
Trước đây, tôi từng nghĩ hầu hết các dự án “AI blockchain” chỉ là những gói khác nhau cho cùng một ý tưởng. Tên mới, hứa hẹn như cũ. Phân quyền ở đây, hợp đồng thông minh ở đó, và ở đâu đó giữa chừng là một câu chuyện về quyền sở hữu mà chưa bao giờ cảm thấy hoàn chỉnh.
Nhưng gần đây, khi đọc lại về OpenLedger, tôi thấy mình chậm lại. Không phải vì nó thú vị theo cách ồn ào, mà vì có điều gì đó trong cấu trúc của nó cảm thấy… có chủ đích một cách khác thường. Như thể nó không cố gắng thêm một lớp khác vào AI, mà thầm lặng suy nghĩ lại về AI là gì trong các thuật ngữ kinh tế.
Và suy nghĩ đó không dễ dàng rời bỏ. Ban đầu, tôi không thực sự hiểu tại sao mọi người lại gọi nó là “pro”. Từ này nghe có vẻ quá bình thường cho một cái gì đó tuyên bố ngồi giữa cơ sở hạ tầng AI và hệ thống blockchain. Nhưng sau đó tôi bắt đầu nhận thấy những gì nó thực sự cố gắng chạm tới. Không phải hiệu suất. Không phải sự phấn khích. Mà là ghi nhận.
Và điều đó thay đổi mọi thứ.
Trong hầu hết các hệ thống AI ngày nay, chúng ta tương tác với một cái gì đó cảm thấy đã hoàn thành. Một mô hình đưa ra một đầu ra, và chúng ta chấp nhận nó như một sản phẩm của một quá trình đào tạo vô hình nào đó. Chúng ta không thấy những người đóng góp dữ liệu. Chúng ta không thấy các bước tinh chỉnh. Chúng ta không thấy các lớp kinh tế ở bên dưới. Nó cảm thấy sạch sẽ trên bề mặt, nhưng gần như quá sạch sẽ.
Đó là giả định đầu tiên của tôi: AI chỉ là trí thông minh được cung cấp như một dịch vụ. Đơn giản đủ.
Nhưng OpenLedger dường như bắt đầu từ một giả định hoàn toàn khác. Nó coi AI không phải là một sản phẩm tĩnh, mà là một hệ thống được xây dựng từ nhiều đóng góp vô hình mà không nên mãi mãi nằm trong bóng tối. Đó là nơi suy nghĩ của tôi bắt đầu thay đổi. Bởi vì khi bạn chấp nhận rằng đầu ra của AI không được tạo ra trong sự cô lập, câu hỏi tiếp theo trở nên khó chịu.
Ai thực sự sở hữu nó?
Không phải về mặt pháp lý, mà về mặt cấu trúc. Không phải trong lý thuyết, mà trong đóng góp có thể theo dõi.
Và đó là nơi OpenLedger giới thiệu ý tưởng cốt lõi của nó: Chứng nhận Ghi nhận. Ban đầu, tôi nghĩ đó chỉ là một cơ chế xác minh khác. Nhưng càng tìm hiểu sâu, tôi càng cảm thấy nó như một cái gì đó hoàn toàn khác. Chứng nhận Ghi nhận không chỉ theo dõi việc sử dụng - nó đang cố gắng truy tìm ảnh hưởng. Nó cố gắng trả lời một câu hỏi tinh tế nhưng quan trọng: bộ dữ liệu nào, đầu vào nào, và đóng góp nào thực sự định hình phản ứng của mô hình này? Và nếu điều đó có thể được thực hiện một cách đáng tin cậy, thì AI sẽ không còn là một hộp đen của việc khai thác giá trị và bắt đầu trở thành một hệ thống nơi đóng góp có thể được đo lường theo thời gian thực.
