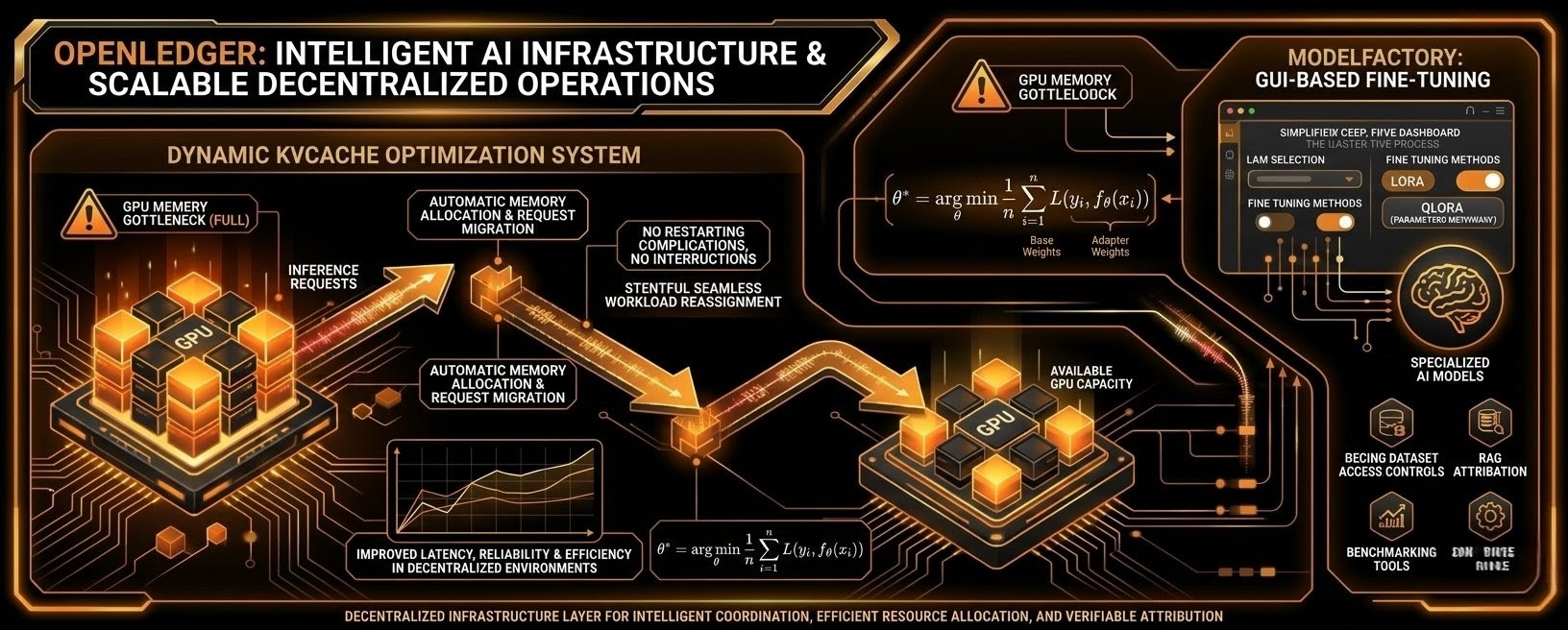
OpenLedger đang xây dựng một hạ tầng nhằm giải quyết một số hạn chế nghiêm trọng mà các hệ thống trí tuệ nhân tạo hiện đại đang gặp phải. Khi các ứng dụng AI ngày càng phức tạp, nhu cầu về quản lý bộ nhớ có khả năng mở rộng, đào tạo mô hình hiệu quả và phối hợp AI phi tập trung đã tăng lên đáng kể. Hạ tầng tập trung truyền thống thường gặp khó khăn với các nút thắt bộ nhớ GPU, phân bổ tài nguyên không hiệu quả và khả năng tiếp cận hạn chế cho các lập trình viên muốn đào tạo hoặc triển khai các mô hình chuyên biệt. OpenLedger giải quyết những vấn đề này thông qua một hệ sinh thái kết hợp di chuyển yêu cầu thông minh, quản lý KvCache tối ưu, hạ tầng tập dữ liệu phi tập trung và các công cụ tinh chỉnh thân thiện với người dùng.
