
Ban đầu, tôi thật sự nghĩ @OpenLedger là chỉ một đồng coin AI khác.
Và công bằng mà nói, thị trường crypto hiện đang tràn ngập những dự án như vậy.
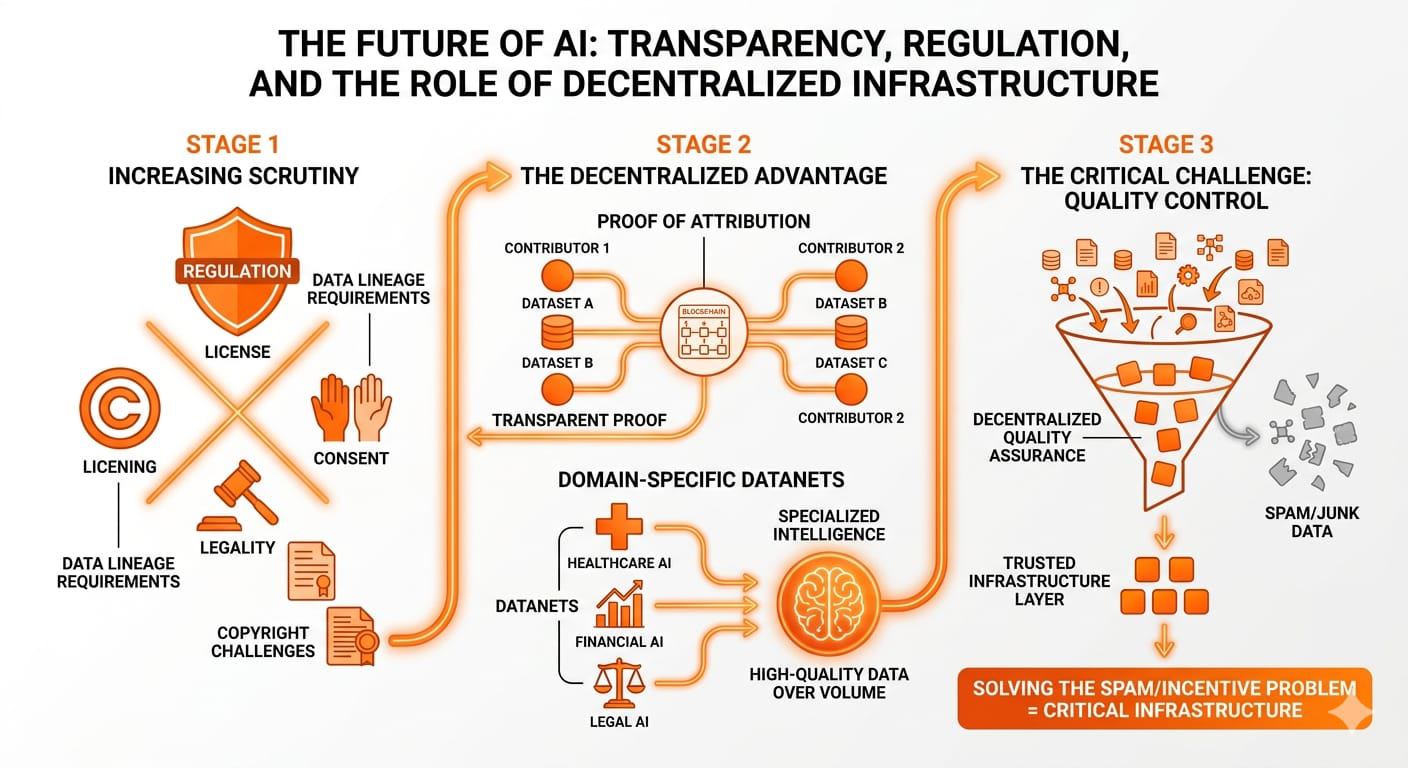
Mỗi tuần có một dự án mới nói về "hạ tầng AI," "trí tuệ phi tập trung," hoặc "tương lai của các tác nhân tự động." Hầu hết chúng đều nghe có vẻ thú vị khi ra mắt, nhưng sau khi nhìn sâu hơn, nhiều dự án vẫn đang tìm kiếm utility thực sự.
Đó là lý do tại sao tôi không chú ý nhiều đến OpenLedger ngay từ đầu.
Nhưng sau vài ngày nghiên cứu hệ thống Proof of Attribution và thị trường Datanets, tôi nhận ra một điều quan trọng:
OpenLedger ít nhất đang cố gắng giải quyết một vấn đề cơ sở hạ tầng thực sự.
