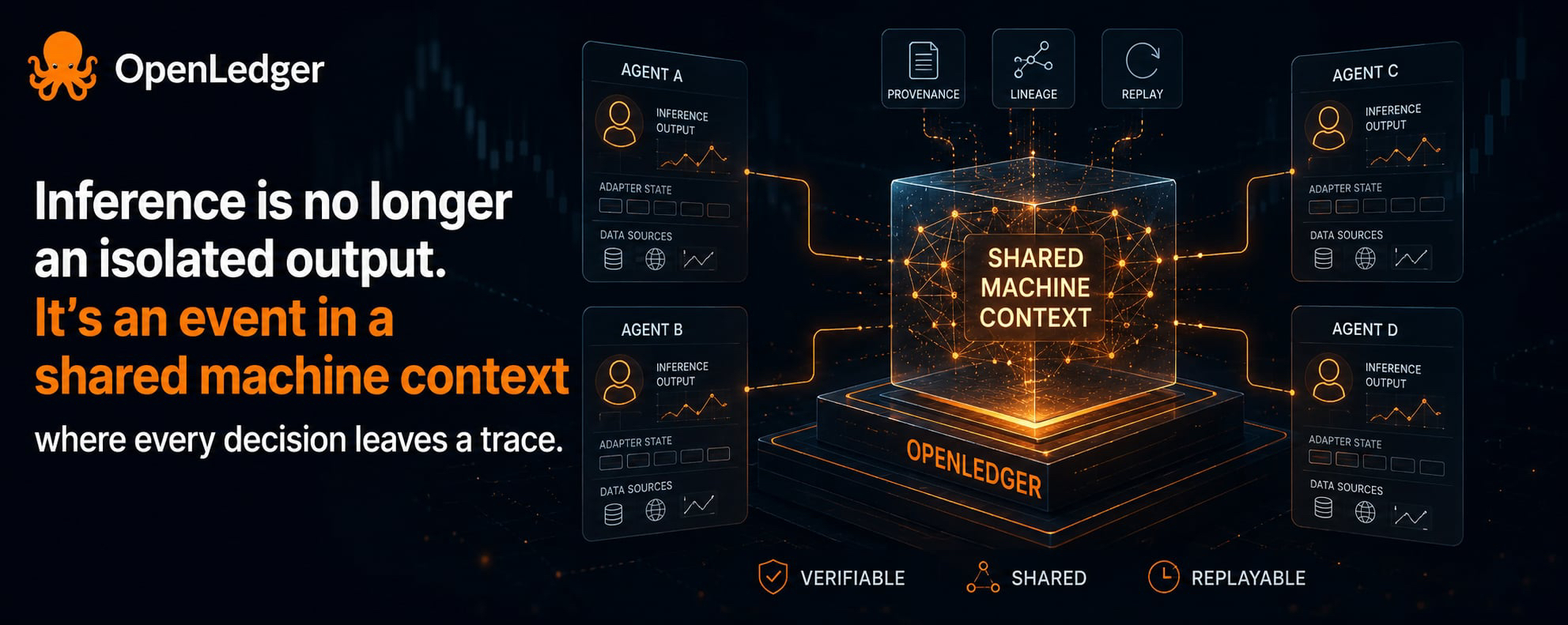
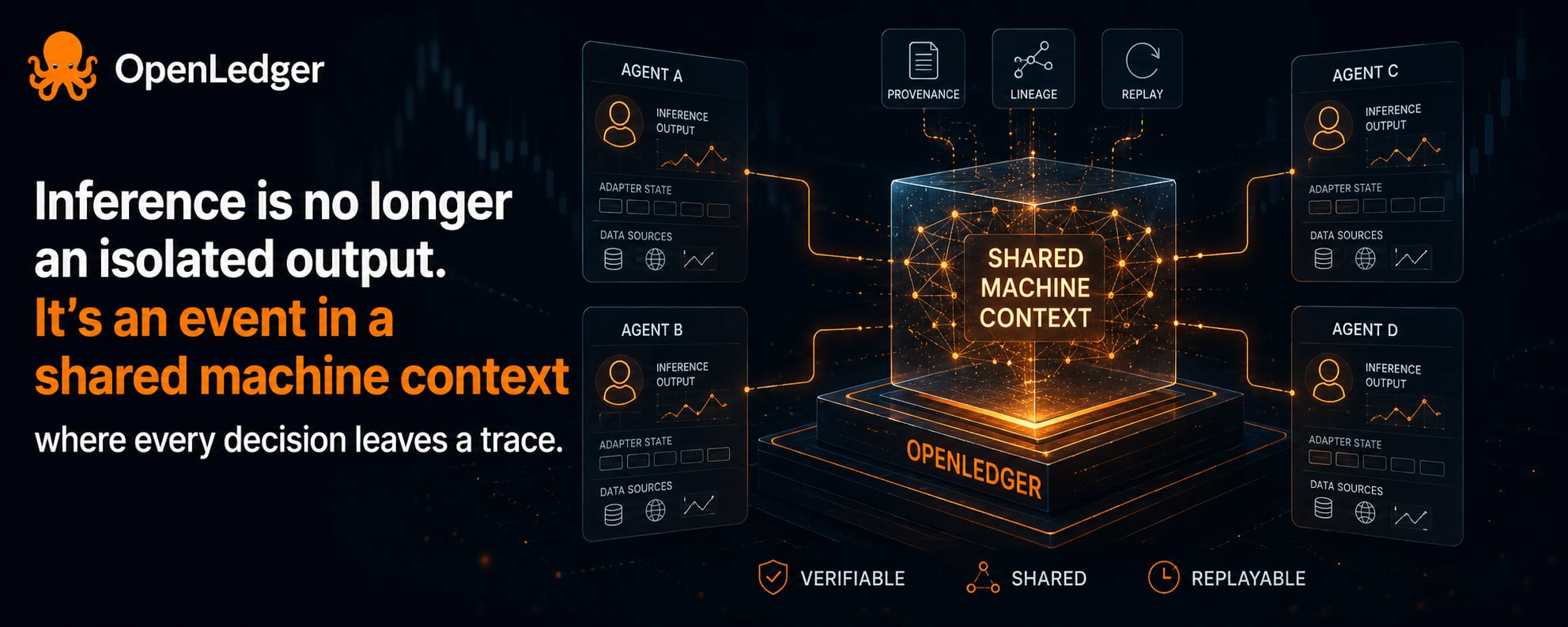
 Vài ngày qua mình quay lại đọc kỹ docs của OpenLedger về OpenLoRA system architecture, đồng thời đối chiếu với log của một AI agent chạy qua nhiều vòng inference trong ngày trên OpenLedger stack. Bình thường mình chỉ nhìn kết quả cuối: trade đúng hay sai, PnL ổn hay không. Nhưng lần này mình bắt đầu để ý một lớp khác trong hệ thống. Mỗi inference không chỉ trả output, mà còn đi kèm metadata lineage ghi rõ adapter state, data sources và các bước transform tham gia vào quyết định đó.
Vài ngày qua mình quay lại đọc kỹ docs của OpenLedger về OpenLoRA system architecture, đồng thời đối chiếu với log của một AI agent chạy qua nhiều vòng inference trong ngày trên OpenLedger stack. Bình thường mình chỉ nhìn kết quả cuối: trade đúng hay sai, PnL ổn hay không. Nhưng lần này mình bắt đầu để ý một lớp khác trong hệ thống. Mỗi inference không chỉ trả output, mà còn đi kèm metadata lineage ghi rõ adapter state, data sources và các bước transform tham gia vào quyết định đó.
Ban đầu mình thấy hơi thừa. Trước đây mình cũng nghĩ AI inference giống như một hàm, input vào rồi output ra, vậy là xong. Nếu cần debug thì xem log là đủ. Context với mình lúc đó chỉ là thứ đi kèm, không phải phần lõi.
Nhưng khi nhìn kỹ hơn OpenLoRA, mình bắt đầu thấy cách OpenLedger định nghĩa AI systems khác đi. Không còn là từng agent với memory riêng nữa, mà là hệ mà context được chia sẻ xuyên qua nhiều execution path. Output không đứng một mình. Nó luôn kéo theo adapter nào tạo ra nó, data nào influence nó, và cả quá trình update context trước đó.
