
Чому OpenLoRa для @OpenLedger - не одна з технічних оптимізацій, а критична передумова, я сформулював не з опису самої технології, а з математики в зворотній бік. Не що OpenLoRA робить, а що було б без неї.
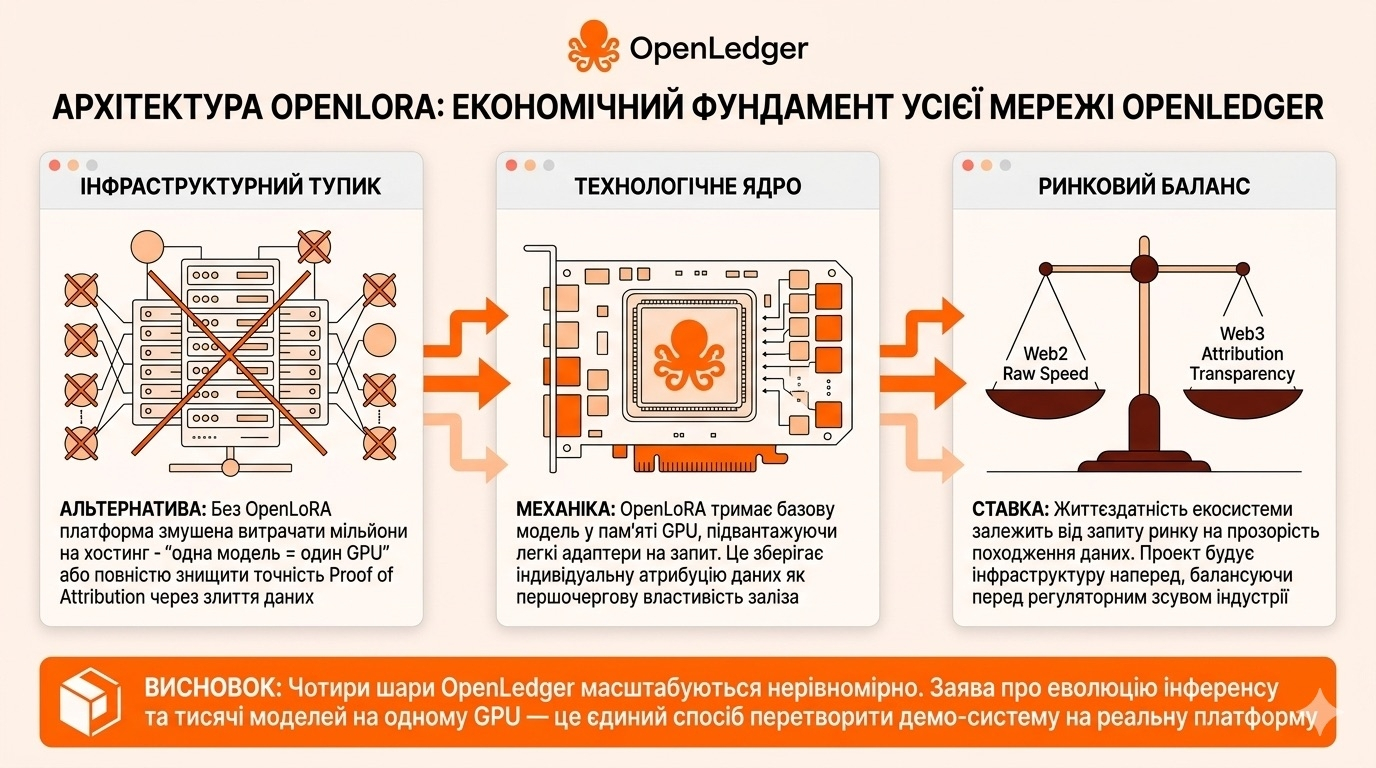
Спочатку коротко, що OpenLoRA взагалі робить. Це інфраструктура для запуску багатьох fine-tuned моделей на одному GPU. Проект заявляє можливість одночасно обслуговувати тисячі LoRA-адаптерів на одній відеокарті - через динамічне підвантаження адаптерів на запит, real-time merge, 4-bit квантизацію, flash attention. Цифру "тисячі" і обіцянку економії до 90% на deployment OpenLedger подає за результатами внутрішніх тестів - публічного незалежного бенчмарку з конкретними числами я не знайшов. Технічні механіки прозорі, gitbook їх описує. Економічна заявка - проектна.