Và theo ý kiến của tôi, điều đó ngay lập tức làm cho nó thú vị hơn hầu hết các câu chuyện AI trong crypto hiện nay.
Bởi vì tài sản có giá trị nhất trong AI có thể không thực sự là mô hình.
Có thể là dữ liệu.
Mọi người đều nói về các hệ thống giống như ChatGPT, các đại lý AI và các mô hình trị giá hàng tỷ đô la. Nhưng rất ít người thảo luận nghiêm túc về lượng lớn dữ liệu cần thiết để huấn luyện những hệ thống này.
Dữ liệu đó đến từ đâu?
Ai đã đóng góp?
Ai sở hữu nó?
Có được sự cho phép không?
Và quan trọng nhất...
Ai sẽ được thưởng khi các sản phẩm AI tạo ra hàng tỷ giá trị?
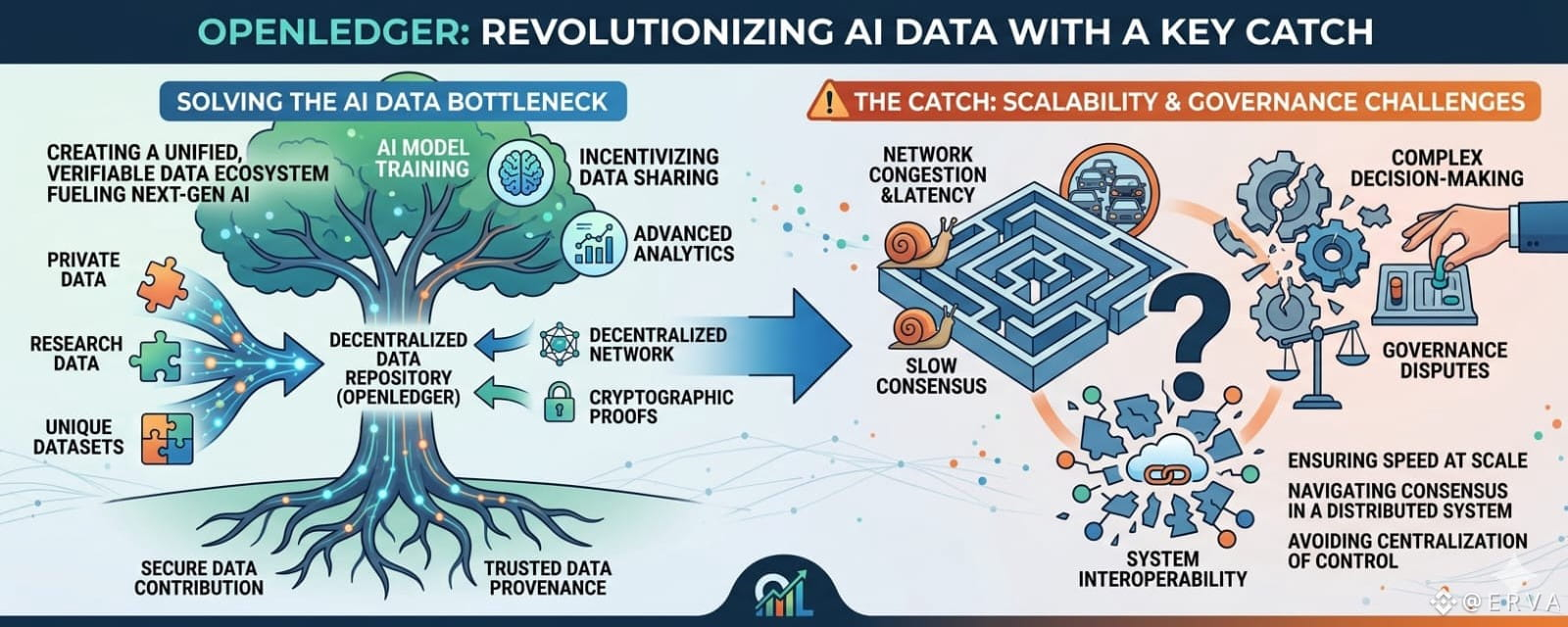
Đó là khoảng trống mà OpenLedger muốn lấp đầy.
Ý tưởng đứng sau dự án thì đơn giản một cách bất ngờ.