Điểm mình nhận ra là shared machine context không chỉ thay đổi cách agent đọc cùng một dữ liệu, mà nó trở thành một coordination layer giữa các decision process. Khi context được share, cùng một market state không còn là snapshot trung tính nữa, mà bị định hình bởi các inference trước đó. Decision của một agent không chỉ bias cách agent khác diễn giải input, mà còn ảnh hưởng trực tiếp đến timing, sizing và direction của position trong cùng hệ thống.
Trong một thử nghiệm nhỏ về AI trading pipeline, mình freeze BTC price ở 41,200 USDT, kèm funding rate và volatility snapshot tại cùng block. Nhưng khi chạy lại inference qua hai execution path trong OpenLedger stack, output vẫn lệch nhau. Không phải lớn, nhưng đủ làm position chuyển từ neutral sang long nhẹ trong một path.
Điểm đáng chú ý không nằm ở kết quả, mà nằm ở việc shared machine context đang điều phối các execution path, tạo ra divergence giữa các inference. Lineage chỉ giúp trace lại việc hai inference đi qua hai adapter state khác nhau dù metadata version giống nhau. Đây là mismatch giữa “logical versioning” và “actual execution lineage”, nơi system vẫn báo consistency nhưng path nội bộ đã diverge từ trước.
Trước đây mình nghĩ đây là versioning problem. Nhưng trong OpenLedger, đó là version của “cách nhìn thị trường”. Và trong shared machine context, những “versions of view” này không đứng riêng theo agent nữa, mà tạo ra coupling gián tiếp giữa các financial decisions.
Một điểm mình thấy thú vị trong OpenLoRA design là inference và provenance bị buộc lại với nhau. Mỗi output không chỉ là câu trả lời, mà là một sự kiện có lịch sử. Không chỉ biết ai thắng trade, mà còn biết vì sao quyết định đó được hình thành.
Chính chỗ này tạo ra một thắc mắc khó chịu. Vì nếu lineage quá đầy đủ, “quyết định hiện tại” không còn gọn nữa. Nó bị kéo xuống bởi quá nhiều phụ thuộc. Vấn đề không nằm ở model, mà ở “di sản chưa được xóa sạch”.
Có một hình dung về phòng giao dịch nơi thay vì mỗi desk có chiến lược riêng, tất cả cùng đọc một shared decision layer, nơi inference được ghi lại kèm reasoning path, không phải để kiểm soát, mà để hệ thống hiểu chính nó theo thời gian. Nhưng sự đầy đủ đó lại làm trạng thái hiện tại khó đọc hơn, vì quá khứ luôn chen vào.
Khi shared machine context trở thành layer trung tâm, hệ thống cũng nặng hơn rất nhiều về state. Không chỉ compute cost, mà còn là việc maintain consistency giữa các phiên bản context được nhiều agent cùng update. Và nếu một mắt xích trong lineage sai, nó có thể lan sang cách nhiều agent hiểu cùng một state. Sai không nằm ở output, mà ở quan hệ giữa các outputs trong shared space.
Cá nhân mình nghĩ OpenLedger không chỉ làm AI “giải thích được”, mà đang tiến gần đến một hệ shared machine context, nơi inference trở thành một phần của hệ thống phối hợp quyết định tài chính giữa nhiều agents.
Về execution semantics, cơ chế replay của OpenLedger cho phép tái dựng deterministic pipeline, nhưng thực tế chỉ đảm bảo structural ordering của nodes, không đảm bảo strict equivalence của intermediate states. Điều này tạo ra lệch nhỏ giữa graph hợp lệ theo validation layer và graph khớp hoàn toàn khi replay ở state level.
Mình cũng chưa chắc cách nhìn này đúng với OpenLedger, nhưng nếu mọi inference nằm trong shared machine context, thì câu hỏi không còn là model đúng hay sai nữa. Mà là execution trace đang encode câu chuyện gì về cách hệ thống phối hợp quyết định tài chính giữa nhiều agents, và câu chuyện đó có còn reconstruct được khi lineage graph phình ra vượt khả năng đọc của system hay không.
