Nhiều người bây giờ nói về AI, sự chú ý chủ yếu bị mắc kẹt trong cuộc chiến 'mô hình'.
Ai đó đã nhân đôi số lượng tham số, ai đó giảm chi phí suy diễn đến chín mươi phần trăm, ai đó vừa ra mắt Agent IQ lại nghiền nát đối thủ.
Nhưng với tư cách là một 'lão làng' đã ngâm mình trong lĩnh vực này lâu dài, tôi quan tâm hơn đến một cuộc khủng hoảng nền tảng mà toàn ngành đều biết nhưng lại cố tình lờ đi: **Trong đế chế AI đã phình to hàng nghìn tỷ này, tiền, rốt cuộc, chảy về đâu?**
Đặc biệt là việc huấn luyện mô hình này.
Trong suốt mười mấy năm qua, Web2 đã nuôi dưỡng cho chúng ta một logic mặc định cực kỳ vô lý: **nền tảng chịu trách nhiệm xây dựng xưởng, người dùng chịu trách nhiệm làm lao động miễn phí.** Mỗi ngày chúng ta trò chuyện, đăng bài, tải ảnh, góp ý trong các lĩnh vực chuyên môn, những tài sản vô hình này cuối cùng đều được đóng gói thành 'nhiên liệu' cho AI.
* Bạn biết AI đang ngày càng mạnh lên.
* Nhưng bạn không biết nó mạnh lên dựa vào điều gì.
* Bạn càng không biết, ai đang ngồi trong văn phòng offshore, biến giá trị bạn đóng góp thành PPT để huy động hàng tỷ đô la.
Đây chính là một hộp đen hoàn toàn. Toàn bộ ngành AI, giống như một công ty **kiếm được rất nhiều nhưng không bao giờ ghi sổ và cũng không công khai báo cáo tài chính.**
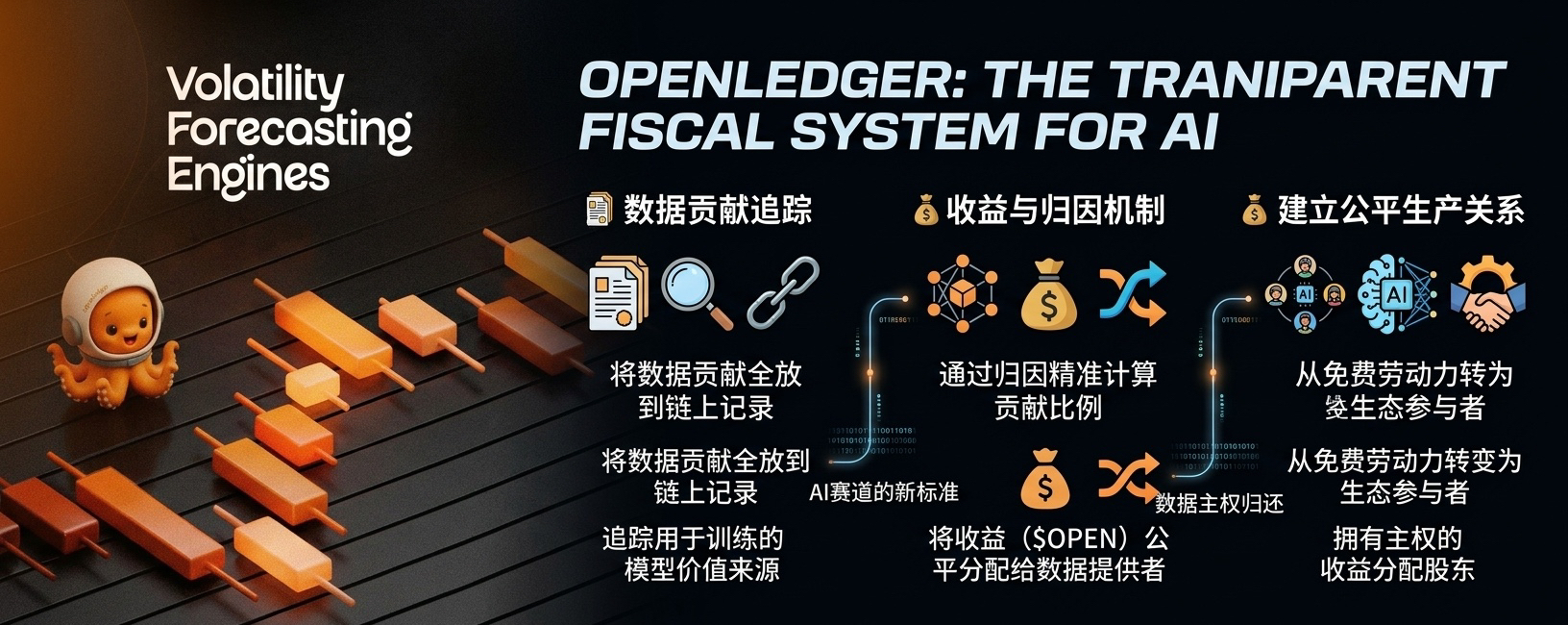
Và gần đây, sự thảo luận về @OpenLedger trên Twitter ngày càng cao, chính là vì dự án này đã làm một công việc cách mạng cực kỳ quan trọng - **nó đã đến để xây dựng 'hệ thống tài chính minh bạch' cho ngành AI.**
Nhét các mối quan hệ sản xuất vào 'sổ cái công khai'.
Cái gọi là tài chính minh bạch trong lĩnh vực AI là gì?
