Hôm nọ, mình thấy mình quá lạc quan về việc vibecoding.
Khó mà không lạc quan. Bạn gõ một ý tưởng lộn xộn vào công cụ AI lập trình, nhìn một giao diện hoạt động xuất hiện, sửa một vài lỗi, và đột nhiên khoảng cách giữa trí tưởng tượng và phần mềm cảm thấy ngắn lại nhiều. Đối với những builder cá nhân, điều đó thật mạnh mẽ. Đối với những nhóm nhỏ, nó có thể cảm giác như đang sử dụng đòn bẩy. Nhưng khi sự phấn khích phai nhạt, một câu hỏi khó chịu hơn xuất hiện: chuyện gì sẽ xảy ra khi thứ bạn đã xây dựng bắt đầu xử lý người dùng thực, dữ liệu thực, quyết định thực và tiền thực?
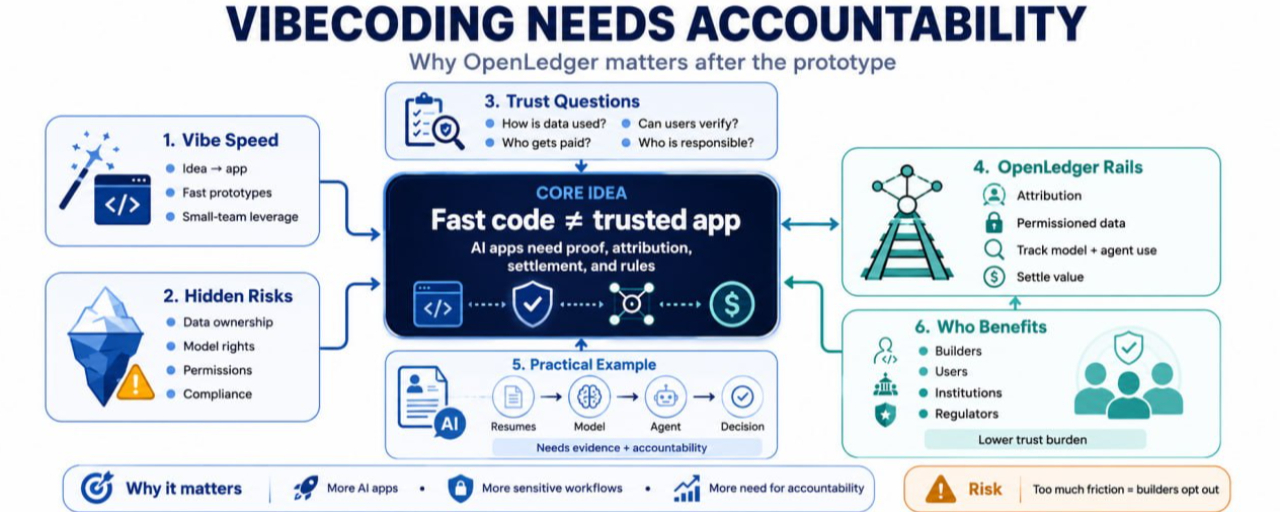
Đó là nơi cuộc trò chuyện trở nên nghiêm túc hơn. Vibecoding có thể tạo ra phần mềm nhanh hơn, nhưng tốc độ không tự động tạo ra sự tin cậy. Và sự tin cậy là nơi mà @OpenLedger trở nên quan trọng.
Vấn đề đứng sau tốc độ
Vấn đề không phải là lập trình hỗ trợ bởi AI là xấu. Vấn đề là nó có thể che giấu sự phức tạp.
Một nhà phát triển có thể tạo ra một ứng dụng thu thập dữ liệu người dùng, kết nối với một API, chạy một mô hình AI, và kích hoạt các hành động tự động. Bề ngoài, nó trông có vẻ đơn giản. Nhưng bên trong, có những câu hỏi về quyền sở hữu dữ liệu, quyền mô hình, quyền hạn, tuân thủ, và phân phối giá trị.
Ai sở hữu dữ liệu được sử dụng bởi ứng dụng?
Mô hình có được huấn luyện hoặc tinh chỉnh dựa trên dữ liệu có bản quyền không?
Người dùng có thể xác minh cách dữ liệu của họ đang được sử dụng không?
Nếu một đại lý AI tạo ra giá trị kinh tế, ai sẽ được trả tiền?
Trong các prototype ban đầu, những câu hỏi này dễ dàng bị bỏ qua. Trong sản xuất, chúng trở nên tốn kém.
Tại sao các nhà phát triển cần nhiều hơn mã
Vibecoding giảm chi phí xây dựng, nhưng nó có thể làm tăng nhu cầu về cơ sở hạ tầng.
Khi nhiều người có thể tạo phần mềm, nhiều phần mềm sẽ chạm đến những quy trình nhạy cảm. Điều này bao gồm tài chính, giáo dục, chăm sóc sức khỏe, dịch vụ pháp lý, hỗ trợ khách hàng, công cụ cho người sáng tạo và tự động hóa doanh nghiệp. Người dùng có thể không quan tâm phần mềm được xây dựng như thế nào, nhưng họ sẽ quan tâm nếu dữ liệu của họ bị lạm dụng hoặc nếu một quyết định tự động gây hại cho họ.
Các nhà phát triển cũng phải đối mặt với một vấn đề thực tiễn. Họ không muốn xây dựng lại các hệ thống tin cậy từ đầu. Họ cần các đường ray cho việc phân bổ, thanh toán, quyền dữ liệu, và kiếm tiền từ tài sản AI. Nếu không có những đường ray đó, mỗi ứng dụng mới trở thành một gói chứa đầy rủi ro pháp lý và vận hành ẩn.
