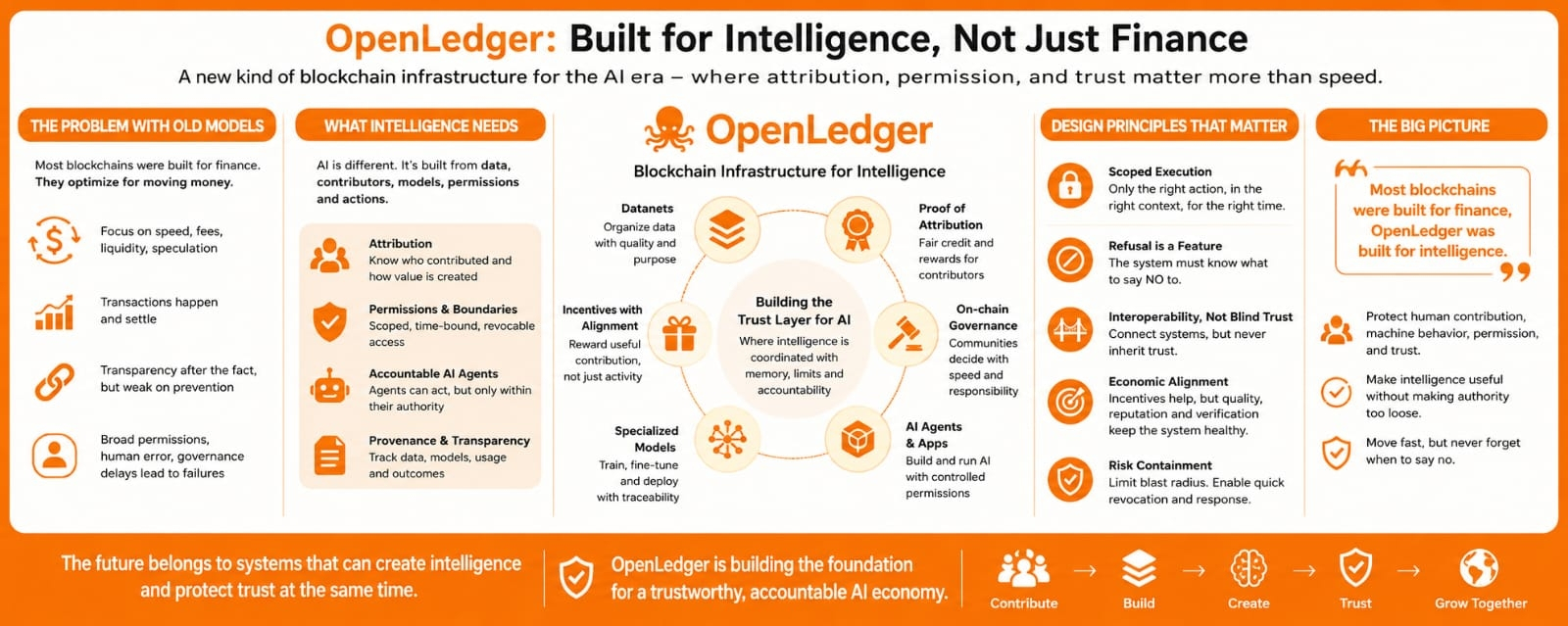
OpenLedger with a different kind of attention, not because it is another blockchain trying to sound faster or newer, but because it is trying to sit closer to the place where AI actually becomes messy. Most blockchains were built around finance. They were built for markets, transfers, liquidity, collateral, settlement, and speculation. OpenLedger is trying to deal with something less clean than money: intelligence. And intelligence is harder to contain because it is built from data, human input, model behavior, permissions, incentives, and trust.
That is the part I keep coming back to. Finance has clear movements. Money leaves one place and enters another. A transaction happens, settles, and becomes history. Intelligence does not behave that neatly. It keeps learning, reusing, combining, remembering, and acting. A model can become valuable because many people contributed data or feedback. An agent can perform a task because someone gave it permission. A dataset can shape outputs long after the original contributor has stopped paying attention. So the real question is not only whether OpenLedger can make AI activity happen on-chain. The deeper question is whether it can make that activity accountable.
OpenLedger becomes interesting when you stop looking at it as just another AI crypto project and start looking at it as an attempt to build a trust layer for intelligence. That means tracking where value comes from. It means asking who contributed to a model, who deserves attribution, who gets rewarded, and what permissions were involved along the way. These are not small details. In AI, the details are the system. If nobody knows where the data came from, who shaped the model, or how the output became valuable, then the same old problem returns. The people who create value become invisible, while the platforms sitting above them capture most of the upside.
That is why OpenLedger’s focus on attribution matters. It is easy for any project to say contributors should be rewarded. It is much harder to build a system that can prove contribution in a meaningful way. AI value is rarely created by one clean input. It usually comes from many layers: datasets, users, feedback, prompts, models, agents, applications, and repeated usage. OpenLedger is trying to make those layers more visible. Not just for storytelling, but for economic reasons. If intelligence is going to become an asset, then the system needs to remember who helped create it.
