
Mình đã có một nhận thức lạ khi sử dụng công cụ AI để nghiên cứu: Mình tin tưởng vào kết quả đủ để tiếp tục đọc, nhưng không đủ để giải thích chính xác tại sao mình lại tin tưởng nó.
Khoảng trống đó làm mình bận tâm.
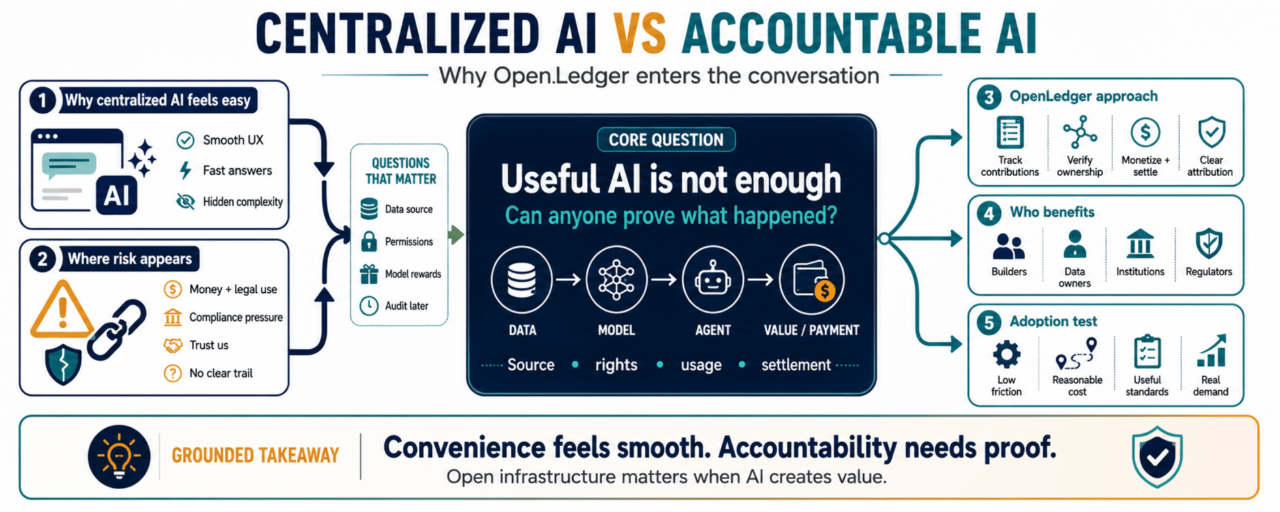
Hầu hết mọi người không đặt câu hỏi về hạ tầng AI khi nhiệm vụ đơn giản. Một bản tóm tắt, một bản nháp, một câu trả lời nhanh, một gợi ý mã. Sự tiện lợi thắng thế. Nhưng khi AI bắt đầu ảnh hưởng đến tiền bạc, quyết định pháp lý, quy trình làm việc của các tổ chức, quyền dữ liệu, hoặc giải quyết vấn đề, câu hỏi sẽ thay đổi.
Không còn là, “Liệu AI có đưa ra câu trả lời hữu ích không?”
Nó trở thành, “Có ai có thể chứng minh điều gì đã xảy ra không?”
Đó là nơi hạ tầng AI tập trung có thể bắt đầu cảm thấy không đầy đủ.
Vấn đề trước OpenLedger
Các nền tảng AI tập trung dễ sử dụng vì chúng che giấu sự phức tạp. Người dùng không cần biết dữ liệu đến từ đâu, mô hình được đào tạo như thế nào, quyền hạn nào đã tham gia, hoặc ai xứng đáng nhận bồi thường.
Điều đó thì ổn cho việc sử dụng thông thường.
Nhưng trong các quy trình làm việc nghiêm túc, sự phức tạp ẩn giấu trở thành mối nguy. Những người xây dựng cần biết liệu họ có thể kiếm tiền từ các mô hình và đại diện của mình mà không mất quyền kiểm soát. Người dùng muốn có niềm tin rằng dữ liệu của họ không bị khai thác. Các tổ chức cần hồ sơ cho việc tuân thủ và kiểm toán. Các nhà quản lý muốn hiểu cách quyết định được đưa ra và ai là người chịu trách nhiệm khi có thiệt hại xảy ra.
Một hệ thống khép kín có thể nói, “Hãy tin chúng tôi.”