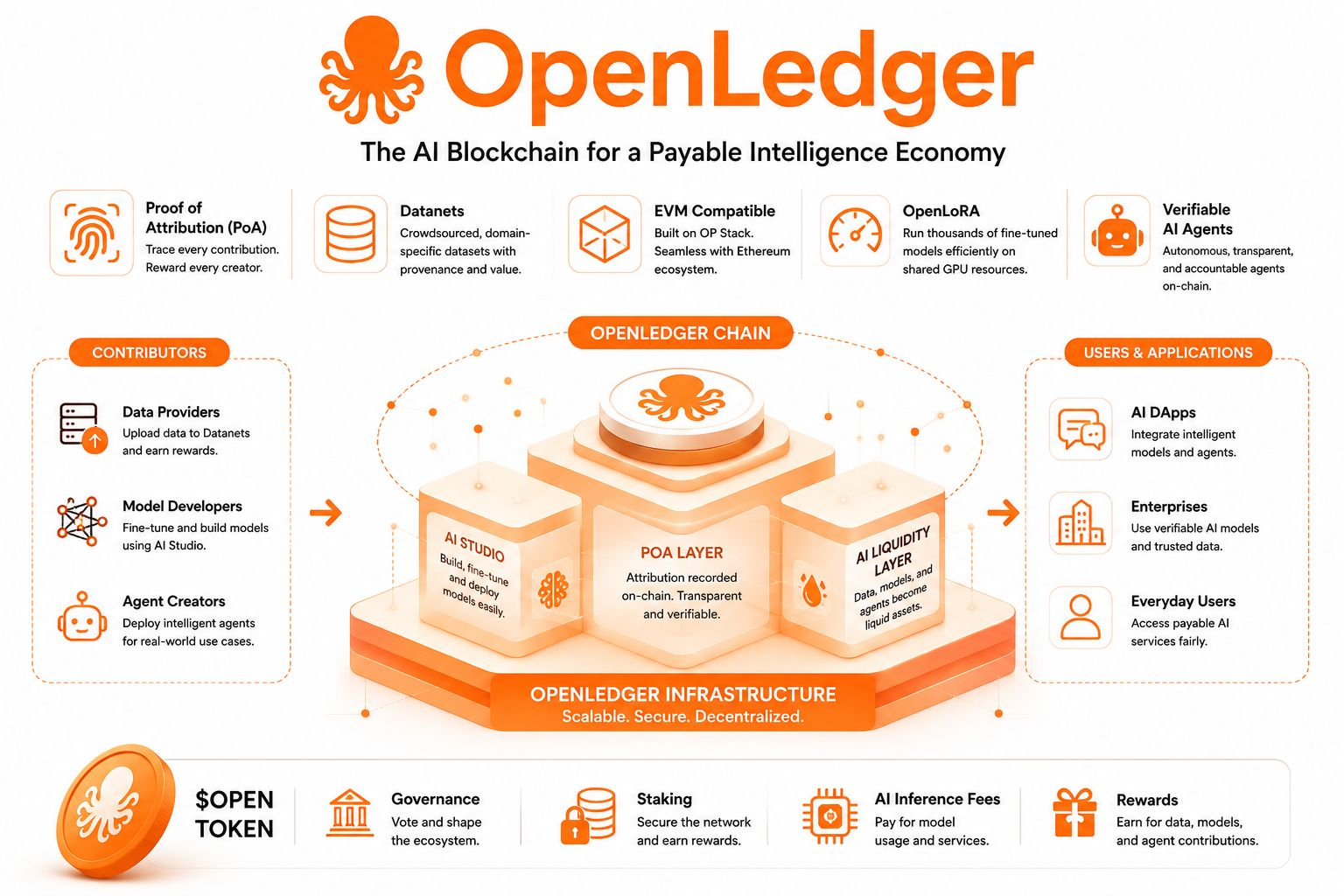 Điều đó khiến tôi dừng lại.
Điều đó khiến tôi dừng lại.
Bởi vì nếu việc ghi nhận trở nên chính xác đủ, thì các hệ thống thưởng trong AI không cần phải gián tiếp nữa. Chúng có thể trở nên ngay lập tức, gần như liên tục. Mỗi khi một mô hình được sử dụng, hệ thống có thể, lý thuyết mà nói, phân phối giá trị trở lại cho các nguồn đã làm cho đầu ra đó trở nên khả thi. Tôi có thể sai, nhưng điều đó cảm thấy như một sự chuyển mình âm thầm trong cách mà lao động kỹ thuật số được định nghĩa.
Sau đó tôi đi sâu hơn vào cách OpenLedger cấu trúc dữ liệu của nó, và tôi đã gặp phải một cái gì đó cảm thấy thực tế hơn: Datanets.
