Tôi đã sử dụng internet nhiều năm. Công cụ tìm kiếm. Các nguồn cấp xã hội. Thuật toán gợi ý. Và trong suốt hành trình đó, tôi bắt đầu đặt ra câu hỏi mà tôi không thể gạt bỏ: Ai thực sự đang hưởng lợi từ tất cả những điều này?
Bởi vì không phải tôi.....
Mỗi lần tìm kiếm tôi thực hiện, mỗi bài đăng tôi thích, mỗi mẫu hành vi tôi tạo ra... dữ liệu đó đã đi đâu đó. Được đóng gói. Được bán. Xây dựng những mô hình tỷ đô. Và tôi nhận được một nguồn cấp dữ liệu miễn phí và một quảng cáo nhắm mục tiêu cho đôi giày mà tôi đã mua rồi.😐
Đó không phải là một sàn giao dịch. Đó là khai thác dữ liệu.
Và phần tồi tệ nhất? Chưa bao giờ có một hợp đồng. Không có chữ ký. Không có thỏa thuận. Chỉ có một điều khoản dịch vụ mà không ai đọc, và một hệ thống đã quyết định dữ liệu của bạn có giá trị chỉ không phải cho bạn.
OpenLedger đang chỉ ra điều đó một cách thẳng thắn. Và thật sự, đã đến lúc ai đó phải làm như vậy.
Đây là con số khiến tôi dừng lại. Meta đã tạo ra hơn 130 tỷ USD doanh thu trong năm ngoái. Hầu hết đều từ quảng cáo. Hầu hết quảng cáo đó được hỗ trợ bởi dữ liệu hành vi của bạn, của tôi, của mọi người. Và những người tạo ra dữ liệu đó đã nhận được đúng 0 đô la cho nó. Không một phần trăm. Không một token. Không gì cả.
Chúng ta không chỉ đơn giản chuyển nhượng nhấp chuột của mình. Chúng ta đã chuyển nhượng các mẫu hành vi chú ý, ý định mua sắm, khuynh hướng chính trị, lịch trình ngủ của mình. Các công ty AI hiện đang huấn luyện các mô hình nền tảng trên hàng thập kỷ văn bản, hình ảnh và dữ liệu giọng nói do con người tạo ra, bị thu thập từ web mở.... Những người đã viết những từ đó, chụp những bức ảnh đó, ghi lại những giọng nói đó không có quyền gì cả.... Không có hồ sơ.... Không có biện pháp....
Đây là sự bất công cốt lõi mà tiêu đề đang chỉ ra. Và tôi nghĩ điều đó đáng để ngồi lại với từ bất công đó..... vì nó không phải là một tai nạn. Đó là một lựa chọn thiết kế. Internet hiện tại được xây dựng để khai thác giá trị từ người dùng trong khi trả lại càng ít càng tốt. Đó không phải là một lỗi. Đó là mô hình kinh doanh.
Vậy tại sao blockchain chưa giải quyết điều này? Đó là câu hỏi tôi đã xoay quanh. Chúng ta đã có crypto hơn một thập kỷ. Chúng ta đã có ví, hợp đồng thông minh, DAO, mọi thứ đều được token hóa. Thế nhưng quyền sở hữu dữ liệu vẫn hoàn toàn chưa được giải quyết. Câu trả lời trung thực là hầu hết các dự án đều giải quyết vấn đề thanh khoản, không phải vấn đề ghi nhận. Không ai xây dựng cơ sở hạ tầng để thật sự theo dõi — trên chuỗi, có thể xác minh — ai đã đóng góp dữ liệu gì cho mô hình nào.