Nhưng môi trường pháp lý, tài chính và tổ chức thường cần nhiều hơn thế. Họ cần hồ sơ, quyền lợi, giải quyết và trách nhiệm.
Điều này không phải vì mỗi tương tác AI cần phải ở trên chuỗi. Điều đó sẽ không thực tế. Điểm mấu chốt là một số hoạt động AI tạo ra giá trị kinh tế, và giá trị thường cần một con đường có thể truy xuất.
Sự tiện lợi không giống như sự tin tưởng
AI tập trung mạnh mẽ vì nó cảm thấy mượt mà. Mọi thứ xảy ra sau giao diện. Người dùng hỏi, mô hình trả lời, và nền tảng quản lý phần còn lại.
Nhưng sự tin tưởng trở nên mong manh khi người dùng không thể thấy các mối quan hệ cơ bản.
Ai đã cung cấp dữ liệu?
Dữ liệu có được cấp phép không?
Chủ sở hữu mô hình có nhận được giá trị không?
Có cho phép một đại diện thực hiện hành động đó không?
Kết quả có thể được kiểm toán sau này không?
Người đóng góp có thể chứng minh vai trò của họ không?
Những câu hỏi này trở nên quan trọng hơn khi các hệ thống AI trở nên gắn bó trong công việc thực tế.
Một doanh nghiệp nhỏ có thể sử dụng AI để xem xét hợp đồng. Một ngân hàng có thể sử dụng AI để hỗ trợ phân tích rủi ro. Một công ty chăm sóc sức khỏe có thể sử dụng AI để tổ chức các tài liệu nhạy cảm. Một nhà phát triển có thể xây dựng một đại diện phụ thuộc vào các tập dữ liệu bên thứ ba.
Trong mỗi trường hợp, đầu ra chỉ là một phần của câu chuyện. Quy trình đằng sau nó cũng quan trọng.
Nơi OpenLedger tham gia vào cuộc trò chuyện
Đây là nơi @OpenLedger trở nên liên quan. OpenLedger tập trung vào hạ tầng Blockchain AI giúp mở khóa tính thanh khoản xung quanh dữ liệu, mô hình và đại diện.
Cách tôi hiểu, ý tưởng cốt lõi không chỉ đơn giản là “đưa AI lên blockchain.” Câu này quá mơ hồ. Ý tưởng thực tế hơn là tạo ra hạ tầng nơi các đóng góp liên quan đến AI có thể được theo dõi, sở hữu, kiếm tiền và giải quyết một cách minh bạch hơn.
Điều này quan trọng vì giá trị AI thường được chia sẻ giữa nhiều người đóng góp vô hình.
Một tập dữ liệu có thể cải thiện một mô hình. Một mô hình có thể cung cấp năng lượng cho một đại diện. Một đại diện có thể phục vụ người dùng. Một người xây dựng có thể đóng gói quy trình làm việc. Một tổ chức có thể trả tiền cho đầu ra. Mỗi lớp tạo ra giá trị, nhưng các hệ thống tập trung thường nén giá trị đó vào một mối quan hệ do nền tảng kiểm soát.
OpenLedger có thể cung cấp một cấu trúc khác: nơi các chủ sở hữu dữ liệu, người tạo mô hình, người xây dựng đại diện, người dùng, tổ chức và cuối cùng là các nhà quản lý có đường ray rõ ràng hơn cho việc ghi nhận và phân phối giá trị.
Điều đó không loại bỏ nhu cầu về sản phẩm tốt. Nó không đảm bảo việc áp dụng. Nhưng nó giải quyết một điểm yếu thực sự trong các hệ thống AI tập trung.
Một ví dụ thực tiễn
Hãy tưởng tượng một đại diện nghiên cứu pháp lý được xây dựng cho các công ty vừa và nhỏ.
Nó sử dụng dữ liệu pháp lý công khai, cơ sở dữ liệu có giấy phép, một mô hình chuyên biệt và các tài liệu nội bộ của công ty. Nó giúp người dùng so sánh điều khoản, xác định rủi ro và chuẩn bị tóm tắt cho các luật sư con người.
Trong một thiết lập tập trung, công ty có thể nhận được một câu trả lời hữu ích. Nhưng nếu có tranh chấp sau đó, dấu vết có thể trở nên không rõ ràng. Các nguồn nào đã được sử dụng? Các tài liệu được cấp phép có được truy cập đúng cách không? Đại diện có dựa vào dữ liệu lỗi thời không? Ai sở hữu những cải tiến từ việc sử dụng lặp lại? Ai nhận doanh thu nếu đại diện trở nên được sử dụng rộng rãi?
