Ive seen enough crypto cycles now that I automatically distrust anything with “AI” in the bio.
Usually it’s the same formula every time. Somebody launches a token, adds “agent” somewhere in the roadmap, posts futuristic graphics, and suddenly CT acts like we’re five months away from autonomous economies replacing civilization.
Meanwhile the product is a chatbot wrapper with staking.
So yeah, I went into OpenLedger expecting more of that.
But after digging through it for a while, I don’t think the interesting part here is the AI narrative at all. The interesting part is that they’re poking at something the tech industry has been quietly avoiding for years:
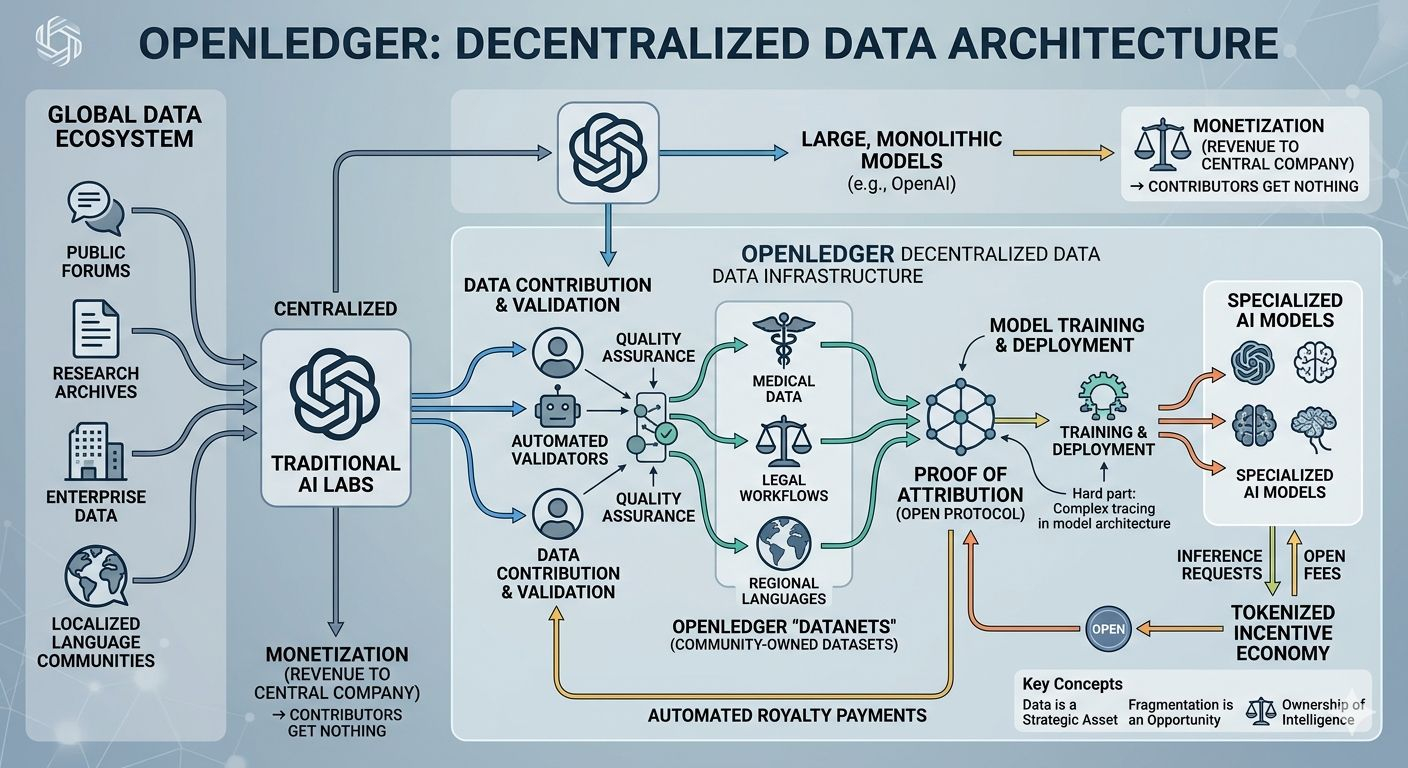
AI companies are building trillion-dollar businesses on top of data they mostly didn’t create.
And people have just… accepted that somehow.
The internet trained these models. Forums, articles, research archives, open-source repos, random niche communities, years of human behavior online. All of it got vacuumed into training pipelines. Then the companies that did the scraping became the owners of the resulting intelligence layer.
That arrangement looked normal when nobody was making money yet.
Now it looks different.
Especially when AI companies start charging enterprises billions while the underlying contributors get nothing except maybe their website traffic disappearing.
OpenLedger is basically trying to build accounting rails around that problem. That’s my simplified read of it anyway.