Ý tưởng nghe có vẻ đơn giản ban đầu - các bộ dữ liệu cụ thể theo lĩnh vực được crowdsourced. Tài chính, chăm sóc sức khỏe, nghiên cứu, và nhiều hơn nữa. Nhưng hàm ý thì thú vị hơn định nghĩa. Thay vì phụ thuộc vào các bộ dữ liệu tập trung khổng lồ thuộc sở hữu của một vài tổ chức, Datanets cho phép các bộ dữ liệu nhỏ hơn, có mục đích tồn tại với nguồn gốc kèm theo. Bất kỳ ai cũng có thể đóng góp, nhưng quan trọng hơn, bất kỳ ai cũng có thể chứng minh điều họ đã đóng góp. Nó cảm thấy như dữ liệu ngừng là một nguồn lực im lặng và trở thành cái gì đó gần với một thị trường sống. Và các thị trường, theo bản chất, yêu cầu các quy tắc về quyền sở hữu và trao đổi. Đó là nơi hệ thống bắt đầu cảm thấy ít giống một dự án AI và nhiều hơn như một cấu trúc kinh tế được xây dựng xung quanh trí thông minh chính nó.
Sau đó tôi nhận thấy một lớp khác: khả năng tương thích EVM.
Nhìn qua, điều này có vẻ kỹ thuật, gần như tiêu chuẩn trong thiết kế blockchain hiện đại. Nhưng trong bối cảnh, nó quan trọng hơn những gì nó thể hiện. #OpenLedger được xây dựng với tiêu chuẩn EVM và OP Stack có nghĩa là nó không tách biệt bản thân khỏi hệ sinh thái Ethereum hiện có. Nó kết nối với nó. Ví điện tử, hợp đồng thông minh, và cơ sở hạ tầng nhà phát triển hiện có có thể kết nối mà không gặp rắc rối. Nhưng ý nghĩa sâu xa hơn không phải là khả năng tương thích - mà là khả năng tiếp cận tham gia.
Bởi vì nếu việc ghi nhận, đóng góp dữ liệu và sử dụng mô hình đều gắn liền với một hệ thống tương thích EVM, thì hoạt động AI trở thành một cái gì đó có thể được theo dõi và tương tác với bằng các công cụ mà các nhà phát triển đã hiểu. Nó giảm bớt rào cản giữa logic blockchain và các hệ thống AI. Và điều đó quan trọng hơn những gì nó có vẻ ở lần đầu tiên.
Sau đó có một cái gì đó cảm thấy hoạt động hơn: OpenLoRA. Đây là nơi mà hệ thống bắt đầu cảm thấy ít lý thuyết hơn và thực tiễn hơn.
#OpenLoRA cho phép triển khai hiệu quả các mô hình AI tinh chỉnh bằng cách cho phép nhiều mô hình chuyên biệt chia sẻ tài nguyên GPU. Thay vì mỗi mô hình yêu cầu cơ sở hạ tầng tính toán nặng nề, tách biệt, hệ thống tối ưu hóa cách những mô hình này cùng tồn tại.
Điều khiến tôi ấn tượng ở đây không chỉ là hiệu quả. Mà là khả năng mở rộng của sự chuyên biệt. Nếu hàng ngàn mô hình ngách có thể tồn tại mà không cần chi phí lớn, thì AI sẽ không còn bị thống trị bởi vài gã khổng lồ tổng quát. Nó trở nên phân mảnh thành nhiều hệ thống nhỏ hơn, được xây dựng với mục đích cụ thể.
Và sự phân mảnh thay đổi cách phân phối quyền lực. Bởi vì bây giờ, giá trị không còn tập trung chỉ vào các mô hình nền tảng lớn, mà cũng vào các hệ thống nhỏ, tinh chỉnh được xây dựng bởi những người đóng góp nhỏ hơn. Sau đó tôi gặp phải một cái gì đó thú vị hơn nữa: Các Đại lý AI có thể xác minh. Đây là nơi mọi thứ bắt đầu cảm thấy hơi tương lai, nhưng theo cách thực tiễn. OpenLedger cho phép các tác nhân tự động hoạt động trong một môi trường nơi logic và dòng dữ liệu của chúng được ghi lại trên chuỗi. Điều đó có nghĩa là hành vi của chúng không chỉ được thực hiện - mà còn có thể quan sát được. Và nếu một cái gì đó có thể quan sát được, nó có thể được đánh giá. Điều đó giới thiệu một khả năng kỳ lạ: các tác nhân hành xử không hiệu quả hoặc sai lệch không chỉ thất bại nội bộ - chúng trở nên có thể nhận diện như một phần của một hệ thống mạng. Không chỉ là xây dựng các tác nhân. Mà là tạo ra trách nhiệm cho hành vi tự động. Điều đó khiến tôi nhận ra một điều tinh tế. Hầu hết các hệ thống AI tối ưu hóa cho chất lượng đầu ra. OpenLedger dường như cũng quan tâm đến khả năng truy nguyên hành vi. Đó không phải là cùng một điều. Sau đó có Nhà Máy Mô hình, mà gần như cảm thấy như là điểm khởi đầu cho người dùng không chuyên môn. Một môi trường không mã nơi người dùng có thể tải lên dữ liệu, chọn các mô hình cơ bản, và tinh chỉnh chúng cho các trường hợp sử dụng cụ thể.
