Hỏi nguồn nước ở đâu mà trong sạch đến vậy? Chính vì có nguồn nước sống mới đến.
Tối nay, khi trò chuyện với bạn bè trong圈关于 AI 项目时,大家的关注点高度一致:模型参数有多大?推理速度有多快?算力投入几何?这些当然重要,但越来越多的人开始意识到,真正决定一个 AI 项目能否长期存活并建立护城河的,往往是背后是否形成了健康、高效、可持续的数据循环。
Hãy cùng bàn sâu về dự án OpenLedger($OPEN). Nó không chọn con đường “卷模型” đông đúc nhất, mà lại hướng thẳng đến tài nguyên AI khan hiếm và cốt lõi nhất — nguồn nước sống.
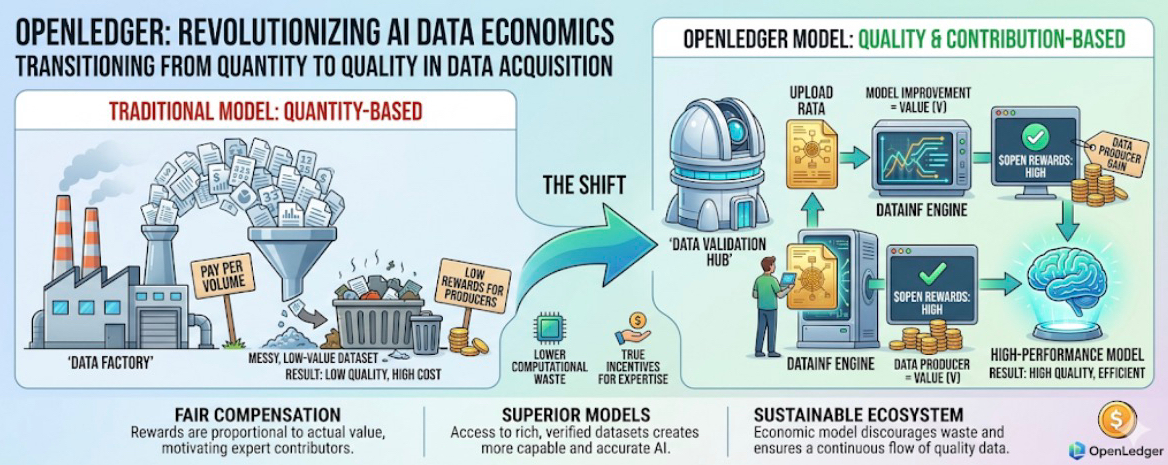
Một, phá vỡ mô hình "thu gom rác", thiết lập hệ thống xác thực dữ liệu
Hiện nay, đào tạo AI đang đối mặt với một vấn đề nghiêm trọng: Tiền xấu đuổi tiền tốt.
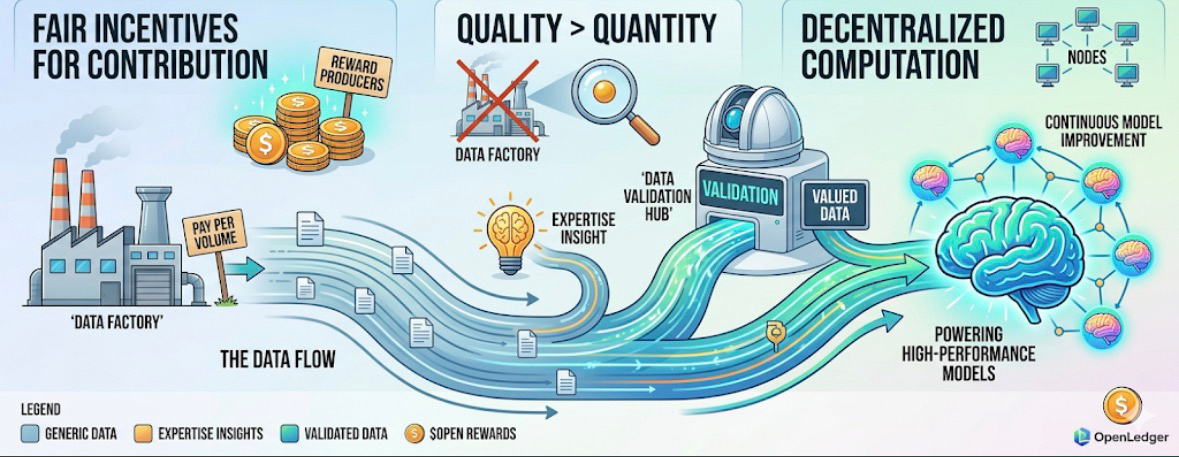
Hầu hết các nền tảng thu thập dữ liệu trên thị trường áp dụng cơ chế "trả theo lượng" thô sơ. Dù bạn tải lên những cái nhìn sâu sắc về ngành được tổ chức kỹ lưỡng hay chỉ là rác trên mạng sao chép một cách tùy tiện, chỉ cần đạt yêu cầu về số lượng chữ hoặc số lượng bài viết, bạn sẽ nhận được phần thưởng. Mô hình này dẫn đến hai hệ quả xấu: Một là nền tảng nhanh chóng bị nhấn chìm bởi dữ liệu chất lượng thấp, nội dung tổng hợp bằng máy, thông tin lặp lại; Hai là những người sở hữu dữ liệu chuyên nghiệp thực sự (bác sĩ, luật sư, kỹ sư, nghiên cứu viên, v.v.) thiếu động lực đóng góp, vì kiến thức quý giá của họ không nhận được phần thưởng xứng đáng.
Cải cách cốt lõi của #OpenLedger là ra mắt cơ chế DataInf (đánh giá ảnh hưởng dữ liệu). Cơ chế này đã thay đổi hoàn toàn các quy tắc trò chơi - nó không chỉ đơn giản là thống kê khối lượng dữ liệu, mà là định lượng chính xác mức độ nâng cao khả năng của mô hình từ từng dữ liệu.
Ví dụ như:
