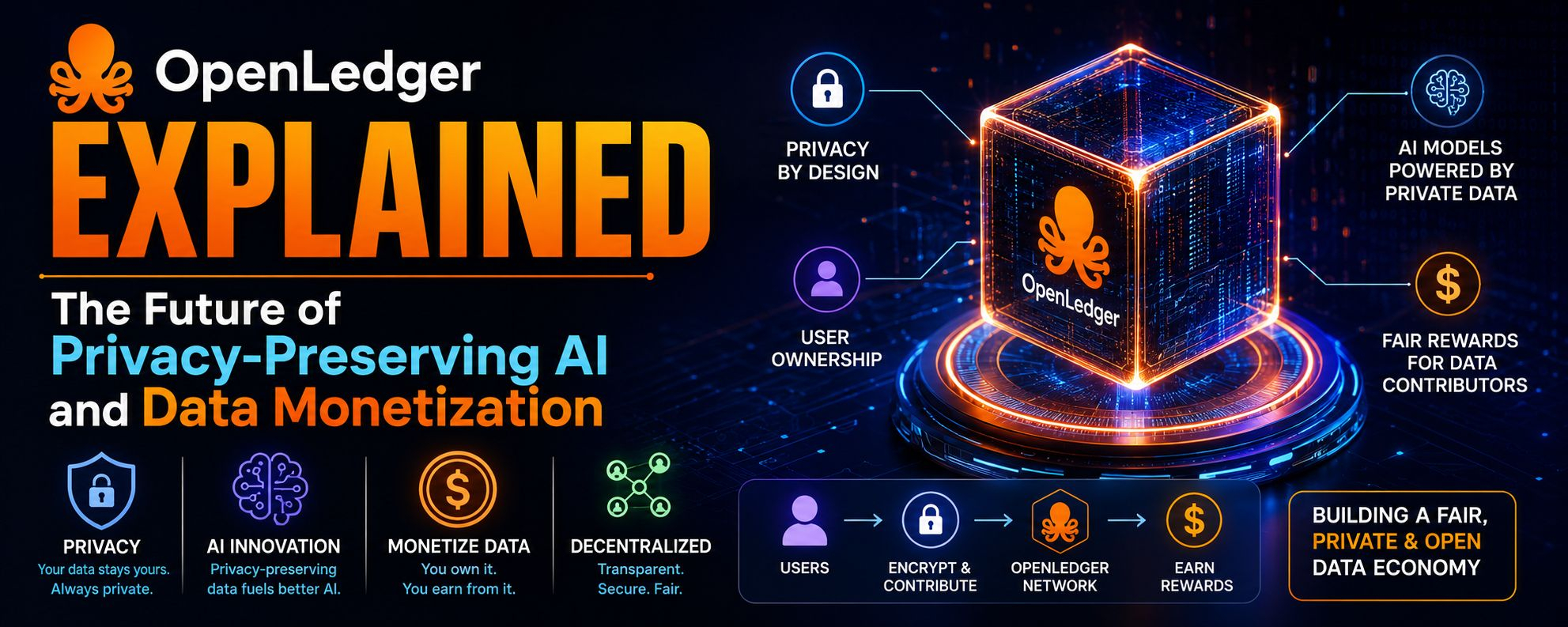
Mình thấy OpenLedger hơn là một sự chuyển mình trong câu chuyện hơn là chỉ là một dự án “AI + blockchain” khác, và ấn tượng đầu tiên mà mình thấy là nó đang cố gắng ngồi đúng ở giao điểm nơi mà sự căng thẳng lớn nhất hiện nay tồn tại: AI muốn có nhiều dữ liệu hơn để trở nên hữu ích, nhưng thế giới thực đang di chuyển theo hướng ngược lại, nơi mà dữ liệu ngày càng bị khóa lại, bị quản lý, và nhạy cảm về quyền riêng tư.
Về mặt cảm xúc, mình thấy ý tưởng này thật sự thú vị nhưng cũng hơi quá lạc quan khi giả định rằng thế giới sẽ phối hợp dễ dàng xung quanh việc kiếm tiền từ dữ liệu. Sự phấn khích đến từ một sự thất vọng rất thực tế mà chúng ta đã thấy trong các ngành như y tế, tài chính và AI doanh nghiệp. Ai cũng có dữ liệu, ai cũng muốn sử dụng AI, nhưng gần như không ai muốn công khai bộ dữ liệu thô nữa. Vì vậy, một hệ thống hứa hẹn rằng “bạn có thể chứng minh giá trị, đào tạo mô hình, hoặc sử dụng tác nhân mà không tiết lộ dữ liệu nhạy cảm cơ bản” cảm giác như một sự tiến hóa tự nhiên. Đồng thời, mình vẫn hoài nghi vì các động lực trong việc sở hữu dữ liệu rất phức tạp, và việc thuyết phục bệnh viện, chính phủ, hoặc các doanh nghiệp lớn chuẩn hóa xung quanh một lớp thanh khoản chung trên chuỗi cho dữ liệu là điều cực kỳ khó khăn trong lịch sử.