Một trong những thách thức kỹ thuật quan trọng nhất trong suy diễn AI quy mô lớn là tối ưu hóa bộ nhớ. Các Mô hình Ngôn ngữ Lớn phụ thuộc rất nhiều vào việc lưu trữ KvCache trong quá trình suy diễn vì nó lưu trữ các trạng thái chú ý khóa-giá trị đã được tính toán trước đó giúp các mô hình tạo ra phản hồi nhanh hơn và hiệu quả hơn. Tuy nhiên, khi số lượng yêu cầu tăng lên, bộ nhớ GPU có thể nhanh chóng bị bão hòa, dẫn đến sự chậm lại, không ổn định hoặc thậm chí các nhiệm vụ suy diễn thất bại. OpenLedger giới thiệu một hệ thống quản lý KvCache động được thiết kế đặc biệt để ngăn chặn những hạn chế này ảnh hưởng đến hiệu suất hệ thống.
Nền tảng liên tục theo dõi việc sử dụng bộ nhớ GPU và phân bổ lại khối lượng công việc một cách thông minh bất cứ khi nào các ngưỡng công suất được đạt. Thay vì để một GPU đơn lẻ bị quá tải, các yêu cầu tự động được di chuyển đến các tài nguyên tính toán thay thế. Điều khiến quá trình này đặc biệt quan trọng là việc bảo tồn các trạng thái suy diễn trước đó trong quá trình di chuyển. Trong nhiều hệ thống thông thường, việc di chuyển một yêu cầu có thể làm gián đoạn luồng thực thi hoặc yêu cầu tính toán một phần, làm tăng độ trễ và giảm hiệu quả. OpenLedger tránh được vấn đề này bằng cách duy trì tính liên tục trong suy diễn, cho phép các yêu cầu được tiếp tục một cách liền mạch trên phần cứng được gán lại mà không làm gián đoạn trải nghiệm của người dùng.
Kiến trúc di chuyển động này cải thiện đáng kể độ tin cậy và khả năng mở rộng của hệ thống. Khi các ứng dụng AI mở rộng trong các môi trường phi tập trung, việc cân bằng khối lượng công việc trở nên cần thiết để duy trì độ trễ thấp trong suy diễn. Cách tiếp cận của OpenLedger đảm bảo rằng các tài nguyên tính toán được sử dụng hiệu quả hơn trong khi giảm thiểu thời gian ngừng hoạt động và suy giảm hiệu suất. Điều này tạo ra một hạ tầng đáng tin cậy hơn có khả năng hỗ trợ các khối lượng công việc AI ngày càng phức tạp trong các mạng phân phối.
Ngoài tối ưu hóa bộ nhớ, OpenLedger cũng đang định vị mình như một lớp hạ tầng cơ bản cho việc lưu trữ mô hình AI và tích hợp đại lý. Hệ sinh thái được thiết kế để hỗ trợ tương tác liền mạch với các khung đại lý AI hàng đầu, cho phép các nhà phát triển xây dựng các hệ thống AI chuyên biệt và có mục đích hơn. Thay vì chỉ tập trung vào tính toán thô, OpenLedger mong muốn tạo ra một môi trường nơi các đại lý AI có thể hoạt động thông minh hơn thông qua sự phối hợp phi tập trung và công cụ dễ tiếp cận.
Một thành phần chính của hệ sinh thái này là ModelFactory, nền tảng tinh chỉnh nâng cao của OpenLedger cho các Mô hình Ngôn ngữ Lớn. Các quy trình tinh chỉnh truyền thống thường rất kỹ thuật và khó tiếp cận với nhiều nhà phát triển. Hầu hết các giải pháp hiện tại yêu cầu chuyên môn dòng lệnh rộng rãi, tích hợp API phức tạp và quy trình thiết lập hạ tầng khó khăn. Những rào cản này hạn chế sự tham gia và làm chậm đổi mới, đặc biệt đối với các nhóm nhỏ hoặc các nhà phát triển độc lập có thể thiếu tài nguyên kỹ thuật học máy chuyên biệt.
ModelFactory đơn giản hóa quy trình này bằng cách giới thiệu một môi trường tinh chỉnh hoàn toàn dựa trên GUI. Thay vì phụ thuộc vào cấu hình hạ tầng thủ công hoặc thực thi dòng lệnh, người dùng có thể quản lý toàn bộ quy trình làm việc thông qua một giao diện đồ họa trực quan. Điều này giảm đáng kể rào cản kỹ thuật cho việc tùy chỉnh mô hình trong khi cải thiện khả năng tiếp cận cho cộng đồng AI rộng lớn hơn.