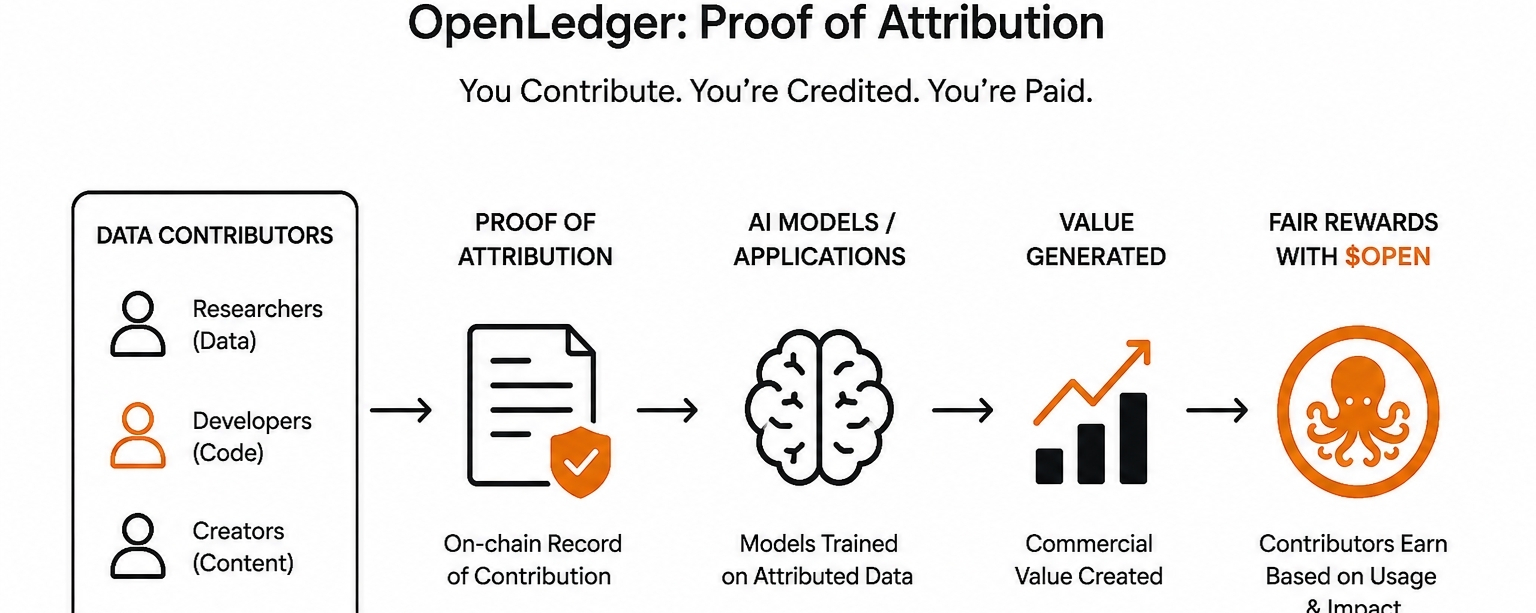
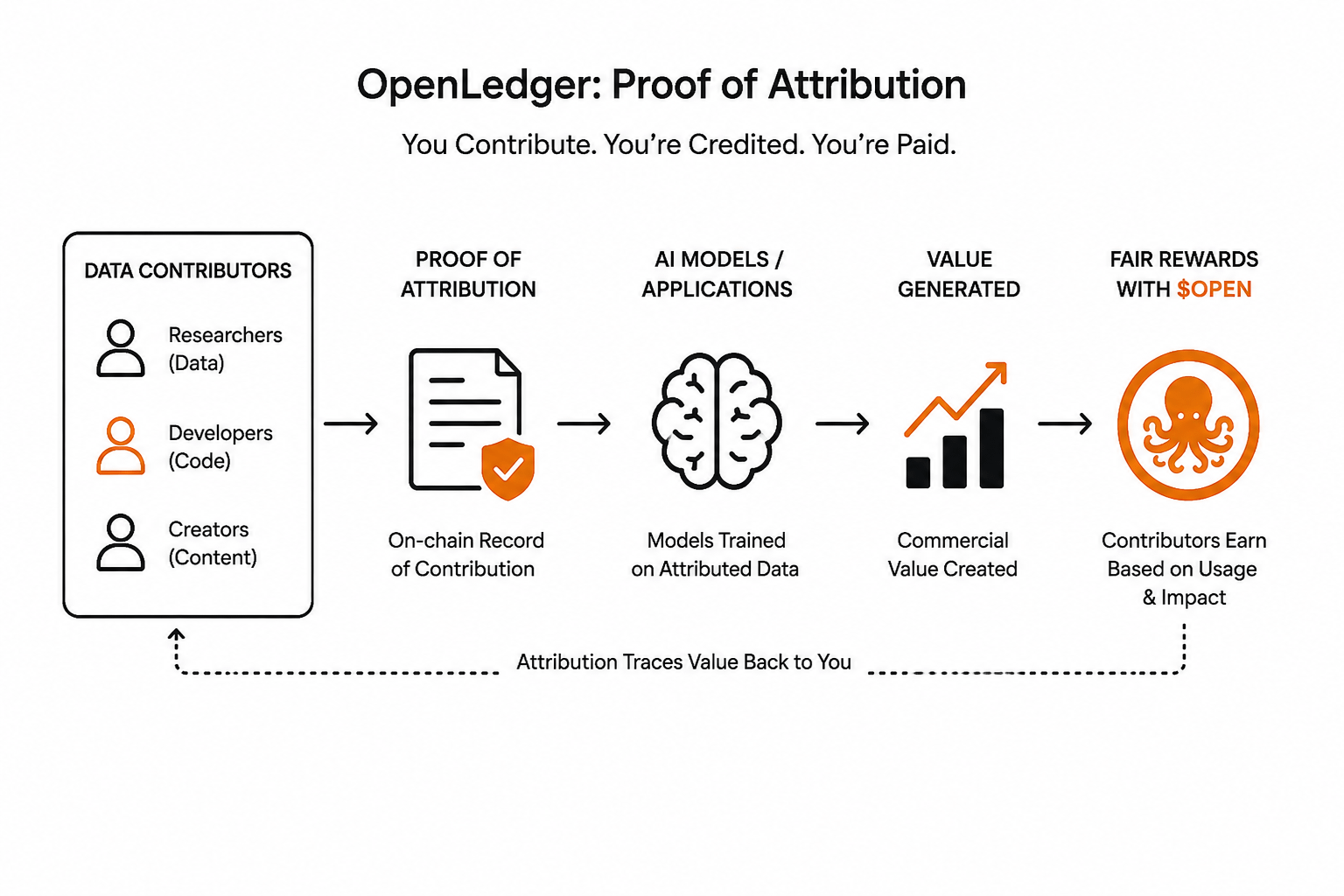
Đó là khoảng trống mà OpenLedger đang cố gắng lấp đầy.👀
Cách tiếp cận của họ tập trung vào cái gọi là Proof of Attribution. Ý tưởng thì đơn giản ngay cả khi việc thực hiện thì phức tạp. Khi bạn đóng góp dữ liệu — bất kể đó là đầu vào huấn luyện, tín hiệu hành vi, hay kiến thức chuyên môn cụ thể — sự đóng góp đó được ghi lại trên blockchain tương thích với EVM của họ. Nó không chỉ là một biên nhận. Đó là một hồ sơ có thể truy vấn trực tiếp liên kết đầu vào của bạn với bất cứ giá trị nào được tạo ra từ đó. Và $OPEN hoạt động như một lớp tiện ích giúp cho việc ghi nhận đó có ý nghĩa kinh tế.
Tôi muốn chính xác ở đây vì sự khác biệt là quan trọng. Đây không phải là một nền tảng trả tiền cho bạn để cuộn xuống hoặc thưởng cho bạn vì chia sẻ meme. Yêu cầu sâu hơn. Nếu dữ liệu của bạn giúp huấn luyện một mô hình tạo ra giá trị thương mại, chuỗi ghi nhận sẽ quay lại với bạn. Đó là một đề xuất hoàn toàn khác biệt so với bất cứ điều gì tôi đã thấy trong lĩnh vực này.
Giờ đây, đây là nơi tôi trở nên chân thực chứ không phải quảng bá. Tầm nhìn là nhất quán. Vấn đề mà nó đang giải quyết là có thật. Nhưng những tầm nhìn nhất quán và những vấn đề thực sự đã tồn tại trong crypto trước đây, và nhiều dự án với cả hai vẫn không đạt được sự chấp nhận có ý nghĩa. Câu hỏi mà tôi vẫn quay lại là liệu những người đóng góp dữ liệu mà OpenLedger cần — những người có dữ liệu huấn luyện thực sự giá trị — sẽ thực sự sử dụng hệ thống này ở quy mô lớn không. Ghi nhận chỉ có giá trị nếu các công ty AI bên dưới sẵn sàng trả tiền cho dữ liệu có nguồn gốc xác minh được. Thị trường đó phải tồn tại. Hiện tại, hầu hết các phòng thí nghiệm AI vẫn đang hoạt động dưới giả định rằng họ có thể sử dụng dữ liệu công khai một cách tự do. Liệu quy định hay áp lực thị trường có thay đổi được tính toán đó hay không thì không được đảm bảo.
Điều tôi thấy thực sự thú vị là OpenLedger không chờ đợi sự chuyển mình đó. Họ đang xây dựng cơ sở hạ tầng ngay bây giờ để khi sự chuyển mình xảy ra.... và tôi nghĩ cuối cùng nó sẽ xảy ra — thì các đường ray đã tồn tại.
Hãy tưởng tượng đến năm 2030 một chút. Một nhà nghiên cứu ở Lagos đóng góp dữ liệu y tế đã chú thích cho một mô hình chẩn đoán. Một lập trình viên ở Jakarta đóng góp mẫu mã cho một hệ thống tạo mã. Cả hai đều nhận được hồ sơ ghi nhận có thể xác minh và phần thưởng $OPEN tỷ lệ với số lần đóng góp của họ được truy vấn. Đó không phải là một giấc mơ. Đó chỉ là cách mà hệ thống này sẽ hoạt động nếu nó hoạt động.
Internet được xây dựng dựa trên sự chú ý của bạn. Câu hỏi bây giờ là phiên bản tiếp theo có được xây dựng theo điều kiện của bạn không..... hay chúng ta chỉ tìm ra một cách tinh vi hơn để lại giá trị đó miễn phí một lần nữa.
Tôi đang theo dõi OpenLedger một cách cẩn thận. Không phải vì sự cường điệu yêu cầu điều đó. Mà vì câu hỏi mà nó đang đặt ra là một câu hỏi chưa ai khác trả lời được.🤔
@OpenLedger #OpenLedger #CryptoVibes

$COS