Nói đơn giản, chính là nhờ vào tính không thể sửa đổi của blockchain, tất cả các **đóng góp dữ liệu, tiến trình mô hình, phân phối lợi nhuận** trong quá trình đào tạo AI đều được ghi lại trên chuỗi.
Nếu hình dung ngành AI thành một nhà máy lớn hiện đại:
Công ty mô hình chính là *chủ xưởng*.
Công suất tính toán là *máy móc trong dây chuyền sản xuất*.
Dữ liệu chính là *nguyên liệu*.
Trước đây, khi các ông chủ nắm giữ quyền định giá, họ mặc định rằng nguyên liệu trên internet có thể được 'mua 0 đồng' vô hạn, nhưng với việc các mô hình lớn bước vào vùng nước sâu, mô hình khai thác này không thể tồn tại.
Bởi vì dữ liệu chất lượng cao thực sự có thể tạo ra sự khác biệt trong mô hình - như những trường hợp ngành thực tế, phản hồi từ các chuyên gia trong các tình huống chuyên nghiệp, logic hành vi cực kỳ cá nhân hóa - những thứ này trên mạng công cộng cực kỳ khan hiếm, không thể chỉ dựa vào bot để sao chép hàng loạt.
OpenLedger đã cắt vào chính là hệ thống đóng góp dữ liệu có thể truy xuất này.
Logic mà nó cố gắng giải quyết rất cứng cáp: dữ liệu nào thực sự tham gia vào việc đào tạo? Dữ liệu nào đóng góp chủ chốt vào việc nâng cao độ chính xác (Accuracy)? Sau khi xác định rõ, hãy thông qua cơ chế phân bổ trên chuỗi để phân phối công bằng lợi nhuận $OPEN đến tay người đóng góp.
Điều này đã đảo lộn mối quan hệ sản xuất mà internet đã tích lũy trong hai mươi năm: **người dùng không còn là nguyên liệu dữ liệu bị khai thác miễn phí, mà trở thành những cổ đông thực sự có chủ quyền trong hệ sinh thái AI.**
Tại sao lại nói rằng 'độ minh bạch' quyết định sự sống còn của lĩnh vực AI?
Khi quy mô ngành còn nhỏ, sự không minh bạch có thể được giải thích là sự phát triển hoang dã của 'khởi nghiệp vườn rau'. Nhưng hiện tại, AI đang tái cấu trúc nền tảng xã hội nhạy cảm và tài sản nặng như tài chính, y tế, giáo dục.
* Một Agent tài chính đề xuất cho bạn danh mục tài sản, nếu nguồn dữ liệu đào tạo của nó không rõ ràng, bạn có dám đổ vài triệu vào không?
* Một mô hình chẩn đoán y tế, nếu dòng lợi ích đứng sau nó không rõ ràng, thì bác sĩ và bệnh nhân làm sao có thể giao phó niềm tin?
Vì vậy, sự kết hợp giữa ngành Web3 và AI không hề đơn giản chỉ là 'phát hành một đồng meme AI'. **Ngành AI đã đến mức cần một cuốn sổ cái công khai, có thể xác minh không thể thiếu.**
OpenLedger lúc này đã nhảy vào để ghi lại trên chuỗi, đưa ra một câu trả lời công nghiệp có vẻ hợp lý nhất.
Lý tưởng thì hấp dẫn, nhưng thực tế thì xương xẩu.
Tất nhiên, chúng ta hãy nói những điều thực tế: **câu chuyện này nghe có vẻ hấp dẫn đến nỗi bùng nổ, nhưng khó khăn kỹ thuật để thực hiện lại rất lớn.**
Quá trình đào tạo mô hình AI là một phản ứng hóa học cực kỳ phức tạp. Một lần tối ưu hóa tinh chỉnh hàng tỷ tham số, có thể có sự giao thoa của hàng triệu dữ liệu ô nhiễm chéo, nhiều vòng giảm độ dốc phức tạp, và hàng ngàn GPU phối hợp.
Làm thế nào để trong một khối lượng tính toán khổng lồ như vậy, *ghi lại một cách chính xác và với chi phí thấp* đóng góp của một tập dữ liệu cụ thể?
* Làm thế nào để vừa ngăn chặn việc thao túng dữ liệu, vừa chống lại tấn công 'phù thủy', trong khi vẫn đảm bảo phân phối lợi nhuận hoàn toàn công bằng?
Những điều này vẫn là điểm đau ở rìa của khoa học máy tính và mật mã. Vì vậy, ở giai đoạn hiện tại, tôi có xu hướng hiểu OpenLedger như một **hướng đi khám phá mang tính tiên phong cực kỳ quan trọng**.
Nó không đi theo xu hướng làm những ứng dụng hời hợt không thể mang lại tương lai, mà là xắn tay áo, cố gắng đưa sự tham lam và hỗn loạn ẩn giấu trong hộp đen của ngành AI ra ánh sáng.
Còn về tương lai nó có thể tiến triển đến mức nào, chúng ta với tư cách là người quan sát cần cho nó thời gian, xem dữ liệu mạng chính và độ dày sinh thái của nó để xác minh. Nhưng ít nhất nó đã ném ra một câu hỏi sâu sắc không thể tránh khỏi cho toàn ngành:
Tương lai của thế giới AI có giá trị hàng nghìn tỷ, liệu rằng việc phân phối lợi nhuận của nó có nên minh bạch hơn không?
Hoan nghênh các bạn thảo luận trong phần bình luận: bạn nghĩ rằng việc để nền tảng AI 'công khai đối chiếu' sẽ gặp phải trở ngại lớn nhất từ đâu?