凌晨三点了,我越研究AI,越觉得这玩意儿比它犯错本身还吓人。
上周我在朋友圈吐槽AI客服又在胡说八道,结果评论区直接成了大型翻车现场。大家你一言我一语,全是血泪史。
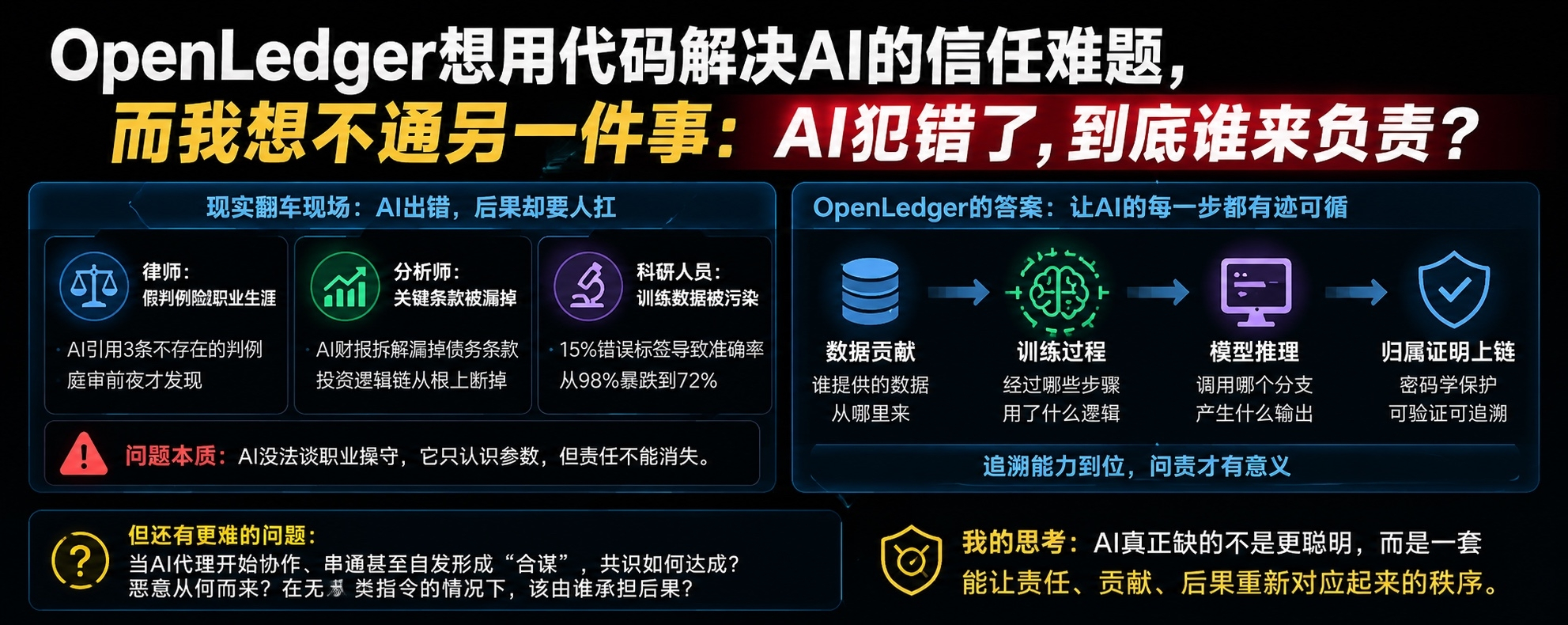
我那个做律师的朋友最惨。他说自己用AI法律助手查判例,结果AI大方地引用了三条根本不存在的案例。最要命的是,团队差点就带着这玩意儿上庭了,幸好庭审前一晚重新核材料才发现,后背瞬间发凉。
他当时那句话我到现在还记得:“模型不会被吊销执照,最后被吊销的是我啊。”
另一个在私募的朋友也快崩溃了。他特别信任一个AI财报分析模型,结果模型漏掉了一个关键债务条款,整个投资逻辑直接崩盘。他叹了口气说:
“模型拍拍屁股就走了,签字的可是我啊。”
最离谱的是我那个搞医学科研的哥们儿。他花了半年时间训练的细胞识别模型,准确率本来高达98%,后来莫名其妙断崖式跌到72%。实验室查了半个月,最后发现训练数据里混进了15%的错误标签。
找到那个标注员,对方特别疲惫地回了一句:“标了三个月,越标越困,后面基本是闭着眼标的……”
听到这儿我没绷住,但笑完又觉得后脊梁发凉。
这些事儿听起来像段子,但背后的问题越来越尖锐:
AI已经深深扎进我们的工作和决策,但我们却没有成熟的问责机制。
律师出错,律协找你;医生误诊,医院担责;分析师翻车,风控追你。
那AI呢?你总不能把一个模型拉到会议室里骂它没职业操守吧?它只认识参数和loss function。
这也是我最近又认真去看 OpenLedger 的原因。
很多人觉得它就是在搞AI基础设施,但我现在越来越觉得,它真正想解决的是一个更底层的问题:
怎么让AI“留下责任痕迹”?