Người dùng đóng góp các bộ dữ liệu cho mạng lưới. Các mô hình AI huấn luyện trên những bộ dữ liệu đó. Hệ thống theo dõi dữ liệu nào đã ảnh hưởng đến mô hình và các người đóng góp nhận phần thưởng thông qua một cơ chế gọi là Proof of Attribution.
Thành thật mà nói, về mặt khái niệm, đây là một ý tưởng thông minh.
Thay vì dữ liệu trở nên vô hình sau khi tải lên, OpenLedger muốn các người đóng góp vẫn kết nối với giá trị kinh tế mà dữ liệu của họ giúp tạo ra.
Và nếu AI tiếp tục phát triển với tốc độ hiện tại, sự ghi nhận dữ liệu có thể cuối cùng trở thành một ngành công nghiệp khổng lồ tự nó.
Nhưng đây là nơi mọi thứ trở nên phức tạp.
Bởi vì xây dựng một thị trường thì dễ.
Xây dựng một thị trường chất lượng cao thì không.
Và đó là câu hỏi lớn nhất mà tôi vẫn có về OpenLedger.
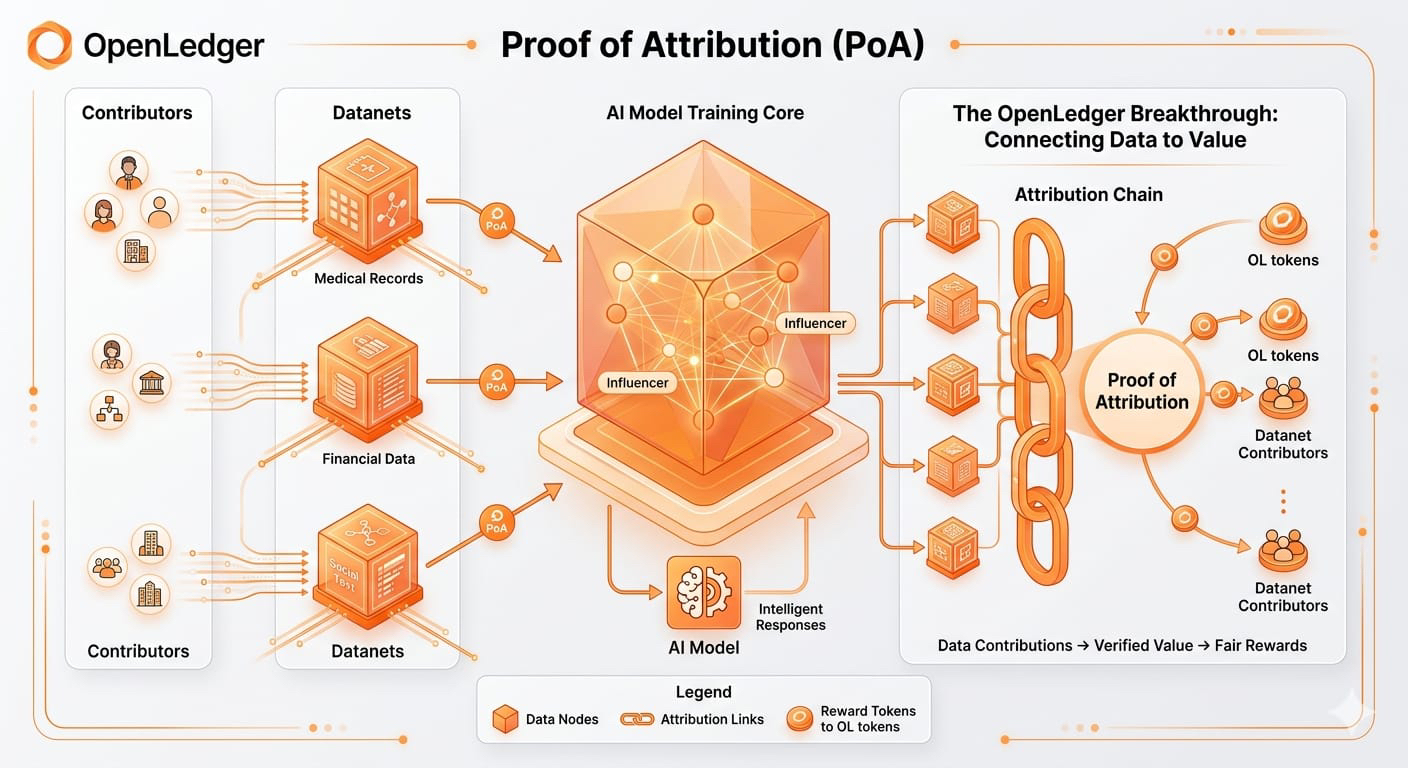
Vấn đề thực sự không phải là quyền sở hữu... mà là chất lượng
Blockchain rất tốt trong việc xác minh quyền sở hữu.