Nền tảng này được tích hợp sâu với kho dữ liệu phi tập trung của OpenLedger, đảm bảo truy cập an toàn và có thể xác minh đến dữ liệu đào tạo. Quản trị tập dữ liệu đã trở nên ngày càng quan trọng trong phát triển AI vì chất lượng, độ xác thực và cấu trúc quyền của các tập dữ liệu ảnh hưởng trực tiếp đến hiệu suất và độ tin cậy của mô hình. ModelFactory kết hợp các kiểm soát truy cập tập dữ liệu có quyền giúp duy trì an ninh dữ liệu trong khi hỗ trợ hợp tác phi tập trung.
Kiến trúc đằng sau ModelFactory là mô-đun, cho phép mở rộng quy mô và triển khai linh hoạt trên nhiều trường hợp sử dụng khác nhau. Một trong những thành phần trung tâm của nó là Mô-đun Quản lý Người dùng, xử lý xác thực và quyền truy cập. Điều này đảm bảo rằng chỉ những người dùng được ủy quyền mới có thể tương tác với các tập dữ liệu được bảo vệ hoặc tài nguyên tinh chỉnh. Quản lý bảo mật và quyền truy cập là điều cần thiết trong các hệ sinh thái phi tập trung, nơi nhiều bên tham gia có thể đóng góp dữ liệu, mô hình hoặc tài nguyên tính toán.
Một thành phần quan trọng khác là lớp Kiểm soát Truy cập Tập dữ liệu. Mô-đun này quản lý cách thức các tập dữ liệu được truy xuất và sử dụng trong hệ sinh thái. Bằng cách thực thi các cơ chế truy cập dựa trên quyền, OpenLedger tạo ra một môi trường đáng tin cậy hơn cho việc chia sẻ dữ liệu và đào tạo AI hợp tác. Các tổ chức và nhà phát triển có thể duy trì quyền sở hữu và kiểm soát các tập dữ liệu của họ trong khi vẫn tham gia vào việc phát triển hệ sinh thái rộng lớn hơn.
Tại trung tâm của nền tảng là Động cơ Tinh chỉnh, hỗ trợ các phương pháp tối ưu hóa tiên tiến như LoRA và QLoRA. Các phương pháp tinh chỉnh hiệu quả tham số này đã trở nên ngày càng giá trị vì chúng giảm đáng kể các yêu cầu tính toán liên quan đến việc đào tạo các mô hình ngôn ngữ lớn. Thay vì cập nhật từng tham số trong một mô hình, LoRA giới thiệu các ma trận bộ chuyển đổi nhẹ giúp điều chỉnh hành vi trong khi vẫn giữ nguyên phần lớn cấu trúc mô hình gốc.
Quá trình này có thể được biểu diễn toán học như:
genui{"math_block_widget_always_prefetch_v2":{"content":"y = xW + xAB"}}Trong công thức này, trọng số của mô hình gốc hầu như không thay đổi trong khi chỉ có trọng số của bộ chuyển đổi được cập nhật. Điều này giảm đáng kể mức tiêu thụ bộ nhớ GPU và chi phí đào tạo trong khi vẫn cho phép chuyên môn hóa hiệu quả cho các nhiệm vụ hạ nguồn. QLoRA cải thiện hiệu quả hơn nữa bằng cách tận dụng các kỹ thuật định lượng giúp giảm sử dụng bộ nhớ mà không làm giảm chất lượng mô hình.
ModelFactory cũng tích hợp một Mô-đun Giao diện Trò chuyện thời gian thực cho phép người dùng tương tác trực tiếp với các mô hình đã được tinh chỉnh. Tính năng này đặc biệt hữu ích trong quá trình thử nghiệm và đánh giá vì các nhà phát triển có thể ngay lập tức quan sát cách mà các điều chỉnh đào tạo ảnh hưởng đến phản hồi của mô hình. Tương tác thời gian thực tăng tốc chu trình lặp và cho phép cải thiện nhanh chóng các hệ thống AI.
Một tính năng mạnh mẽ khác trong nền tảng là Mô-đun Ghi nguồn RAG. Sáng tạo Tăng cường Tìm kiếm đã trở thành một trong những tiến bộ quan trọng nhất trong AI hiện đại vì nó cho phép các mô hình truy xuất thông tin bên ngoài liên quan trong quá trình suy diễn. OpenLedger tích hợp các kỹ thuật RAG không chỉ để cải thiện hiệu suất ngữ cảnh mà còn để ghi nguồn. Điều này tăng cường tính minh bạch bằng cách cho phép các đầu ra được tạo ra tham chiếu đến các nguồn thông tin đã đóng góp cho phản hồi. Trong các môi trường nơi niềm tin và khả năng xác minh là rất quan trọng, các cơ chế ghi nguồn ngày càng đóng vai trò quan trọng.