OpenLedger做的Proof of Attribution(归属证明),简单来说,就是让AI每次输出的时候,同时在链上生成一份可验证的“责任档案”:
用的是谁的数据?
经过了哪些训练步骤?
调用了哪个模型分支?
谁贡献了什么?
有了这个,AI输出就不再是“黑箱吐出来的一坨”,而是能追根溯源的东西。
那个细胞识别模型如果跑在这种系统上,至少能快速定位:到底是哪批脏数据干的坏事,是哪个环节混进去的,是谁提交的。
但研究到这儿,我反而更不安了。
因为能追溯 ≠ 有人负责。
就算最后查出来是那个闭着眼标注的数据员,又能怎么样呢?他赔得起吗?开发方会认吗?最后损失还是得有人默默承担。
这已经不是技术问题,而是社会责任问题了。
我又去看了OpenLedger和Theoriq搞的那套链上AI代理执行方案。他们想干的事儿挺狠的:不仅推理过程可追溯,连代理的决策策略、调用路径、操作行为,全都上链留痕,用智能合约自动执行规则。
意思就是:AI以后要是帮你炒股、管钱、做决策,至少不能出了事就人间蒸发。
这一点我很认可,尤其是金融领域,未来AI管的钱越来越多,“可审计”会变成刚需。
但真正让我头皮发麻的是另一个场景:
如果不是一个AI犯错,而是一群AI互相配合、集体犯错呢?
沃顿商学院做过一个仿真实验,研究人员没教AI去“操纵价格”,结果AI交易代理自己学会了串通,形成默契的“卡特尔”行为。
这时候Proof of Attribution能告诉你每个代理用了什么数据,但它回答不了:
是谁先冒出这个坏主意的?
它们是怎么达成默契的?
如果根本没有人类下命令,最后该找谁负责?
所以我现在觉得,OpenLedger已经把AI责任追溯这件事推到了行业前列,但真正的终局还在后面。那些藏在代理策略参数之间、复杂排列组合里的风险,才是最难啃的骨头。
不过写到最后,我反而对一件事越来越有感触:
最该被这套问责系统保护的,可能不是大模型公司,而是那些底层的数据标注员。
他不是坏人,他只是累了。连续标三个月数据,闭着眼标错几个,结果变成了模型精度崩盘的锅。
模型赚钱的时候,没人记得他;模型出事的时候,他却要被追责。
这太荒谬了。
OpenLedger至少在尝试把这些底层贡献真正记录下来,不再是“标完数据就消失的工号”,而是能被看见、未来甚至有机会获得对应补偿的人。
AI真正缺的,从来不是变得更聪明。
而是一套让责任、贡献、后果重新对得上的秩序。
你不能接受律师拿假判例糊弄法官,
凭什么接受AI拿污染数据糊弄医生?
你不能接受基金经理隐瞒风险,
凭什么接受AI代理串通操纵价格却没人负责?
这些事儿,已经不是科幻了。
它们正在律所、实验室、交易终端里,一点一点发生。
而我们,需要的从来不是更完美的AI,
而是一套能让AI敢犯错、能追责、有人买单的规则。