 Sáng nay mình mở OpenLedger dashboard, nhìn vào một luồng dữ liệu chạy qua các AI trading agent đang kết nối với nhau qua nhiều node. Không phải kiểu order book quen thuộc, mà giống như từng agent đang “đọc” cùng một lớp context thị trường được chia sẻ.
Sáng nay mình mở OpenLedger dashboard, nhìn vào một luồng dữ liệu chạy qua các AI trading agent đang kết nối với nhau qua nhiều node. Không phải kiểu order book quen thuộc, mà giống như từng agent đang “đọc” cùng một lớp context thị trường được chia sẻ.
Thị trường thường nghĩ OpenLedger chỉ là một lớp hạ tầng giúp AI trading nhanh hơn, tối ưu execution tốt hơn. Trước đây mình cũng nghĩ gần giống vậy, kiểu chỉ cần data nhanh hơn thì alpha sẽ xuất hiện. Nhưng khi nhìn sâu vào cách OpenLedger vận hành, mình bắt đầu thấy vấn đề không nằm ở tốc độ mà nằm ở context.
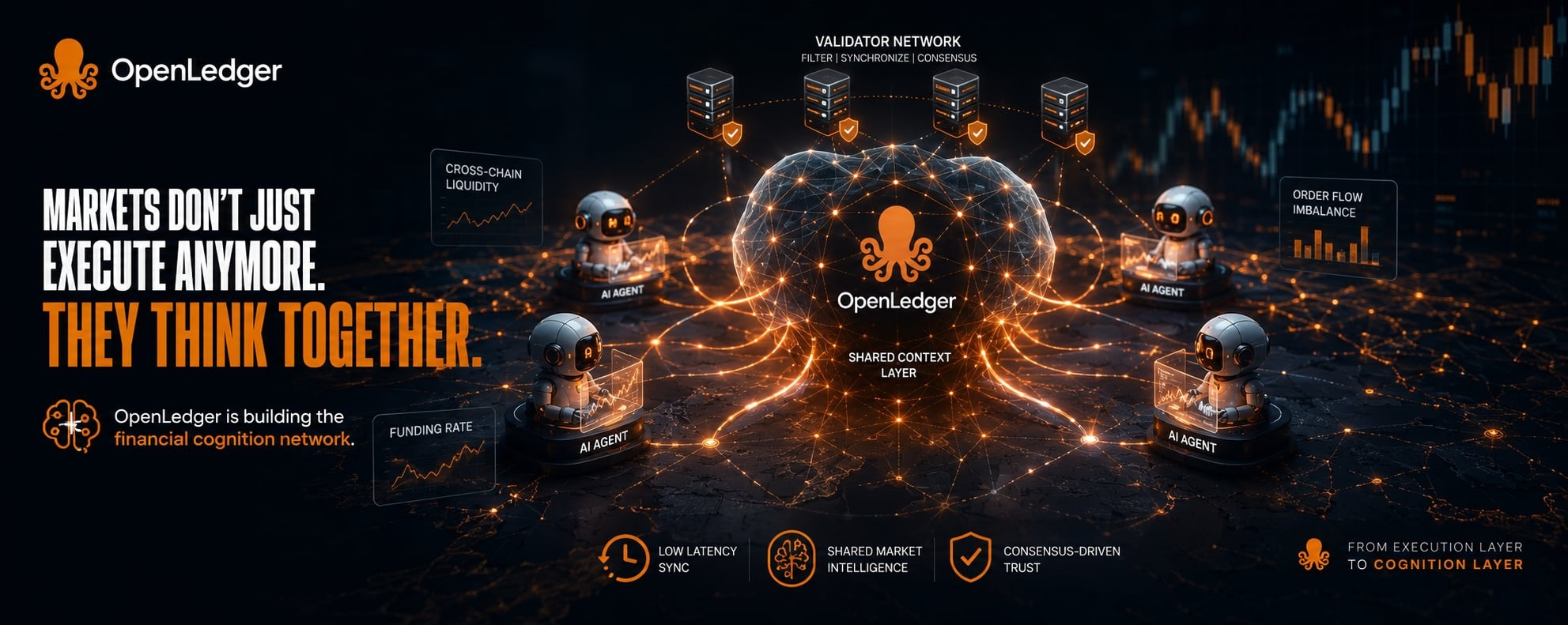
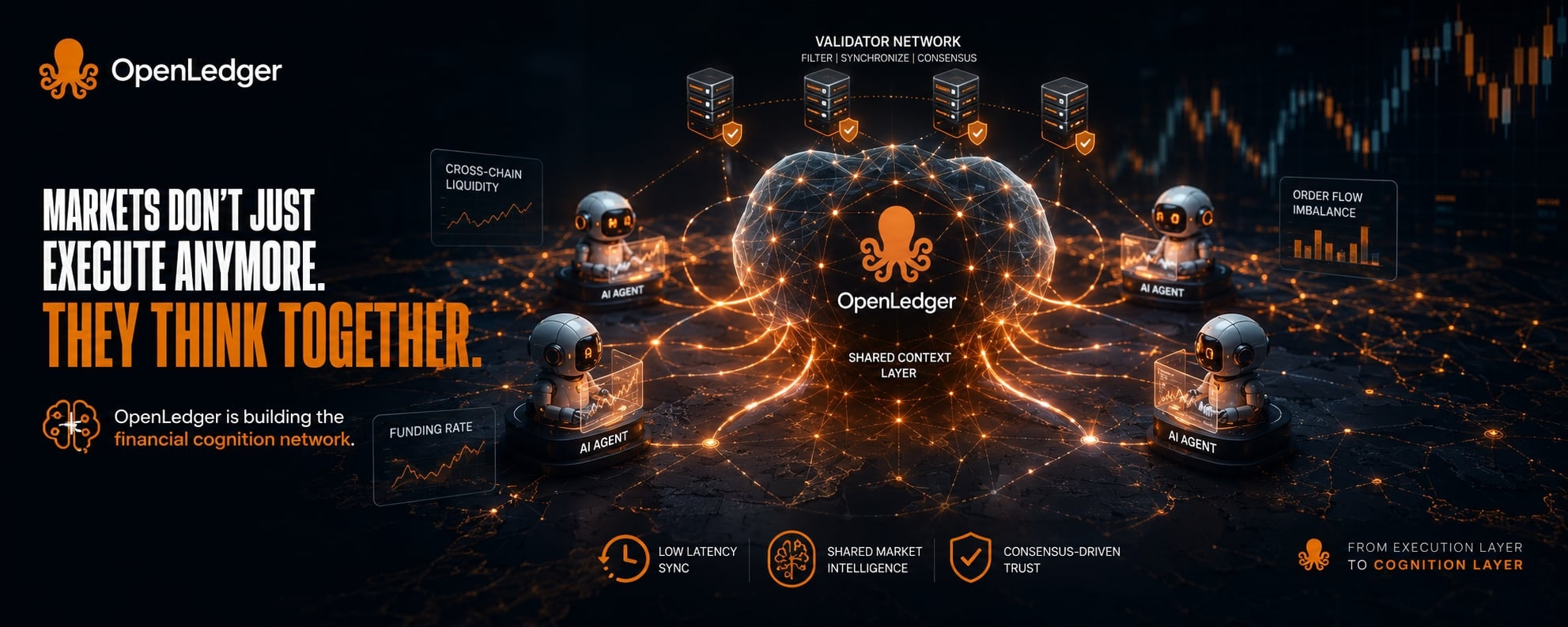
Mình từng xem một luồng AI bot trong OpenLedger xử lý cùng lúc nhiều tín hiệu liquidity từ các chain khác nhau. Điều làm mình dừng lại là cách OpenLedger không để trạng thái tồn tại riêng lẻ trong từng agent. Thay vào đó, một số agent nhận “shared state snapshot” theo từng block interval, nơi funding rate, order flow imbalance và cross-chain liquidity shifts được normalize thành một lớp context chung. Không phải full data, mà là một dạng compressed state do OpenLedger định nghĩa để các agent có thể đọc giống nhau. Một bot không chỉ phản ứng với giá mà còn phản ứng với trạng thái được phân phối qua OpenLedger.
Có lúc mình thấy giống như chúng đang trade dựa trên cùng một bộ nhớ ngắn hạn mà OpenLedger tạo ra cho toàn hệ thống thị trường. Có một lần mình thấy độ trễ cập nhật snapshot chỉ lệch vài block, nhưng đủ để một nhóm agent đi trước, nhóm còn lại phản ứng như thể đang nhìn một thị trường đã “cũ hơn” một nhịp. Khoảnh khắc đó làm mình hơi nghi ngờ cách mình từng nghĩ về real-time trong crypto.