But attribution is only one side of the problem. The other side is permission. This is where I think OpenLedger has to be judged seriously. AI systems do not only need access to data. They need controlled access. They need clear boundaries. A contributor may allow data to be used in one context, but not everywhere. A user may allow an AI agent to perform one task, but not make open-ended decisions. A model may be useful in one environment, but risky in another. If all permissions become broad permissions, then the system becomes easier to use in the short term and more dangerous in the long term.
This is where many systems fail quietly. They do not fail because people are evil. They fail because people are rushed. A team gives too much access because deadlines are tight. A user signs something because it looks familiar. A developer reuses an approval because it saves time. A governance process exists, but it moves too slowly when something goes wrong. A permission that looked harmless becomes dangerous once the system grows. That is the real world. Good infrastructure has to be designed for tired humans, impatient teams, and incentives that do not always point in the right direction.
OpenLedger’s challenge is to prove that intelligence can be coordinated without becoming loose. If the project is serious about AI infrastructure, then it cannot only be fast or compatible or easy to connect with. It has to be disciplined. It has to care about what should happen, but also what should not happen. It has to support builders without letting every shortcut become normal. It has to reward contributors without inviting empty farming. It has to let AI agents act without giving them unlimited authority. That balance is difficult, and that is exactly why it matters.
“Trust does not fail slowly enough for people to prepare.” I think that line fits this space because most failures are obvious only after they happen. Before that, they look like convenience. They look like flexible permissions. They look like faster onboarding. They look like fewer steps for users. They look like growth. But after something breaks, everyone suddenly realizes the boring controls were not boring at all. They were the system’s immune system.
This is also why interoperability should be treated carefully. OpenLedger can benefit from being connected to familiar blockchain environments and developer tools, but connection is not the same as trust. A bridge can move value. Compatibility can reduce friction. A shared ecosystem can make building easier. But none of that removes the need for strong boundaries. If anything, the more connected a system becomes, the more important its permission design becomes. When intelligence moves across systems, weak assumptions can travel with it.
The same is true for token incentives. Incentives can help OpenLedger attract contributors, validators, developers, and users. They can encourage people to participate in building datasets and models. But incentives also bring noise. They attract people who want rewards more than they want quality. They can turn contribution into a game. They can make activity look like adoption. So OpenLedger cannot be measured only by how much participation it creates. It has to be measured by whether that participation produces useful intelligence, reliable attribution, and long-term demand.
That is the difference between a project that looks alive and a system that becomes necessary. A project can create noise. A system creates dependency. If builders, agents, models, and applications keep returning to OpenLedger because they need its attribution, data coordination, and trust structure, then the project becomes more than a narrative. But if the activity depends mostly on incentives, campaigns, or market attention, then it remains fragile. The real test comes after the early excitement fades.
I also think OpenLedger is working in a space where governance cannot be treated as decoration. AI infrastructure will create disputes. People will disagree about contribution, rewards, data quality, permissions, and model usage. Some contributors will feel underpaid. Some builders will want more freedom. Some users will want more safety. Some token holders will push for growth even when restraint is needed. Governance has to handle those tensions before they become crises. If governance only reacts after trust is already damaged, it becomes a postmortem tool, not a protection layer.
This is why refusal matters. A serious intelligence network has to know when to say no. No to bad data. No to unclear contribution. No to expired permission. No to an agent acting outside its scope. No to rewards that encourage useless activity. No to shortcuts that make growth look better but make the system weaker. In crypto, people often celebrate systems that execute quickly. But for intelligence, execution is not enough. A system that can execute anything without strong limits can scale mistakes faster than humans can correct them.
“The real test of infrastructure is not what it can execute, but what it can refuse.” That is the sentence I would keep near OpenLedger’s core challenge. If the project is built for intelligence, then its value will not come only from helping AI systems move faster. It will come from helping them move with memory, limits, attribution, and accountability. That is much harder than launching another market or another chain. It requires patience. It requires discipline. It requires saying no to some easy growth.
OpenLedger should be watched through that lens. Not as a perfect answer, and not as something that deserves belief just because AI and blockchain are both powerful narratives. It should be watched as a serious attempt to solve a serious coordination problem. Who owns intelligence? Who contributes to it? Who gets paid when it creates value? Who controls access? Who can revoke permission? Who is responsible when an AI agent acts? These are the questions that will matter more as AI becomes more active and less passive.
Most blockchains were built for finance, so they learned to protect money. OpenLedger is trying to deal with intelligence, so it has to protect something more complicated: human contribution, machine behavior, permission, memory, and trust. That is a heavier responsibility. The future will not belong only to systems that are fast. It will belong to systems that can stay disciplined when speed becomes dangerous. Mature infrastructure is not just the infrastructure that says yes quickly. It is the infrastructure that knows when saying no is the only thing keeping trust alive.