Hôm nay mình đang nghĩ về @OpenLedger từ hướng ngược lại.
Thường thì, khi mọi người thảo luận về các dự án blockchain AI, họ bắt đầu với cơ hội. Dữ liệu trở nên có thể kiếm lời. Các mô hình trở thành tài sản. Các đại lý trở thành những tác nhân kinh tế. Tính thanh khoản đổ vào những nơi mà giá trị từng bị mắc kẹt. Đó là một luận điểm thú vị, và đó cũng là lý do tại sao $OPEN liên tục xuất hiện trong các cuộc trò chuyện xoay quanh cơ sở hạ tầng AI.
Nhưng câu hỏi hữu ích hơn có thể sẽ không thoải mái: điều gì có thể làm chậm quá trình này?
Không phải vì ý tưởng yếu. Thực ra là ngược lại. Những ý tưởng về cơ sở hạ tầng mạnh thường thất bại hoặc tiến triển chậm khi chúng va chạm với hành vi hiện có, quy định, cấu trúc chi phí, và thói quen của các tổ chức. Vì vậy, thay vì coi #OpenLedger như một câu trả lời hoàn chỉnh, có thể tốt hơn nếu hỏi điều gì cần phải diễn ra trước khi nó được sử dụng rộng rãi.
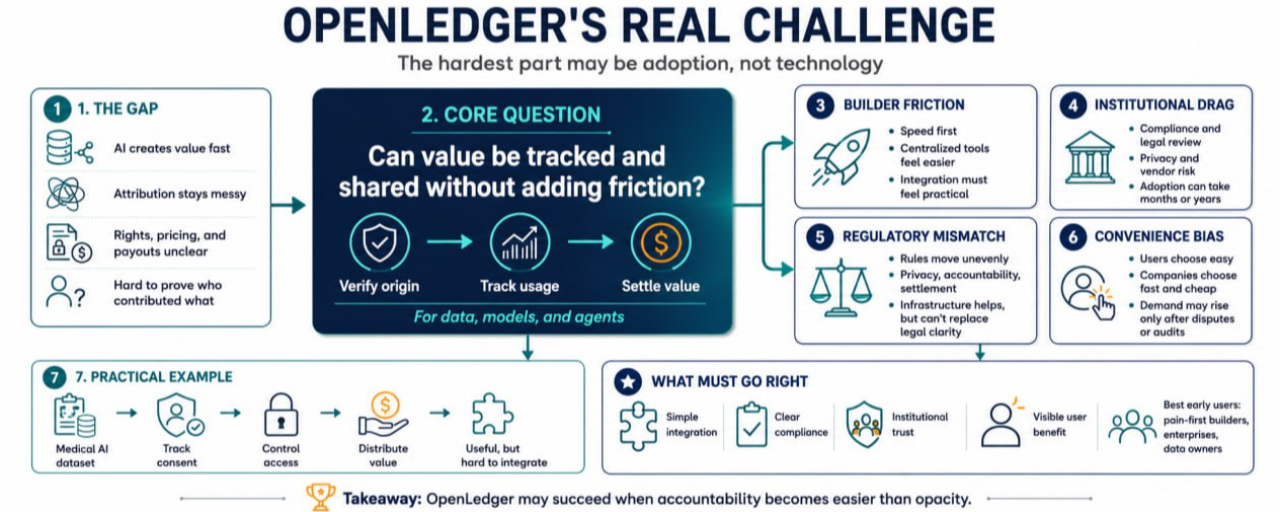
Vấn đề trước OpenLedger
AI đã lan rộng qua các quy trình kinh doanh, nhưng lớp kinh tế xung quanh nó thì lộn xộn.
Một công ty có thể sử dụng dữ liệu từ bên thứ ba, tinh chỉnh các mô hình, triển khai đại lý, và tự động hóa quyết định mà không có cách nào rõ ràng để theo dõi ai đã đóng góp cái gì. Người dùng thường không biết dữ liệu của họ được sử dụng như thế nào. Những người xây dựng có thể không biết cách định giá tài sản AI. Các tổ chức có thể muốn có những dấu vết kiểm toán tốt hơn nhưng do dự trong việc tiết lộ các hoạt động nhạy cảm. Các nhà quản lý vẫn đang cố gắng hiểu nơi nào trách nhiệm bắt đầu và kết thúc.