The project talks a lot about attribution. Which, honestly, immediately triggers my skepticism because “attribution” inside machine learning is messy as hell. Anybody pretending this is solved is either selling tokens or hasn’t spent enough time around actual ML systems.
Neural networks don’t work in neat little boxes. You can’t perfectly trace one output back to one contributor the same way Spotify tracks song royalties. Models absorb patterns across absurdly large parameter spaces. Things blur together.
So whenever I hear “Proof of Attribution,” my first instinct is not excitement. It’s: okay, show me the hard part.
Still. Even with that skepticism, I think OpenLedger is at least looking in the right direction while most crypto AI projects are busy speedrunning hype cycles.
Because the current AI economy really does have a structural issue.
Data is becoming more valuable at the exact same time it’s becoming harder to get.
People underestimate this. They still think the moat is compute alone. Compute matters obviously — Nvidia basically became a sovereign empire overnight because of it — but good datasets are turning into strategic assets now.
Not massive piles of generic internet garbage. Everyone already scraped that.
I mean domain-specific data.
Medical data.
Legal workflows.
Regional language datasets.
Enterprise information that companies don’t want leaking into random public models.
That’s where things get interesting.
And OpenLedger seems to understand that the future probably isn’t one giant model eating the entire market. More likely there will be thousands of smaller specialized systems trained around specific industries, regions, or knowledge bases.
At least that’s how I see it.
The funny thing is crypto might actually fit that world better than centralized AI labs do. Not because crypto is magically better technology. Usually it isn’t. But because fragmented incentive systems are weirdly good at serving niche markets.
A massive centralized AI company doesn’t care much about small language communities unless there’s huge revenue attached. A decentralized network can survive smaller pockets of demand because contributors and operators are distributed differently.
That’s probably OpenLedger’s real opening.
Not competing with OpenAI directly. That would be suicidal.
The project has these “Datanets,” which are basically community-owned datasets that developers can use for training or fine-tuning models. Then there’s the whole model layer where people deploy AI systems and charge for inference through the OPEN token.
In theory, fees flow back toward contributors whose data helped the models.
In theory.
That phrase matters a lot here.
Crypto people are very good at designing elegant diagrams that collapse instantly once real incentives hit them. And this design absolutely has incentive risk written all over it.
The second you start rewarding data contributions financially, you invite spam. Mountains of it. Low-quality uploads. Synthetic junk. People gaming metrics. Sybil attacks. Same behavior you see everywhere else in crypto, just attached to AI pipelines now.
Honestly I think the biggest challenge for OpenLedger isn’t technical infrastructure. It’s maintaining signal quality once money starts moving aggressively through the system.
That’s harder than people think.
The token itself is pretty standard infrastructure design:
payments,
staking,
governance,
access,
rewards.
Nothing shocking there.
What matters is whether the network eventually produces actual inference demand instead of circular token activity pretending to be usage. Crypto has a long history of mistaking emissions for traction. People see wallet growth and start celebrating while half the wallets are just farming future allocations through scripts.
I’m already seeing some of that behavior around OpenLedger. Browser extension farming, node campaigns, incentive loops. Normal early-stage crypto stuff.
Doesn’t mean the project is fake. It just means numbers need context now. Always.
The funding side is solid though. Polychain backing definitely gives it more credibility than the average AI vaporware launch. Serious infrastructure investors usually don’t waste time on pure meme-layer projects.
Still, VC money alone stopped impressing me a long time ago. This industry has entire cemeteries full of heavily funded protocols nobody remembers anymore.
What keeps me watching OpenLedger is the broader direction, not the current metrics.
Because I think the AI market is heading toward a collision eventually.
Right now the industry still operates on this implicit assumption that centralized companies can absorb the world’s information, monetize it, and everybody else just accepts the arrangement forever.
I doubt that lasts.
Regulators are circling already. Copyright lawsuits keep stacking up. Enterprises increasingly want traceability around training data. And honestly, regular users are becoming more aware that their content helped build systems they don’t participate in economically.
That pressure builds slowly. Then suddenly all at once.
If attribution becomes mandatory — legally or commercially — projects like OpenLedger start looking less experimental and more necessary.
Or maybe not. Maybe the entire category collapses under complexity and nobody cares enough to decentralize this layer. That’s possible too.
There’s a version of the future where centralized AI wins completely because convenience beats philosophy every time. Most users don’t care where models came from as long as outputs are good and cheap.
Crypto people forget that sometimes.
But even if OpenLedger never dominates anything, I still think the underlying idea matters:
data probably shouldn’t be treated like free raw material forever.
That model already feels unstable.
And honestly, this is one of the few AI-related crypto projects where I can at least see the real-world tension underneath the token narrative. That alone separates it from 90% of the sector right now.
Most AI coins are selling science fiction.
OpenLedger is reacting to an economic imbalance that actually exists.