Người dùng thông thường tải lên một đoạn hướng dẫn sử dụng thuốc cảm cúm mà bất kỳ ai cũng có thể tìm thấy trên mạng, sau khi DataInf đánh giá sẽ cho điểm giá trị thấp;
Còn một bác sĩ chuyên nghiệp tải lên những trường hợp lâm sàng thực tế mà mình theo dõi trong năm năm (bao gồm các biến chứng hiếm gặp, lý luận quyết định điều trị, theo dõi hiệu quả thuốc), hệ thống sẽ phát hiện ra mô hình có độ chính xác, tính logic và tính an toàn trong các câu hỏi y tế liên quan được cải thiện đáng kể, từ đó cho thưởng token $OPEN cao hơn.
Thiết kế "phân phối phần thưởng theo đóng góp thực" này đã nâng cao ngưỡng chất lượng dữ liệu một cách đáng kể. Nó khiến các chuyên gia trong ngành, kiến thức trong lĩnh vực riêng, và phản hồi từ người dùng thực sẵn sàng chủ động tham gia, tạo thành vòng lặp tích cực của dữ liệu chất lượng cao. Quan trọng hơn, việc tích lũy này dựa vào lợi ích thực tế của mô hình rất khó bị các dự án khác sao chép đơn giản, trở thành lợi thế cạnh tranh tiềm năng lâu dài của OpenLedger.
Hai, mạng lưới dữ liệu phi tập trung: vượt qua thách thức về sức mạnh tính toán và niềm tin
Vậy tại sao những ý tưởng xuất sắc như vậy lại khó hiện thực hóa trong các dự án trước đây?
Khó khăn chính nằm ở cả thách thức về kỹ thuật và kinh tế. Việc tính toán chính xác mức độ đóng góp của từng dữ liệu vào mô hình lớn (đặc biệt là trong các tình huống phức tạp như tinh chỉnh, tiêm kiến thức, đồng bộ hành vi) đã cần một lượng sức mạnh tính toán cực cao. Nếu phải tiêu tốn hai đồng sức mạnh tính toán để đánh giá giá trị một đồng, toàn bộ hệ thống sẽ không thể vận hành bền vững.