Điều này tạo ra một khoảng trống kỳ lạ. AI có thể tạo ra giá trị nhanh chóng, nhưng chứng minh nguồn gốc của giá trị đó thì khó hơn nhiều.
Sự tập trung của OpenLedger vào việc mở khóa tính thanh khoản để kiếm tiền từ dữ liệu, mô hình, và đại lý nói trực tiếp đến khoảng trống đó. Tuy nhiên, việc có đúng vấn đề không đảm bảo sự chấp nhận dễ dàng.
Rủi ro Một: Những người xây dựng có thể tránh thêm ma sát
Những người xây dựng thường quan tâm đến tốc độ trước tiên.
Nếu một nhà phát triển có thể xuất bản một ứng dụng AI sử dụng API tập trung, một cơ sở dữ liệu đơn giản, và một nhà cung cấp thanh toán, họ có thể không ngay lập tức quan tâm đến việc định danh sâu hơn hoặc giải quyết. Các đội ngũ giai đoạn đầu thường đang chiến đấu để có người dùng, không phải thiết kế cơ sở hạ tầng kinh tế hoàn hảo.
Đây là một rủi ro thực sự về việc chấp nhận OpenLedger. Ngay cả khi dòng chảy dữ liệu có thể xác minh và các đường ray kiếm tiền là hữu ích, những người xây dựng cần chúng cảm thấy thực tiễn. Nếu tích hợp cảm thấy nặng nề, tài liệu cảm thấy không rõ ràng, hoặc lợi ích đến quá muộn, nhiều đội có thể trì hoãn việc sử dụng nó.
Thách thức không chỉ là kỹ thuật. Nó là hành vi. Con người chấp nhận cơ sở hạ tầng khi nó loại bỏ nỗi đau mà họ đã cảm thấy.
Rủi ro Hai: Các tổ chức di chuyển chậm
Các tổ chức có thể cần cơ sở hạ tầng giống như OpenLedger, nhưng họ hiếm khi là những người áp dụng nhanh.
Ngân hàng, công ty bảo hiểm, công ty chăm sóc sức khỏe, trường đại học, công ty logistics, và các cơ quan công cộng quan tâm đến việc tuân thủ, mua sắm, xem xét pháp lý, rủi ro nhà cung cấp, quyền riêng tư dữ liệu, và phê duyệt nội bộ. Ngay cả khi các lợi ích là rõ ràng, việc triển khai có thể mất hàng tháng hoặc hàng năm.
Đối với các tổ chức, lời hứa về việc kiếm tiền từ dòng chảy dữ liệu AI không đủ. Họ cần tự tin rằng hệ thống có thể đáp ứng các tiêu chuẩn kiểm toán, yêu cầu bảo mật, nghĩa vụ báo cáo, và kỳ vọng quy định.
Đây là nơi mà @OpenLedger phải hơn một mạng lưới thú vị. Nó phải trở nên nhàm chán theo cách tốt nhất có thể: đáng tin cậy, dễ hiểu, và dễ biện minh trong một ủy ban rủi ro.
Rủi ro Ba: Các nhà quản lý có thể không di chuyển đồng bộ
Quy định AI vẫn chưa đồng nhất.
Một khu vực pháp lý có thể tập trung vào quyền riêng tư. Một khu vực khác có thể tập trung vào trách nhiệm của mô hình. Một khu vực khác nữa có thể quan tâm đến việc thanh toán tài chính, bảo vệ người tiêu dùng, hoặc địa phương hóa dữ liệu. Đối với một hệ thống xử lý tài sản AI, quyền dữ liệu, hoạt động của đại lý, và phân phối giá trị, điều này tạo ra một môi trường phức tạp.
OpenLedger có thể giúp bằng cách làm cho các dòng chảy trở nên minh bạch và có thể theo dõi hơn. Nhưng các nhà quản lý có thể vẫn không đồng ý về những gì được coi là chứng cứ chấp nhận được, sử dụng dữ liệu hợp pháp, hoặc bồi thường công bằng.
Sự không chắc chắn đó có thể làm chậm việc chấp nhận. Các tổ chức có thể chờ đợi các quy tắc rõ ràng hơn trước khi cam kết sâu sắc. Những người xây dựng có thể tránh các trường hợp sử dụng có quy định. Người dùng có thể vẫn hoài nghi nếu họ không hiểu cách mà quyền lợi của họ được bảo vệ.