Nó có thể theo dõi các giao dịch.
Nó có thể tự động hóa phần thưởng.
Nó có thể tạo ra tính minh bạch.
Nhưng blockchain không thể tự động xác định liệu dữ liệu có thực sự hữu ích hay không.
Và trong AI, chất lượng dữ liệu thay đổi mọi thứ.
Một mô hình mạnh mẽ được huấn luyện trên dữ liệu yếu có thể tạo ra đầu ra tồi tệ.
Cùng lúc đó, ngay cả một bộ dữ liệu nhỏ nhưng chất lượng cao cũng có thể cải thiện đáng kể hiệu suất mô hình.
Đó là lý do tại sao các công ty như OpenAI, Anthropic và DeepMind chi tiêu một số tiền khổng lồ vào:
làm sạch dữ liệu
giảm thiên kiến
lọc
loại bỏ trùng lặp
đánh giá an toàn
ngăn chặn ảo giác
Quá trình này tốn kém, chậm chạp và rất tập trung.
OpenLedger đang cố gắng phi tập trung hóa các phần của hệ thống đó thông qua các cơ chế danh tiếng, điểm xác thực, mô hình staking và sự ghi nhận đóng góp.
Nhưng tôi vẫn nghĩ câu hỏi khó nhất
Ai quyết định liệu một bộ dữ liệu có thực sự có giá trị không?
Bởi vì giá trị trong dữ liệu AI không phải lúc nào cũng rõ ràng.
Một số bộ dữ liệu trông đơn giản nhưng cải thiện đáng kể độ chính xác của mô hình.
Những người khác trông chuyên nghiệp nhưng không thêm hầu như không có trí tuệ thực sự.
Và điều này trở nên nguy hiểm khi các động lực tài chính tham gia vào hệ thống.
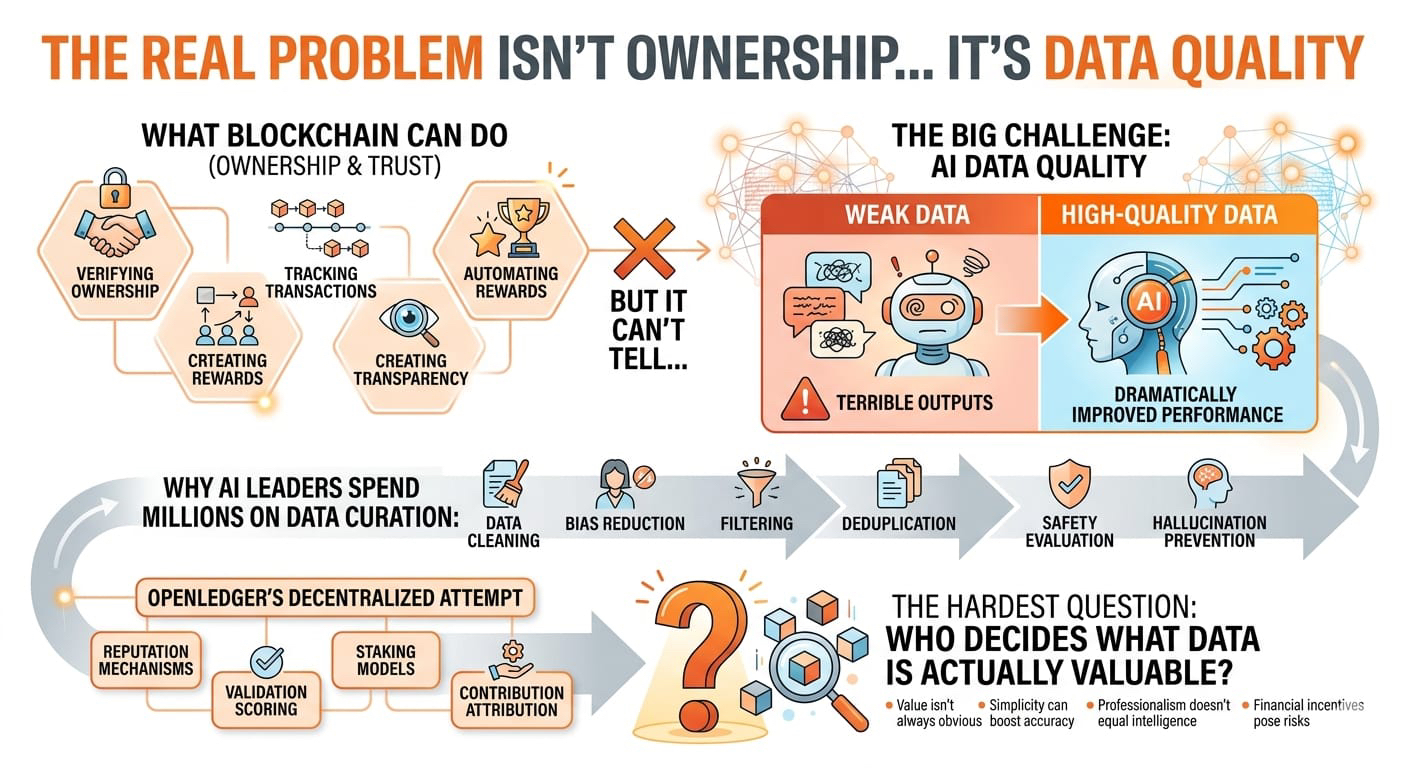
Crypto đã cho chúng ta thấy điều gì xảy ra với các động lực.
Ngay khi có phần thưởng, mọi người tối ưu hóa cho phần thưởng.
Chúng tôi đã thấy điều này trong hầu hết mọi lĩnh vực của crypto.
Chơi để kiếm tiền đã trở thành canh tác.
Airdrop đã trở thành săn tìm sybil.
Các nền tảng nội dung đã trở thành máy móc canh tác tương tác.
Vì vậy, một cách tự nhiên, rủi ro tương tự tồn tại cho các thị trường dữ liệu AI.