Đây là một lý do mà sự tập trung của OpenLedger vào việc kiếm tiền từ dữ liệu, mô hình, và đại lý cảm thấy hợp thời. Nó chỉ ra một thế giới nơi các ứng dụng AI không chỉ là các giao diện thông minh, mà là các hệ thống kinh tế với các đầu vào và đầu ra có thể truy dấu.
Nơi mà OpenLedger có thể phù hợp
OpenLedger không chỉ là về việc làm cho AI dễ tiếp cận hơn. Ý tưởng thú vị hơn là làm cho các luồng giá trị AI có cấu trúc hơn.
Nếu một ứng dụng được vibecoded sử dụng một tập dữ liệu, một mô hình, và một đại lý tự động, sẽ phải có cách theo dõi cách những phần đó đóng góp vào kết quả. Nếu giá trị được tạo ra, sẽ phải có một con đường để phân phối. Nếu các tổ chức hoặc nhà quản lý hỏi sau này, sẽ phải có bằng chứng ngoài nhật ký riêng tư và ảnh chụp màn hình.
Đó là nơi mà $OPEN có thể quan trọng như một phần của lớp phối hợp. Token tự nó không nên làm phân tâm khỏi câu hỏi lớn hơn: liệu OpenLedger có thể giúp biến tài nguyên AI thành tài sản có thể chịu trách nhiệm và có thể kiếm tiền không?
Đối với các nhà phát triển, điều đó có thể có nghĩa là ít thời gian hơn để lo lắng về các vấn đề tin cậy ẩn. Đối với người dùng, điều đó có thể có nghĩa là nhiều tự tin hơn rằng dữ liệu của họ không được coi là nguyên liệu thô miễn phí. Đối với các tổ chức, điều đó có thể có nghĩa là các quy trình làm việc AI dễ dàng hơn để xem xét. Đối với các nhà quản lý, điều đó có thể có nghĩa là các đường ranh giới rõ ràng hơn giữa quyền sở hữu, quyền truy cập và trách nhiệm.
Một Ví dụ Thực Tiễn
Hãy tưởng tượng một nhà phát triển độc lập tạo ra một trợ lý tuyển dụng AI thông qua vibecoding.
Công cụ này sàng lọc hồ sơ, tóm tắt ứng viên, so sánh yêu cầu công việc và đề xuất danh sách phỏng vấn. Nó hoạt động đủ tốt để thu hút các doanh nghiệp nhỏ. Nhưng bây giờ nhà phát triển đang xử lý dữ liệu cá nhân nhạy cảm, khả năng thiên lệch, đầu ra mô hình của bên thứ ba, và các quyết định liên quan đến việc làm.
Một tư duy prototype bình thường không đủ.
Với cơ sở hạ tầng như OpenLedger, nhà phát triển có thể kết nối các nguồn dữ liệu, mô hình, và đại lý theo cách có trách nhiệm hơn. Việc sử dụng dữ liệu có thể được cấp phép. Các đóng góp mô hình có thể được theo dõi. Các hành động của đại lý có thể được ghi lại. Nếu một công ty trả tiền cho quy trình làm việc, việc phân phối giá trị có thể trở nên minh bạch hơn.
Điều này không tự động làm cho ứng dụng tuân thủ. Nó không loại bỏ nhu cầu phán đoán pháp lý. Nhưng nó có thể làm cho hệ thống ít mờ ám hơn.
Rủi ro là sự cản trở
Rủi ro thực sự là các nhà phát triển thích tốc độ và không thích sự cản trở.
Nếu OpenLedger thêm quá nhiều bước, tích hợp phức tạp, hoặc lợi ích không rõ ràng, các vibecoder có thể bỏ qua nó. Nhiều người sẽ chọn con đường nhanh nhất cho đến khi có khiếu nại từ người dùng, vấn đề quy định, hoặc khách hàng doanh nghiệp buộc họ phải quan tâm.
Cũng có một thách thức văn hóa. Vibecoding khuyến khích thử nghiệm. Tuân thủ khuyến khích sự thận trọng. Cơ hội của OpenLedger là kết nối những thế giới đó mà không làm cho các nhà phát triển cảm thấy bị mắc kẹt bởi thủ tục hành chính.
Điều đó không dễ dàng.
Nhận thức cơ bản
Những người có thể thực sự sử dụng OpenLedger trong bối cảnh này không chỉ là các nhà phát triển crypto-native. Họ có thể là các nhà phát triển ứng dụng AI, các đội tự động hóa, chủ sở hữu dữ liệu, người tạo đại lý, nhân viên tuân thủ, và các tổ chức cố gắng áp dụng AI mà không mất kiểm soát.
Nó có thể hoạt động nếu @OpenLedger làm cho việc chịu trách nhiệm cảm thấy giống như cơ sở hạ tầng, không phải giấy tờ. Nó có thể thất bại nếu các nhà phát triển xem dữ liệu có thể xác minh và các luồng thanh toán là gánh nặng thay vì sự bảo vệ.
Đối với tôi, điểm chính rất đơn giản: vibecoding có thể giúp mọi người xây dựng nhanh hơn, nhưng giai đoạn tiếp theo của ứng dụng AI sẽ cần nhiều hơn là mã nhanh. Nó sẽ cần sự tin cậy, phân bổ, thanh toán và các quy tắc mà người dùng có thể tin tưởng.
Đó là lý do tại sao #OpenLedger đáng để suy nghĩ vượt ra ngoài khung AI blockchain thông thường.
Không phải là lời khuyên tài chính.
Bạn muốn sử dụng một ứng dụng do AI xây dựng nhanh hơn, hay một ứng dụng có thể chứng minh cách dữ liệu và mô hình của nó đang được sử dụng?