Khi tôi lần đầu nhìn vào @OpenLedger 's Proof of Attribution, tôi nghĩ vấn đề chính là sự công bằng. Trả tiền cho những người đóng góp dữ liệu hữu ích, và hệ thống trở nên trung thực hơn. Nhưng quan điểm đó bây giờ có vẻ quá đơn giản.
Câu hỏi khó hơn không phải là ai đã đóng góp. Câu hỏi khó hơn là đóng góp của ai thực sự đã thay đổi câu trả lời.
Đó là nơi mà điểm ảnh hưởng I(di, y) trở nên quan trọng. Nói một cách đơn giản, di có nghĩa là một điểm dữ liệu, y có nghĩa là một đầu ra mô hình, và I đo lường mức độ mà điểm dữ liệu đó đã định hình đầu ra cụ thể đó. Nó biến việc quy attribution từ một yêu cầu sở hữu rộng thành một vấn đề đo lường hẹp hơn.
Bề ngoài, một người đóng góp tải dữ liệu lên một DataNet và chờ giá trị quay trở lại. Nhưng bên dưới, hệ thống phải hỏi liệu dữ liệu đó chỉ tồn tại trong môi trường đào tạo hay liệu nó có trọng lượng thực sự khi mô hình tạo ra kết quả.
Sự khác biệt đó thì im lặng, nhưng nó thay đổi hoàn toàn logic phần thưởng.
