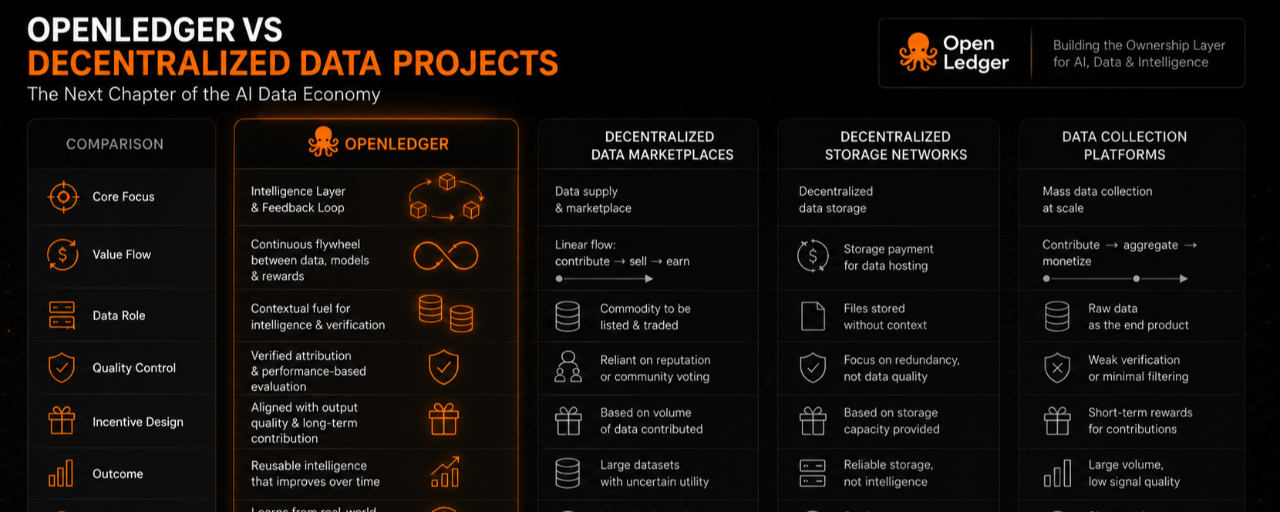
The longer I observe decentralized data projects, the more I feel that most discussions are focused on the wrong competition.
People often frame it as a race for data supply.
Who can collect the most data. Who can attract the largest number of contributors. Who can build the biggest marketplace.
But that may only be the surface layer.
Data itself has never been the truly scarce resource.
What's much harder to find is a system capable of transforming raw data into intelligence that can be verified, continuously improved, and repeatedly generate value.
That's why I find OpenLedger particularly interesting when compared to many decentralized data initiatives that have emerged over the past few years.
Most projects operate on the assumption that if enough data can be gathered, the rest of the ecosystem will naturally develop around it.
In theory, that makes sense.
In practice, however, data is rarely the missing ingredient.
The real challenges are context, quality assessment, and understanding which datasets actually produce better outcomes than others.
More importantly, many systems still struggle to connect contributors with the value their data helps create.
From my perspective, OpenLedger appears to approach this challenge differently.
Rather than focusing solely on building a massive repository of information, the goal seems to be creating a feedback loop where data, AI models, and economic incentives continuously reinforce one another.
At first glance, that may sound like a small design difference.
In reality, it creates entirely different behavioral incentives.
Because people don't respond to technology alone.
They respond to incentives.
Many decentralized data projects encourage users to contribute data first and then attempt to discover ways to extract value from it afterward.
Some newer approaches, including OpenLedger, appear to reverse that process.
The value generated by outputs becomes the starting point, while data serves as one component within a larger value-creation cycle.
What looks like a product decision may actually reflect a broader shift in how the market thinks about AI.
The first wave was obsessed with models.
The next wave became obsessed with data.
Now attention seems to be shifting toward a different question:
How do we build systems that continuously learn from real-world interactions instead of simply accumulating larger datasets?
Because data is not static.
It's a reflection of human behavior.
And human behavior changes constantly.
What is highly relevant today can become obsolete within months as people change how they search, communicate, and make decisions.
A model trained on yesterday's reality may not be optimized for tomorrow's.
Perhaps that's why I keep paying attention to projects like OpenLedger.
Not because they've fully solved the decentralized data challenge.
But because they're exploring a more fundamental question.
If an AI-driven economy eventually emerges, where will the real value reside?
In owning the data?
In owning the models?
Or in owning the feedback loop that continuously connects the two?
I don't think the market has reached a clear answer yet.
But it increasingly feels like the next major competition won't be about who possesses the most data.
It will be about who can build systems that keep data valuable as the world—and human behavior—continue to evolve.