Ban đầu, tôi nghĩ đây chỉ là một tính năng sử dụng. Nhưng trong bối cảnh, nó giống như một cổng kinh tế hơn. Bởi vì nếu bất kỳ ai cũng có thể tạo ra một mô hình, thì việc tạo ra mô hình trở thành lao động phân phối. Không giới hạn cho các nhà nghiên cứu hoặc công ty lớn. Và nếu những mô hình đó gắn liền với hệ thống ghi nhận và thưởng, thì việc xây dựng mô hình trở thành một hình thức đóng góp có thể kiếm tiền. Đó là nơi token $OPEN bước vào hệ thống - không phải như một yếu tố đầu cơ, mà như một lớp phối hợp. Nó được sử dụng cho quản trị, staking, phí sử dụng, và phân phối phần thưởng. Nhưng quan trọng hơn, nó trở thành phương tiện mà qua đó các loại đóng góp khác nhau - dữ liệu, tính toán, sử dụng mô hình - được liên kết vào một dòng chảy kinh tế duy nhất. Và tôi bắt đầu nhận thấy một mẫu ở đây. OpenLedger không chỉ xây dựng công cụ. Nó đang xây dựng một cách để đo lường sự tham gia trong các hệ thống AI. Điều đó có thể nghe có vẻ đơn giản, nhưng không phải vậy. Bởi vì việc đo lường là điều biến sự tham gia thành kinh tế. Tuy nhiên, có một sự căng thẳng mà tôi không thể bỏ qua. Càng cố gắng làm cho việc ghi nhận AI trở nên chính xác, hệ thống càng trở nên phức tạp. Và sự phức tạp có cái giá của nó. Nó có thể giảm khả năng tiếp cận. Nó có thể làm chậm việc áp dụng. Nó có thể tạo ra khoảng cách giữa những gì có thể về mặt kỹ thuật và những gì có thể sử dụng trên thực tế.
Cũng có một câu hỏi sâu hơn về độ chính xác. Liệu việc ghi nhận trong AI có bao giờ hoàn toàn công bằng không? Khi một mô hình sản xuất một đầu ra, làm thế nào bạn định lượng ảnh hưởng qua hàng triệu tương tác đào tạo? Ngay cả khi hệ thống có thể xác minh, việc giải thích vẫn có thể không hoàn hảo. Sự mâu thuẫn đó cảm thấy quan trọng. Bởi vì nó gợi ý rằng phân quyền trong AI không chỉ là một vấn đề kỹ thuật - đó cũng là một vấn đề triết học. Và mặc dù có những bất ổn này, hướng đi tổng thể cảm thấy khó để bỏ qua. Nếu các hệ thống AI tiếp tục phát triển thành hạ tầng nơi dữ liệu, mô hình và tác nhân tương tác kinh tế, thì ý tưởng về “trí thông minh có thể trả tiền” không còn nghe có vẻ trừu tượng nữa. Nó nghe như một sự mở rộng hợp lý của những gì đang xảy ra.
Dữ liệu trở thành vốn. Các mô hình trở thành những tác nhân kinh tế. Việc sử dụng trở thành một giao dịch giữa những người đóng góp có thể không bao giờ gặp nhau. OpenLedger dường như ngồi ngay trong vùng chuyển tiếp đó. Nhưng tôi vẫn thấy mình không chắc chắn về cách điều này sẽ ổn định trong dài hạn. Có thể việc ghi nhận sẽ trở nên chính xác đủ để định nghĩa lại quyền sở hữu trong các hệ thống AI. Hoặc có thể nó sẽ luôn chỉ là một sự gần đúng chồng chất lên sự phức tạp mà chúng ta không thể hoàn toàn đơn giản hóa. Hoặc có thể đây vẫn là hình dạng ban đầu của một cái gì đó mà chúng ta chưa hoàn toàn hiểu.