Điều gì xảy ra nếu hàng ngàn người dùng bắt đầu tải lên các văn bản do AI tạo ra chất lượng thấp chỉ để kiếm phần thưởng?
Thị trường có thể nhanh chóng trở nên ngập tràn tiếng ồn tổng hợp.
Và không giống như spam trên mạng xã hội, dữ liệu huấn luyện AI kém có thể làm hỏng hiệu suất mô hình.
Các bộ dữ liệu yếu có thể:
tăng cường ảo giác
khuếch đại thiên kiến
giảm độ tin cậy
biến dạng đầu ra
yếu đi các ứng dụng hạ nguồn
Đó là lý do tại sao tôi nghĩ thành công dài hạn của OpenLedger phụ thuộc nhiều hơn vào việc kiểm soát chất lượng hơn là giá token.
Bởi vì nếu lớp dữ liệu cơ sở trở nên yếu, toàn bộ vòng kinh tế
Dữ liệu chất lượng kém dẫn đến các mô hình yếu.
Các mô hình yếu làm giảm sự chấp nhận.
Sự chấp nhận thấp giảm phần thưởng.
Và cuối cùng, hệ sinh thái mất giá trị.
Đó là hiện thực khắc nghiệt của các hệ thống AI phi tập trung.
Dù sao đi nữa, có một điều tôi thực sự tôn trọng về OpenLedger.
Họ đang tập trung vào cơ sở hạ tầng thay vì chỉ là sự cường điệu.
Hầu hết các dự án AI trong crypto quảng bá bản thân quanh những lời hứa trong tương lai. OpenLedger thực sự đang cố gắng xây dựng các hệ thống xung quanh:
sự ghi nhận dữ liệu
theo dõi quyền sở hữu
giải thích
phân phối phần thưởng minh bạch
các hệ thống đóng góp AI có thể xác minh
Đây không phải là những chủ đề hấp dẫn.
Nhưng chúng cực kỳ quan trọng.
Đặc biệt khi bạn xem xét hướng đi của quy định AI toàn cầu.
Quy định có thể thay đổi mọi thứ
Ngay bây giờ, các chính phủ trên thế giới đang bắt đầu chú ý nhiều hơn đến các hệ thống huấn luyện AI.
Câu hỏi về bản quyền, giấy phép, sự đồng ý và tính hợp pháp của bộ dữ liệu ngày càng trở nên lớn hơn mỗi năm.