Trong quá trình research mình bắt đầu chú ý đến một design mà OpenLedger đang thử nghiệm có thể gọi tạm là financial cognition networks. Hiểu đơn giản thì đây không chỉ là nơi AI chạy trading mà là nơi OpenLedger truyền intelligence giữa nhiều hệ thống tài chính khác nhau thông qua shared context layer và validator-driven synchronization. Validator trong OpenLedger đóng vai trò như một lớp lọc nhận thức, chọn ra phần thông tin đủ ổn định để trở thành context chung.
Điểm quan trọng là trong OpenLedger, không phải mọi tín hiệu đều được đưa vào “bộ nhớ thị trường”, chỉ những tín hiệu đủ nhất quán giữa nhiều nguồn mới được giữ lại. Nhưng cũng có lúc mình tự hỏi, nếu validator của OpenLedger chọn sai “cái ổn định”, thì cả hệ thống có đang đồng thuận trên một ảo giác hợp lý không.
Nếu nói dễ hình dung, OpenLedger giống như một hệ thần kinh tài chính. Mỗi AI agent trong OpenLedger là một neuron, còn context layer là dòng điện chạy xuyên qua toàn bộ mạng mà OpenLedger duy trì. Nhưng khác với sinh học, ở đây “ký ức” không tích lũy tuyến tính mà có thể bị tái cấu trúc theo cơ chế đồng thuận của OpenLedger.
Cái làm mình thấy thú vị là trong OpenLedger, intelligence không còn nằm ở từng bot riêng lẻ nữa. Nó bắt đầu trở thành thứ có thể flow qua lại, nhưng không phải flow tự do, mà bị định hình bởi cấu trúc đồng thuận mà OpenLedger thiết kế.
Tất nhiên thiết kế của OpenLedger này không phải không có trade-off. Khi context được chia sẻ rộng trong OpenLedger, câu hỏi về noise amplification trở nên rất rõ. Một sai lệch nhỏ trong validation layer của OpenLedger có thể lan thành “false consensus” cho toàn bộ agent network. Và thêm nữa là latency giữa việc cập nhật context và execution thực tế trong OpenLedger luôn tồn tại, khiến một số bot phản ứng với “quá khứ đã được đồng thuận” thay vì hiện tại.
Mình chưa chắc OpenLedger sẽ đi đến đâu, nhưng mình thấy chính OpenLedger đang dịch chuyển crypto infrastructure từ nơi chỉ thực thi giao dịch sang nơi hình thành và đồng bộ nhận thức giữa các hệ thống. Có thể financial cognition network không phải đích đến, mà chỉ là một bước trung gian để thị trường bắt đầu học cách “nghĩ chung” thay vì chỉ phản ứng riêng lẻ.
@OpenLedger #OpenLedger $OPEN $LAB