Cơ sở hạ tầng có thể hỗ trợ việc tuân thủ, nhưng nó không thể thay thế sự rõ ràng về pháp lý.
Một Ví dụ Thực Tế: Một Tập Dữ Liệu AI Y Tế
Hãy tưởng tượng một công ty muốn xây dựng một công cụ AI giúp các phòng khám phân tích các mẫu nhập liệu của bệnh nhân.
Dữ liệu có giá trị. Mô hình có giá trị. Đại lý định tuyến trường hợp có giá trị. Nhưng rủi ro là nghiêm trọng. Quyền riêng tư của bệnh nhân phải được bảo vệ. Sự đồng ý phải rõ ràng. Quyền truy cập phải được kiểm soát. Nếu công cụ cải thiện kết quả hoặc giảm chi phí, có thể sẽ có câu hỏi về ai được hưởng lợi tài chính.
Cơ sở hạ tầng kiểu OpenLedger có thể giúp theo dõi quyền hạn, việc sử dụng, và phân phối giá trị. Điều đó sẽ quan trọng đối với những người xây dựng, các tổ chức, người dùng, và các nhà quản lý.
Nhưng việc áp dụng vẫn sẽ khó khăn. Các tổ chức chăm sóc sức khỏe có thể lo lắng về việc phơi bày tuân thủ. Các luật sư có thể đặt câu hỏi liệu mô hình giải quyết có phù hợp với các quy định hiện có hay không. Bệnh nhân có thể không tin tưởng vào những lời hứa mơ hồ về việc kiếm tiền từ dữ liệu. Tích hợp với các hệ thống cũ có thể tốn kém.
Vì vậy, giá trị đề xuất là có thực, nhưng con đường không tự động.
Rủi ro Bốn: Thị trường có thể thích sự tiện lợi
Rủi ro lớn nhất có thể là nhiều người nói rằng họ muốn sự minh bạch, nhưng lại chọn sự tiện lợi.
Người dùng thường nhấp qua các điều khoản mà họ không đọc. Các công ty chọn công cụ rẻ hơn và nhanh hơn. Những người xây dựng tối ưu hóa cho tốc độ ra mắt. Các tổ chức thường trì hoãn thay đổi cơ sở hạ tầng cho đến khi rủi ro trở nên không thể tránh khỏi.
Điều đó không có nghĩa là OpenLedger không thể hoạt động. Nó có nghĩa là nhu cầu có thể tăng trưởng dần dần, đặc biệt sau các tranh chấp, kiểm toán, hoặc áp lực quy định khiến các hệ thống AI không rõ ràng trở nên tốn kém hơn.
Nói cách khác, nhu cầu về OpenLedger có thể chỉ trở nên rõ ràng khi cách xây dựng AI hiện tại bắt đầu bị gãy dưới áp lực thực tế.
Kết luận Cơ bản
Những người dùng sớm có khả năng nhất của OpenLedger có thể là những người xây dựng đã cảm thấy nỗi đau của việc định danh AI, kiếm tiền từ dữ liệu, giải quyết đại lý, hoặc tuân thủ tổ chức. Nó cũng có thể thu hút những người sở hữu dữ liệu muốn được bồi thường, các doanh nghiệp cần khả năng kiểm toán, và các đội ngũ xây dựng quy trình AI mà trong đó niềm tin quan trọng hơn tốc độ đơn thuần.
Nó có thể hoạt động nếu #OpenLedger làm cho việc xác minh và phân phối giá trị cảm thấy đơn giản hơn việc quản lý các thỏa thuận riêng tư, kiểm toán thủ công, và hồ sơ quyền sở hữu không rõ ràng. Nó có thể thất bại hoặc di chuyển chậm nếu tích hợp quá khó, quy định vẫn mơ hồ, hoặc người dùng và công ty tiếp tục chọn sự tiện lợi hơn là trách nhiệm.
Đó là lý do tại sao tôi thấy $OPEN ít là một câu chuyện AI đơn giản và nhiều hơn như một bài kiểm tra hành vi thị trường. Liệu mọi người chỉ muốn AI thông minh hơn, hay họ cũng muốn các hệ thống AI có thể chứng minh cách giá trị được tạo ra và chia sẻ?
Không phải lời khuyên tài chính.
Bạn nghĩ điều gì là rào cản lớn nhất cho OpenLedger: quy định, sự chấp nhận của người xây dựng, niềm tin của tổ chức, hay nhận thức của người dùng?