Giải pháp của OpenLedger là xây dựng mạng lưới dữ liệu phi tập trung (Datanets). Cách làm cụ thể bao gồm:
Phân phối lại các nhiệm vụ tính toán như tính toán giá trị dữ liệu, quy trách nhiệm đóng góp, xác thực chất lượng cho các node trong mạng lưới;
Thông qua kinh tế học token $OPEN khuyến khích các node toàn cầu cung cấp sức mạnh tính toán, lưu trữ và dịch vụ xác thực;
Biến dữ liệu không còn là thông tin tĩnh, mà trở thành tài sản kỹ thuật số có thể giao dịch, quản trị và lưu thông trên chuỗi.
Thiết kế tích hợp Web3+AI này không chỉ giảm thiểu nút thắt sức mạnh tính toán và rủi ro điểm đơn của các nền tảng tập trung, mà còn nâng cao tính minh bạch và khả năng chống tấn công của hệ thống thông qua xác thực phân tán. Đồng thời, token $OPEN đảm nhận nhiều chức năng: thanh toán phí Gas, staking node, bỏ phiếu quản trị và thưởng cho việc đóng góp dữ liệu, tạo thành một nền kinh tế khép kín tương đối hoàn chỉnh.
Chắc chắn rồi, bất kỳ hệ thống khuyến khích cao nào cũng đều phải đối mặt với những thách thức thực tế. Phần thưởng lớn sẽ thu hút các nhà đầu tư đầu cơ thử nghiệm các cuộc tấn công Sybil, đầu độc dữ liệu, và tạo ra những dữ liệu rác tinh vi "có vẻ như có giá trị cao". OpenLedger cần phải tiếp tục củng cố cơ chế xác thực đa điểm, ứng dụng chứng minh không biết và mô hình hình phạt kinh tế, để đảm bảo sự công bằng trong việc quy trách nhiệm và tính ổn định lâu dài của hệ thống.
Ba, vòng lặp dữ liệu: sức mạnh quyết định cơ bản trong cạnh tranh AI
Nhìn về tương lai, cấu trúc cạnh tranh trong ngành AI sẽ ngày càng rõ ràng: Bề mặt là cạnh tranh mô hình, bề dưới là cạnh tranh dữ liệu.
Quy mô tham số và kiến trúc của các mô hình lớn tiên tiến có thể dần dần trở nên đồng nhất, nhưng ai có thể xây dựng một vòng lặp dữ liệu bền vững, chất lượng cao và tự củng cố, thì người đó sẽ duy trì ưu thế lâu dài. Điều mà OpenLedger xây dựng chính là một bộ "hệ thống hạ tầng lưu thông" - biến dữ liệu từ việc thu thập thụ động thành đóng góp chủ động, định giá chính xác và gia tăng giá trị tuần hoàn.
Đối với những chuyên gia thông thường, điều này cũng có nghĩa là một khả năng mới: Kinh nghiệm ngành tích lũy nhiều năm, những cạm bẫy đã trải nghiệm, và phương pháp độc đáo của bạn không chỉ có thể được biến thành tiền thông qua bài viết hoặc tư vấn, mà còn có thể nhận được phần thưởng bằng token thông qua việc đóng góp cho hệ thống AI. Điều này có thể trở thành kênh thực hiện giá trị mới cho những người lao động tri thức.
Cuối cùng, tôi muốn nghiêm túc hỏi mọi người một câu hỏi:
Nếu tương lai, bạn chia sẻ một kinh nghiệm ngành thực tế, trường hợp làm việc ẩn danh hoặc cái nhìn chuyên môn nào đó, có thể đổi lấy phần thưởng token $OPEN thông qua cơ chế công bằng, bạn có sẵn lòng ủy quyền dữ liệu chuyên môn của mình (đã được xử lý ẩn danh và bảo mật) cho một mạng lưới phi tập trung như vậy không?