Các công ty AI lớn đã phải đối mặt với sự chỉ trích về cách thức thu thập và sử dụng dữ liệu huấn luyện.
Và thành thật mà nói, điều này có thể trở thành một trong những lợi thế lớn nhất của OpenLedger trong tương lai.
Bởi vì nếu quy định AI cuối cùng yêu cầu nguồn gốc dữ liệu minh bạch, thì các hệ thống như Proof of Attribution đột nhiên trở nên rất có giá trị.
Có thể chứng minh:
dữ liệu đến từ đâu
ai đã đóng góp
nó đã được sử dụng như thế nào
và ai nên được thưởng
có thể trở thành cơ sở hạ tầng quan trọng cho các hệ sinh thái AI tuân thủ.
Đó là một câu chuyện lớn hơn nhiều so với việc chỉ đơn giản là "một đồng tiền AI khác."
Và tôi nghĩ đây là nơi OpenLedger trở nên thực sự thú vị.
Không phải vì thành công là điều đảm bảo.
Nhưng vì vấn đề mà nó đang cố gắng giải quyết là có thật.
Datanets có thể là phần thông minh nhất của toàn bộ dự án
Một phần của OpenLedger tôi thực sự thích là sự tập trung vào các Datanets cụ thể theo miền.
Internet đã chứa đựng một lượng lớn dữ liệu huấn luyện chung.
Lợi thế tương lai trong AI có thể không còn đến từ ai có mô hình lớn nhất nữa.
Nó có thể đến từ ai có trí tuệ chuyên môn tốt nhất.
AI chăm sóc sức khỏe cần dữ liệu đạt tiêu chuẩn y tế.
AI tài chính cần các bộ dữ liệu tài chính có cấu trúc.
AI pháp lý cần các khung pháp lý chính xác.
Nội dung internet tổng quát đã trở nên bão hòa.
Dữ liệu chuyên biệt chất lượng cao là nơi giá trị thực sự có thể tồn tại trong tương lai.
Và OpenLedger dường như hiểu điều đó.
Nếu dự án có thể thành công xây dựng các Datanets đáng tin cậy với kiểm soát chất lượng mạnh mẽ, thì nó có thể tạo ra hiệu ứng mạng mạnh mẽ quanh cơ sở hạ tầng AI chuyên biệt.
Nhưng lại một lần nữa...
Mọi thứ đều quay trở lại câu hỏi giống nhau:
Liệu các hệ thống phi tập trung có thể duy trì dữ liệu chất lượng cao mà không bị sập vào spam do động lực không?
Ngay bây giờ, tôi không nghĩ ai trong crypto đã giải quyết hoàn toàn vấn đề đó.
Không phải OpenLedger.
Không phải Bittensor.
Không phải bất kỳ thị trường AI phi tập trung nào.
Và thành thật mà nói, tôi nghĩ dự án đầu tiên thực sự giải quyết được điều này có thể trở thành một trong những lớp hạ tầng AI quan trọng nhất trong Web3.
Những suy nghĩ cuối cùng
Cá nhân tôi, tôi vẫn chưa hoàn toàn lạc quan về OpenLedger.
Nhưng tôi chắc chắn đang chú ý bây giờ.
Bởi vì không giống như nhiều dự án AI hoàn toàn dựa vào chu kỳ cường điệu, OpenLedger đang cố gắng giải quyết một điều gì đó nền tảng.
Dự án đang cố gắng xây dựng cơ sở hạ tầng kinh tế quanh dữ liệu AI.
Và nếu AI trở thành lĩnh vực công nghệ thống trị trong thập kỷ tới, thì quyền sở hữu dữ liệu, sự ghi nhận và tính minh bạch có thể trở thành những cuộc trò chuyện trị giá hàng triệu đô la.
Cơ hội là khổng lồ.
Mức độ khó thực hiện còn lớn hơn.
Và theo ý kiến của tôi, tương lai của OpenLedger sẽ phụ thuộc vào một điều trên tất cả:
Liệu các thị trường AI phi tập trung có thể thưởng cho chất lượng mà không bị phá hủy bởi động lực spam.
Ngày nào tôi thấy một câu trả lời thuyết phục cho câu hỏi đó, tôi có thể ngừng xem OpenLedger như chỉ là một đồng tiền AI khác.
Có thể sau đó nó trở thành cơ sở hạ tầng thực.
\u003ct-218/\u003e\u003cc-219/\u003e