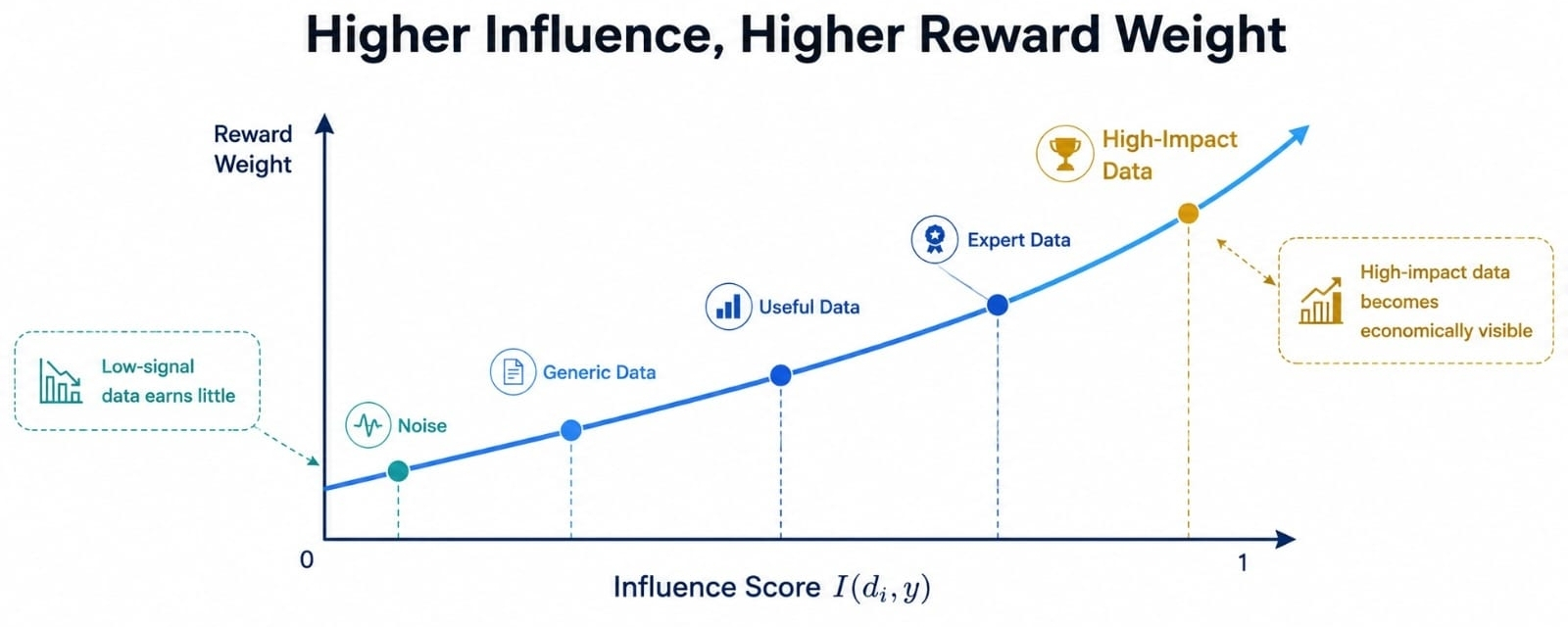
Nếu 100 người đóng góp cung cấp dữ liệu, một mô hình phần thưởng phẳng có thể coi sự tham gia như một giá trị. Điều đó tạo ra một động lực yếu. Mọi người có thể theo đuổi khối lượng, sao chép tài liệu, hoặc gửi dữ liệu tín hiệu thấp trông có vẻ hoạt động nhưng không cải thiện mô hình dưới áp lực.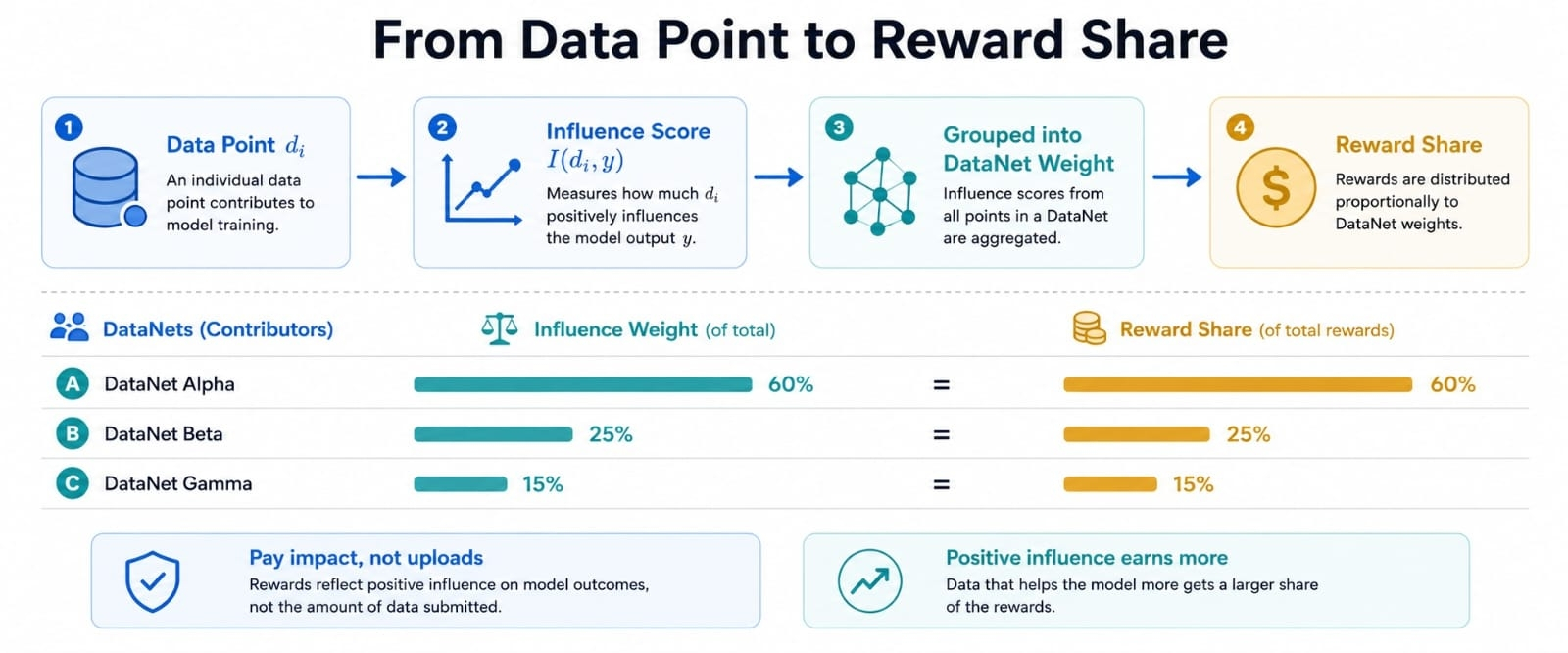
I(di, y) đẩy ngược lại điều đó. Nó yêu cầu ảnh hưởng, không phải tiếng ồn. Nếu một điểm dữ liệu cải thiện độ tin cậy, tính liên quan, hoặc độ chính xác cho một đầu ra, nó nên kiếm được nhiều trọng số hơn so với mười điểm chung chung ngồi gần đó nhưng không quan trọng lắm.
Hiểu điều đó giúp giải thích tại sao toán phân bổ không chỉ là một công cụ thanh toán. Nó cũng là một bộ lọc khuyến khích. Một người đóng góp không được thưởng chỉ vì dữ liệu của họ đã vào hệ thống. Họ được thưởng vì dữ liệu của họ vẫn xuất hiện trong hành vi của mô hình.