Với hạ tầng kiểu OpenLedger, các phần của quy trình làm việc này có thể trở nên dễ xác minh hơn. Các chủ sở hữu dữ liệu có thể có các lộ trình kiếm tiền rõ ràng hơn. Những người xây dựng có thể chứng minh việc sử dụng. Các tổ chức có thể duy trì hồ sơ tốt hơn. Các nhà quản lý có thể thấy một mối quan hệ có cấu trúc hơn giữa các đầu vào AI và các đầu ra kinh tế.$PLAY
Mục tiêu không phải là thay thế các luật sư hoặc đội ngũ tuân thủ. Mục tiêu là làm cho các hệ thống AI dễ tin tưởng hơn khi con người cần bảo vệ quyết định của họ.
Mối nguy: phân quyền có thể thêm ma sát
Có một ý kiến phản biện hợp lý ở đây.
AI tập trung thắng lợi vì nó đơn giản. Người dùng thích sự đơn giản. Những người xây dựng thích triển khai nhanh. Các tổ chức thích mối quan hệ nhà cung cấp sạch sẽ. Thêm sở hữu, giải quyết, nguồn gốc và hạ tầng blockchain có thể làm tăng sự phức tạp.
Nếu trải nghiệm cảm thấy chậm, đắt đỏ hoặc khó hiểu, nhiều người sẽ ở lại với các nền tảng tập trung.
Cũng có một vấn đề về tiêu chuẩn. Để hạ tầng như OpenLedger trở nên quan trọng, những người xây dựng và chủ sở hữu dữ liệu cần đồng ý rằng việc ghi nhận và kiếm tiền là xứng đáng để tích hợp. Các tổ chức cần tin rằng các hồ sơ là hữu ích. Các nhà quản lý cần các khung pháp lý công nhận các hệ thống này.
Nếu không có sự phối hợp đó, ý tưởng có thể vẫn mạnh hơn việc áp dụng.
Vì vậy, quan điểm thận trọng là cơ hội của OpenLedger là có thật, nhưng con đường phụ thuộc vào tính khả dụng, chi phí, sự rõ ràng pháp lý và nhu cầu thực tế từ những người xây dựng.
Kết luận thực tế
Những người thực sự sẽ sử dụng OpenLedger có khả năng là những người xây dựng đang tạo ra các đại diện AI, các chủ sở hữu dữ liệu đang tìm kiếm kiếm tiền, các tổ chức cần khả năng kiểm toán và người dùng quan tâm đến nơi các đầu ra AI đến từ.
Nó có thể hoạt động vì hạ tầng AI tập trung tiện lợi nhưng thường yếu về sở hữu, giải quyết và trách nhiệm có thể kiểm chứng. Khi AI tiến vào các quy trình làm việc có giá trị cao hơn, những phần thiếu có thể trở nên khó bỏ qua.$ALT
Nó có thể thất bại hoặc chậm lại nếu người dùng tiếp tục chọn sự tiện lợi thay vì sự minh bạch, nếu những người xây dựng tránh công việc tích hợp, nếu các tổ chức vẫn thoải mái với các nhà cung cấp khép kín, hoặc nếu quy định không thưởng cho các hệ thống có thể kiểm chứng.
Đó là lý do tại sao tôi thấy @OpenLedger và $OPEN như một phần của một câu hỏi lớn hơn: không phải liệu AI sẽ trở nên hữu ích hơn, mà là liệu AI hữu ích có thể trở nên có trách nhiệm hay không.
Không phải là lời khuyên tài chính.
#OpenLedger
Bạn có nghĩ rằng các nền tảng AI tập trung có thể tự giải quyết trách nhiệm hay không, hay AI cần hạ tầng mở cho sở hữu và giải quyết?
Bài viết
AI Tập Trung Có Vẻ Tiện Lợi Cho Đến Khi Trách Nhiệm Xuất Hiện
Tuyên bố miễn trừ trách nhiệm: Nội dung bao gồm cả quan điểm của bên thứ ba, không phải lời khuyên. Có thể sử dụng nội dung do Binance Ai đưa ra nhưng không được đảm bảo. Xem Điều khoản & Điều kiện.