Nói một cách đơn giản, hãy tưởng tượng một bệnh viện sử dụng AI để phát hiện ung thư giai đoạn đầu từ các hình chụp. Hôm nay, bệnh viện có thể gửi dữ liệu đến một nhà cung cấp AI tập trung hoặc tự vận hành mọi thứ nội bộ. Cả hai lựa chọn đều có nhược điểm: rủi ro về quyền riêng tư ở một bên, cải thiện mô hình hạn chế ở bên kia. Trong một hệ thống như OpenLedger đang đề xuất, bệnh viện có thể lý thuyết cho phép các mô hình AI học từ các mẫu trong dữ liệu của mình mà không bao giờ tiết lộ hồ sơ bệnh nhân thô, và chỉ chia sẻ các chứng cứ hoặc xác nhận mật mã rằng một mô hình đã được đào tạo đúng cách hoặc được sử dụng đúng. Nghe có vẻ mạnh mẽ, đặc biệt ở những nơi như chẩn đoán, khám phá thuốc, hoặc gen, nơi độ nhạy cảm của dữ liệu cực kỳ cao.
Một ví dụ khác là phát hiện gian lận bảo hiểm. Các công ty bảo hiểm có các tập dữ liệu khổng lồ, nhưng họ hiếm khi chia sẻ chúng vì chúng chứa thông tin cá nhân và được quản lý. Một lớp thực thi AI bảo vệ quyền riêng tư có thể cho phép nhiều công ty bảo hiểm đóng góp vào một mô hình phát hiện gian lận chung trong khi giữ dữ liệu ở cấp độ khách hàng ẩn danh. Loại tiết lộ chọn lọc đó là nơi mà khái niệm trở nên nhiều hơn chỉ là lý thuyết và bắt đầu cảm thấy có giá trị trong vận hành.
Điều mà OpenLedger đang cố gắng giải quyết ở cốt lõi là ba vấn đề chồng chéo. Đầu tiên là sự không sử dụng dữ liệu, nơi mà các tập dữ liệu quý giá nằm không hoạt động vì không thể chia sẻ an toàn. Thứ hai là việc gán mô hình AI, có nghĩa là ai thực sự đã đóng góp dữ liệu, tính toán, hoặc nỗ lực đào tạo cho một hệ thống AI. Thứ ba là sự ma sát trong việc kiếm tiền, nơi mà hiện nay không có một thị trường sạch sẽ nào nơi dữ liệu, mô hình và đại lý có thể được định giá, theo dõi, và thưởng một cách minh bạch mà không có các phức tạp pháp lý và quyền riêng tư liên tục cản trở.
Người dùng dự kiến không phải là người dùng thông thường. Rõ ràng nó đang nhắm đến các doanh nghiệp, nhà phát triển AI, nhà cung cấp dữ liệu, và các nhà vận hành hạ tầng. Về lý thuyết, các bệnh viện, phòng thí nghiệm nghiên cứu, công ty fintech, và thậm chí các nhà phát triển đại lý AI tự động sẽ là những người hưởng lợi chính. Sự thuận tiện mà nó hứa hẹn về cơ bản là một lớp phối hợp nơi bạn không cần phải thương lượng thủ công từng thỏa thuận chia sẻ dữ liệu hoặc xây dựng các đường ống AI riêng biệt cho từng đối tác. Thay vào đó, bạn kết nối vào một hệ thống chung nơi quyền truy cập, chứng cứ, và trao đổi giá trị được xử lý theo chương trình.
Từ góc độ chức năng, ý tưởng quan trọng nhất là “tầm nhìn có kiểm soát.” Thay vì dữ liệu thô được chia sẻ, những gì được chia sẻ là kết quả tính toán có thể xác minh, chứng cứ sử dụng, hoặc đầu ra mô hình liên kết với trách nhiệm mật mã. Nếu điều này hoạt động như mong muốn, nó giảm ma sát trong các môi trường được quản lý trong khi vẫn cho phép các hệ thống AI cải thiện thông qua các tín hiệu học tập rộng hơn. Đó là một lợi thế khái niệm rất mạnh mẽ trong một thế giới nơi quy định về quyền riêng tư như các khung GDPR đang trở nên nghiêm ngặt hơn toàn cầu.