Một cách chia thưởng đơn giản cho thấy ý tưởng. Nếu một DataNet nắm giữ 60 phần trăm ảnh hưởng đo được cho một đầu ra giá trị và một DataNet khác nắm giữ 40 phần trăm, phần thưởng có thể di chuyển theo tỷ lệ đó thay vì bị đoán mò thủ công. Con số không chỉ là kế toán. Đó là một cách để làm cho việc đóng góp khó bị giả mạo hơn.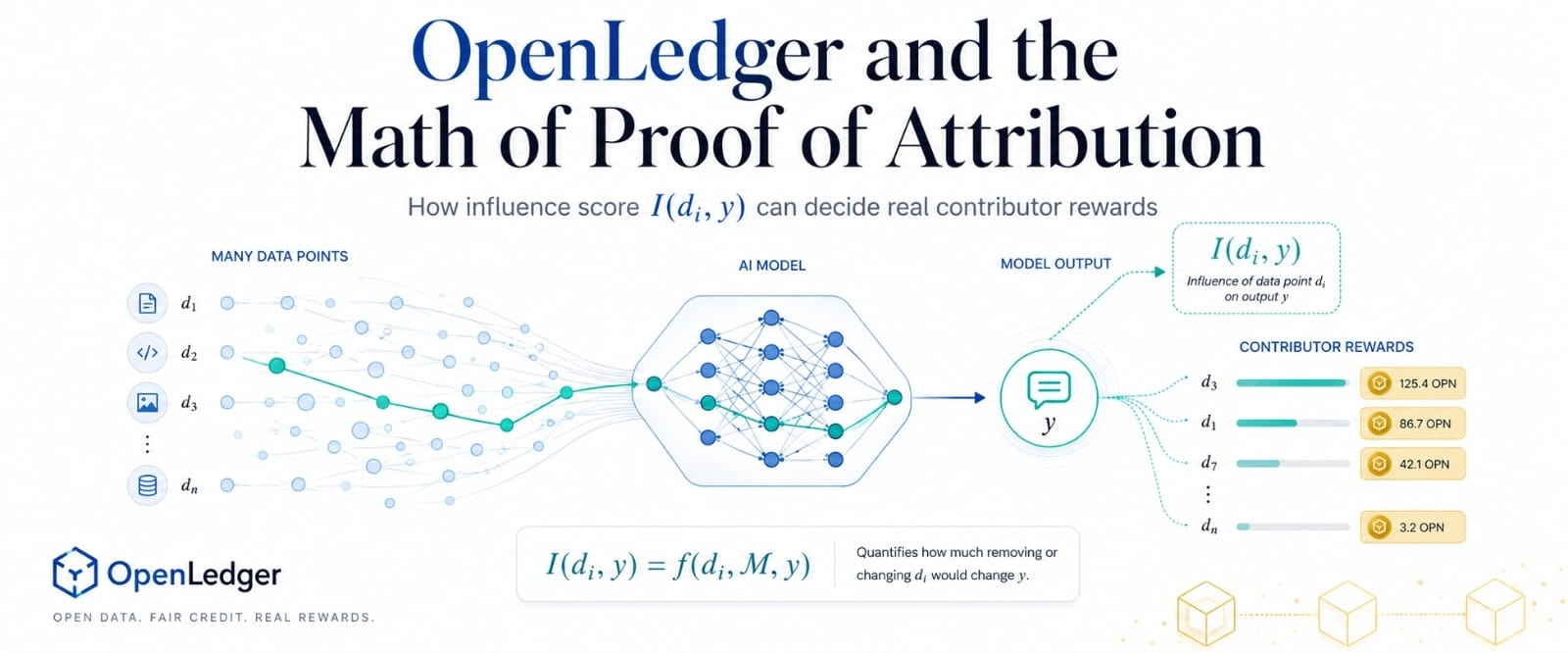
Điều đó tạo ra một vấn đề khác. Điểm ảnh hưởng có thể trông sạch hơn thực tế. Đầu ra AI thường được hình thành bởi dữ liệu chồng chéo, các mẫu lặp lại, và tín hiệu gián tiếp. Một điểm số cao có thể phản ánh tính hữu ích thực sự, nhưng nó cũng có thể phản ánh việc ghi nhớ, trùng lặp, hoặc dữ liệu được thiết kế để kích hoạt phân bổ.
Vì vậy, phiên bản mạnh nhất của OpenLedger không thể chỉ phụ thuộc vào I(di, y). Nó cần hồ sơ, băm, dấu thời gian, loại bỏ trùng lặp, xác thực, và quản trị xung quanh các ngưỡng. Công thức có thể đo áp lực, nhưng hệ thống vẫn phải quyết định mức độ ảnh hưởng nào xứng đáng được thanh toán.
Vấn đề yên tĩnh hơn là lòng tin. Khi phần thưởng thực sự được gắn liền, mọi điểm số trở thành nền tảng kinh tế. Những người đóng góp sẽ thử nghiệm các giới hạn. Quản trị sẽ đối mặt với tranh chấp. Thị trường sẽ hỏi liệu lớp phân bổ có đủ dự đoán để định giá công bằng việc đóng góp hay không.
Nếu điều này đúng, #OpenLedger không chỉ xây dựng một hệ thống phần thưởng cho dữ liệu AI. Nó đang thử nghiệm xem liệu sự đóng góp của AI có thể trở thành cơ sở hạ tầng có thể đo lường.
Thành tựu thực sự không phải là chứng minh rằng dữ liệu đã có mặt. Mà là chứng minh rằng dữ liệu đó có ý nghĩa.