А тепер математика в зворотній бік, без OpenLoRA. Proof of Attribution працює на рівні окремої моделі. Кожен fine-tuned варіант - окрема одиниця, для якої треба відстежити, які дані вплинули на її виходи. Якщо OpenLedger хоче бути платформою, де живуть, скажімо, тисячі моделей від різних виробників - юридичні моделі, медичні, торгові, нішеві асистенти - постає питання, як це фізично хостити. Класичний шлях - одна модель, один GPU. Щоб задіяти тисячу GPU безперервно, потрібен майданчик, який може дозволити собі цей величезний рахунок. Це не Web3 економіка з мікроплатежами через x402 - це AWS-економіка. Інший шлях - згорнути моделі в одну і викликати її різними промптами. Тоді PoA втрачає прив'язку до конкретних контриб'юторів - усе зливається в один загальний пул впливу. Економіка attribution руйнується.
OpenLoRA - спроба третього шляху. Технічно це означає, що базова модель тримається в пам'яті GPU постійно, а LoRA-адаптери, які перетворюють її на конкретний fine-tuned варіант, підвантажуються на запит і вивантажується після обробки. Така архітектура зберігає окремість моделі - адаптер належить конкретному файнтюну, його ваги окремі. Це залишає прив'язку attribution на рівні окремої моделі, без злиття. Якщо механіка справді робить те, що заявлено, OpenLedger отримує можливість мати тисячі моделей одночасно без потреби розгортати тисячі GPU. А значить, x402-мікроплатежі за виклик однієї моделі мають економічний сенс - бо інфраструктурна вартість одного виклику дрібна.
Тут потрібна чесність. Заявку підкріплює незалежний галузевий огляд CryptoNewsNavigator від квітня - там OpenLoRA v2.0 названо actually useful technical product зі знаком якості zero tradeoff on attribution tracking. Це сильніше за переказ прес-релізу - аналітик вирізнив саме той аспект, що критичний для PoA-економіки. Але це огляд, не бенчмарк. Конкретних цифр - latency, реальна кількість адаптерів у проді - в публічних джерелах нема. Розрив між заявкою і доказом менший за 5 TPS, але він є.

Що мене зачіпає в цій історії - не сам факт оптимізації інференсу. Зачіпає те, що OpenLoRA міняє характер проблеми. Якщо її розглядати як ще один швидкий serving framework - це конкуренція з безліччю корпоративних і open-source рішень, які роками вкладали інженерію саме в швидкість інференсу. Але OpenLoRA вирізняється тим, що вона єдина в цьому списку, яка з самого початку зберігає attribution як first-class властивість. Решта оптимізують швидкість і вартість, але байдужі до того, чию модель і чиї дані обробляють. OpenLoRA - повільніша або ні, я не знаю, але вона тримає прив'язку до окремої моделі. Це не технічна перевага, це інша задача.
І тут постає питання, яке для мене досі залишається нерозв'язаним. OpenLedger робить ставку на те, що ринок цінуватиме attribution. Якщо ринок цінуватиме - вибір на користь OpenLoRA логічний навіть при гіршій швидкості. Якщо не цінуватиме - розробники підуть туди, де дешевше і швидше, а attribution лишається красивою ідеєю без споживача. Один із реалістичних сценаріїв - проект чесно будує важливу інфраструктуру, на яку запит з'явиться через два-три роки, коли регулятори дотиснуть AI-компанії на питанні походження даних. Інший - він її будує тоді, коли вже пізно, бо ринок встиг сформуватися без неї. Між цими двома сценаріями OpenLedger балансує, і саме на цьому балансі тримається його довгострокова цінність, а не на найближчих гучних анонсах.
Якщо звести докупи. Чотири шари архітектури OpenLedger - identity, execution, attribution, settlement - масштабуються нерівномірно. ERC-8004 і x402 масштабуються природно як відкриті стандарти. PoA масштабуються умовно, через наближення для великих моделей. А виконавчий шар і інференс - саме там 5 TPS і кількість моделей на GPU стають вузькими місцями. OpenLoRA закриває одне з цих вузьких місць, якщо її заявки відповідають реальності. Якщо ні - архітектура працює в потужність демо-системи, не платформи.
Скажи, як ти зважуєш такі ставки в крипті, де технічна заявка ще не доведена незалежно? Ти радше довіряєш проектному анонсу, поки не з'явиться спростування, чи тримаєш скепсис, поки не побачиш сторонній бенчмарк - і дієш лише за фактом доказу?