Mô-đun Đánh giá và Triển khai hoàn thành quy trình tinh chỉnh bằng cách cung cấp khả năng đánh giá, xác thực và triển khai. Khi một mô hình đã được đào tạo, các nhà phát triển cần các phương pháp đáng tin cậy để đánh giá hiệu suất của nó trước khi triển khai sản xuất. ModelFactory tự động hóa nhiều phần của quy trình này thông qua các hệ thống đánh giá tích hợp.
Tối ưu hóa tinh chỉnh trong nền tảng tuân theo một mục tiêu toán học có cấu trúc nơi các tham số của mô hình được điều chỉnh để giảm thiểu lỗi dự đoán trên các mẫu đào tạo:
\theta^{*}=\arg\min_{\theta}\frac{1}{n}\sum_{i=1}^{n}L(y_i,f_{\theta}(x_i))
Khung tối ưu hóa này cho phép hệ thống cải thiện hiệu suất của mô hình theo từng bước trong khi cân bằng giữa hiệu quả và độ chính xác.
Để đánh giá các mô hình đã được đào tạo, ModelFactory bao gồm một số chỉ số đánh giá. Các phép đo perplexity và giảm tổn thất giúp đánh giá mức độ hiệu quả của mô hình trong việc dự đoán các đầu ra mục tiêu trên các tập dữ liệu thử nghiệm. Perplexity thấp hơn thường chỉ ra khả năng hiểu ngôn ngữ mạnh hơn và hiệu suất dự đoán token chính xác hơn.
Đối với các ứng dụng tạo văn bản, nền tảng cũng hỗ trợ các phương pháp chấm điểm Rouge và BLEU. Những chỉ số này được sử dụng rộng rãi để đánh giá chất lượng tóm tắt, độ chính xác của bản dịch và sự tương đồng văn bản giữa các đầu ra được tạo ra và các phản hồi tham chiếu. Các hệ thống đánh giá tự động giúp các nhà phát triển so sánh các biến thể mô hình và xác định các cấu hình đào tạo hiệu quả nhất.
Phân tích hiệu quả bộ nhớ GPU là một khả năng đánh giá quan trọng khác, đặc biệt đối với các quy trình tinh chỉnh dựa trên QLoRA. Vì tối ưu hóa bộ nhớ vẫn là một trong những thách thức lớn nhất trong việc triển khai AI quy mô lớn, việc hiểu cách mà các mô hình sử dụng hiệu quả các tài nguyên phần cứng là điều cần thiết cho việc lập kế hoạch hạ tầng có thể mở rộng. Các công cụ phân tích tích hợp của OpenLedger cung cấp cái nhìn về các đặc điểm hiệu suất này, giúp các nhà phát triển tối ưu hóa phân bổ và chiến lược triển khai tài nguyên.
Tổng thể, OpenLedger đang xây dựng nhiều hơn một nền tảng lưu trữ AI tiêu chuẩn. Hệ sinh thái của nó kết hợp hạ tầng phi tập trung, tối ưu hóa bộ nhớ có thể mở rộng, di chuyển yêu cầu hiệu quả, quy trình tinh chỉnh nâng cao và công cụ phát triển dễ tiếp cận vào một khung thống nhất. Bằng cách giải quyết cả những thách thức ở cấp độ hạ tầng và rào cản về tính khả dụng, nền tảng tạo ra một môi trường nơi các nhà phát triển có thể xây dựng, đào tạo và triển khai các hệ thống AI chuyên biệt một cách hiệu quả hơn.
Khi việc áp dụng AI gia tăng trên toàn cầu, tầm quan trọng của hạ tầng phi tập trung, có thể mở rộng và tiết kiệm tài nguyên sẽ tiếp tục tăng lên. Cách tiếp cận của OpenLedger định vị nó như một đóng góp quan trọng cho thế hệ tiếp theo của các hệ sinh thái AI, nơi sự phối hợp thông minh, quản lý dữ liệu minh bạch và tính toán hiệu quả trở thành các yêu cầu cơ bản chứ không phải là những cải tiến tùy chọn.
\u003cc-84/\u003e
