
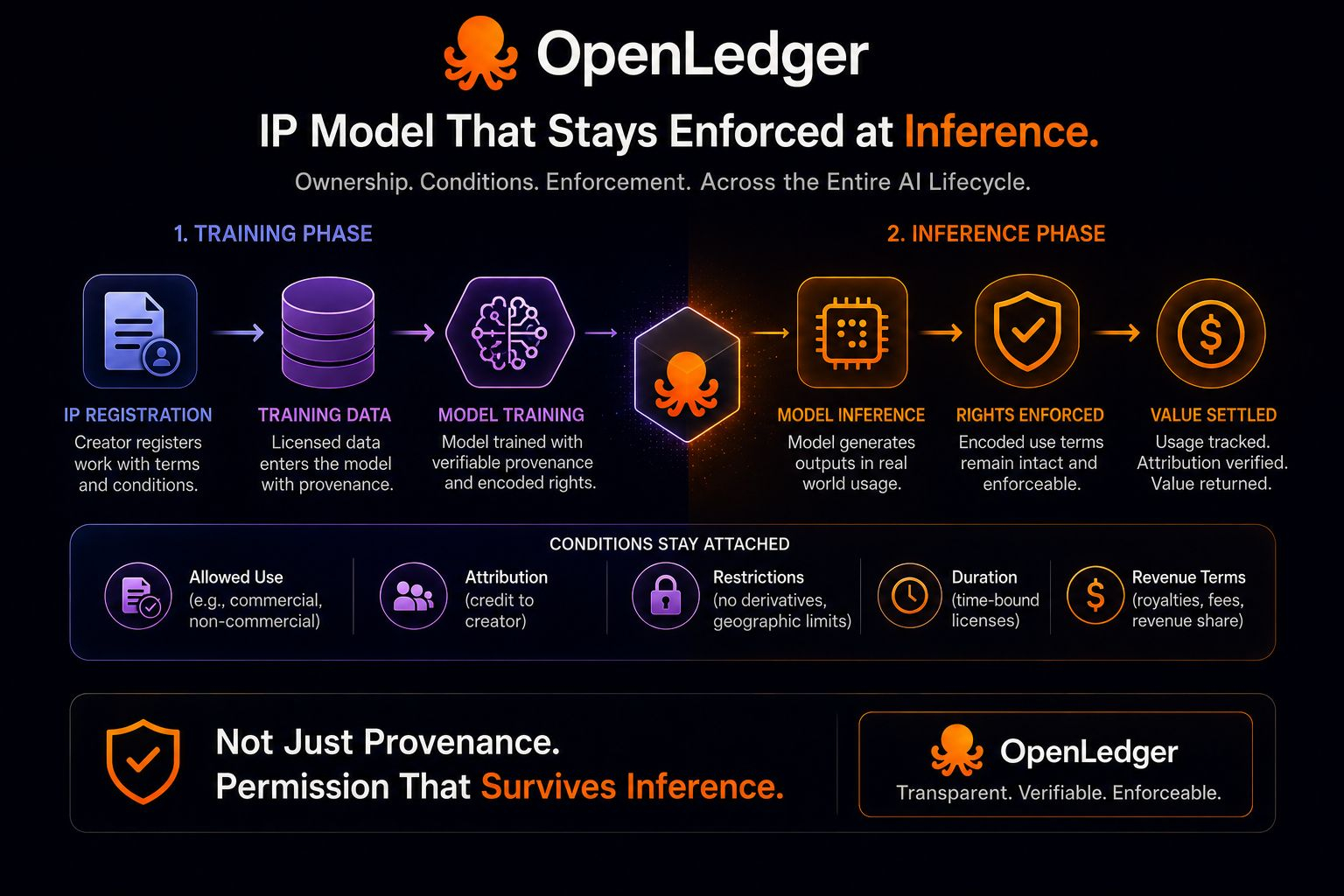
Lần đầu tiên tôi đọc về cơ sở hạ tầng IP của OpenLedger, tôi nghĩ điểm chính là nguồn gốc.
Dữ liệu đào tạo, mô hình và tài sản trí tuệ vào các hệ thống AI với quyền sở hữu đi kèm thay vì biến mất vào những đường ống mờ ám sau đó. Nói thật, điều đó đã nghe có vẻ hữu ích rồi. Một nhà sáng tạo ít nhất có thể chứng minh nơi nào cái gì đã vào lộ trình và trong điều kiện nào nó trở nên khả dụng.
Lúc đầu, tôi coi điểm vào đó là phần khó khăn.
Nếu quyền sở hữu vẫn rõ ràng ngay từ đầu, nếu tài sản mang theo nguồn gốc có thể đọc được trước khi việc đào tạo bắt đầu, thì hệ thống đã cảm thấy có trách nhiệm hơn so với hầu hết các đường ống AI hiện nay. Công việc không còn bắt đầu như đầu vào ẩn danh nữa.
Nhưng sau đó tôi dừng lại ở phần về mã hóa việc sử dụng được phép trong cả giai đoạn đào tạo và suy diễn.
Điều đó đã thay đổi cách nhìn của tôi về toàn bộ vấn đề.
Bởi vì đào tạo chỉ là một giai đoạn mà quyền hạn quan trọng. Khoảnh khắc khó khăn hơn sẽ đến sau đó, khi mô hình thực sự được sử dụng. Suy diễn là nơi mà đầu ra được tạo ra, quyết định được đưa ra, giá trị được tạo ra, và nơi mà các điều kiện ban đầu gắn liền với một tác phẩm có thể vẫn có ý nghĩa hoặc lặng lẽ phai nhạt vào nền.
Đó là lúc tuyên bố của OpenLedger trở nên lớn hơn nhiều so với hạ tầng đăng ký.
Một hồ sơ nguồn gốc sạch ngay từ đầu là hữu ích, nhưng nó không hoàn toàn giải quyết vấn đề phối hợp một mình. Một người nắm quyền có thể cho phép tác phẩm của họ vào một hệ thống dưới những điều kiện cụ thể, nhưng nếu những điều kiện đó trở nên không thể đọc được khi mô hình bắt đầu hoạt động, thì phần quan trọng của con đường quyền hạn sẽ bị vỡ ngay tại nơi mà hoạt động kinh tế bắt đầu diễn ra.
Và cách diễn đạt của OpenLedger quan trọng ở đây vì nó rõ ràng mở rộng logic vượt ra ngoài nguồn gốc đơn thuần. Sự tích hợp không chỉ được mô tả như theo dõi quyền sở hữu xung quanh dữ liệu và mô hình đào tạo. Nó mô tả việc sử dụng được phép vẫn được mã hóa trong cả đào tạo và suy diễn cùng nhau.
Điều đó có nghĩa là giai đoạn suy diễn không phải là một vấn đề bổ sung nào đó được thêm vào sau.
Đây là bài kiểm tra áp lực thực sự để xem cấu trúc quyền hạn có tồn tại khi mô hình bắt đầu sử dụng thực tế hay không.
Càng ngồi lâu với ý tưởng đó, OpenLedger càng không còn giống như một lớp đăng ký đơn giản với tôi mà bắt đầu cảm giác như một nỗ lực để giữ cho các luồng quyền hạn AI có thể đọc được sau khi triển khai thay vì chỉ trước đó.
Thật lòng mà nói, đó có lẽ là một vấn đề hạ tầng khó khăn hơn nhiều so với những gì hầu hết mọi người nhận ra ngay từ cái nhìn đầu tiên.
\u003cm-54/\u003e\u003cc-55/\u003e\u003cc-56/\u003e \u003cc-58/\u003e \u003ct-60/\u003e