Nhìn vào các xu hướng rộng hơn đến thời điểm hiện tại vào năm 2026, cơ sở hạ tầng AI đang nhanh chóng chuyển hướng sang tính toán bảo vệ quyền riêng tư, không chỉ đào tạo tập trung. Các kỹ thuật như học tập liên kết, khu vực bảo mật, và chứng minh không biết đang chuyển từ thử nghiệm sang sử dụng sản xuất sớm, đặc biệt trong lĩnh vực chăm sóc sức khỏe và phân tích tài chính. Trong khi đó, các hệ thống blockchain đang gặp khó khăn trong việc tìm kiếm tiện ích thực sự ngoài đầu cơ, vì vậy bất kỳ dự án nào kết nối blockchain với một khối lượng công việc AI thực sự như gán dữ liệu hoặc cấp phép mô hình có một câu chuyện hợp lý hơn so với DeFi thuần túy. Tuy nhiên, thực tế là việc áp dụng vẫn còn sớm. Hầu hết các doanh nghiệp đang thử nghiệm nhưng chưa cam kết hoàn toàn vào các thị trường AI phi tập trung.
Tương lai có tiềm năng, nếu OpenLedger thực hiện tốt, có thể rất lớn. Nó có thể tạo ra một lớp mà dữ liệu đào tạo AI trở thành một loại tài sản có thể theo dõi và bồi thường. Điều đó sẽ thay đổi cơ bản các động lực cho những người tạo dữ liệu và thậm chí có thể dẫn đến các mô hình kinh tế mới nơi mà các tập dữ liệu nhỏ trở nên có giá trị nếu chúng có chất lượng cao và có thể sử dụng hợp pháp. Nó cũng có thể làm cho các đại lý AI đáng tin cậy hơn trong các môi trường được quản lý vì các quy trình quyết định của chúng sẽ có thể kiểm toán mà không tiết lộ các đầu vào nhạy cảm.
Nhưng các giới hạn cũng nghiêm trọng không kém. Giới hạn lớn nhất là sự phức tạp trong phối hợp. Để các tổ chức thực tế đồng ý về các tiêu chuẩn chia sẻ dữ liệu bảo vệ quyền riêng tư, hệ thống chứng minh, và động lực token hóa là cực kỳ khó. Một rủi ro khác là chi phí hiệu suất. Tính toán bảo vệ quyền riêng tư vẫn tốn kém hơn và chậm hơn so với xử lý tập trung truyền thống. Sau đó có vấn đề blockchain cổ điển: nếu lớp token hoặc động lực trở nên quan trọng hơn tiện ích thực tế, hệ thống có thể trôi vào đầu cơ thay vì áp dụng thực sự. Và cuối cùng, có sự không chắc chắn về quy định. Ngay cả khi dữ liệu không được tiết lộ trực tiếp, các nhà quản lý vẫn có thể có lo ngại về suy diễn xuyên biên giới hoặc rò rỉ dữ liệu gián tiếp.
Vì vậy, kết luận chân thành của tôi là như thế này. OpenLedger cảm giác như đang chỉ ra một tương lai cấu trúc thực sự của cơ sở hạ tầng AI, nơi dữ liệu không được chia sẻ trực tiếp nhưng vẫn trở nên hoạt động kinh tế thông qua các chứng cứ, quyền hạn, và tính toán có kiểm soát. Ý tưởng này phù hợp với hướng đi của chăm sóc sức khỏe, tài chính, và AI doanh nghiệp. Nhưng khoảng cách giữa tầm nhìn và triển khai thực tế vẫn còn rộng, và thành công sẽ phụ thuộc ít vào sự tinh tế của công nghệ và nhiều hơn vào việc các tổ chức có thực sự tin tưởng và tích hợp nó vào các hoạt động hàng ngày của họ hay không. Theo nghĩa đó, nó ít hơn một sản phẩm hoàn thiện ngày hôm nay và nhiều hơn một cược vào cách mà thế hệ tiếp theo của các tiêu chuẩn cơ sở hạ tầng AI sẽ được định nghĩa.
\u003cm-34/\u003e \u003ct-36/\u003e \u003cc-38/\u003e
