Vấn đề lớn nhất của builder trong AI ngày nay không phải là việc truy cập mô hình. Đó là sự tin cậy của dữ liệu.
Hầu hết các builder đã có thể truy cập vào các mô hình mạnh mẽ thông qua APIs. Thử thách khó khăn hơn bắt đầu khi họ cần dữ liệu đáng tin cậy để cải thiện các mô hình đó, tinh chỉnh các trường hợp sử dụng cụ thể, hoặc xây dựng các agent chuyên biệt. Dữ liệu đến từ nhiều nguồn khác nhau, chất lượng thay đổi đáng kể, quyền sở hữu thường không rõ ràng, và các nhà đóng góp hiếm khi có lý do trực tiếp để tiếp tục cung cấp thông tin hữu ích theo thời gian.
Điều này tạo ra một tình huống lạ lùng. Các builder muốn có thông tin tốt hơn, nhưng quy trình để sản xuất thông tin đó lại bị phân mảnh. Các nhà cung cấp dữ liệu, builder mô hình, và các nhà phát triển ứng dụng thường hoạt động ở các lớp tách biệt với những động lực khác nhau. Kết quả là có sự ma sát, chu kỳ lặp lại chậm hơn, và không chắc chắn về việc liệu dữ liệu cơ bản có vẫn hữu ích khi các dự án mở rộng hay không.
Điều mà nhiều người hiểu sai về OpenLedger là họ xem nó chủ yếu như một dự án AI khác cạnh tranh để thu hút sự chú ý trong một thị trường đã quá đông đúc.
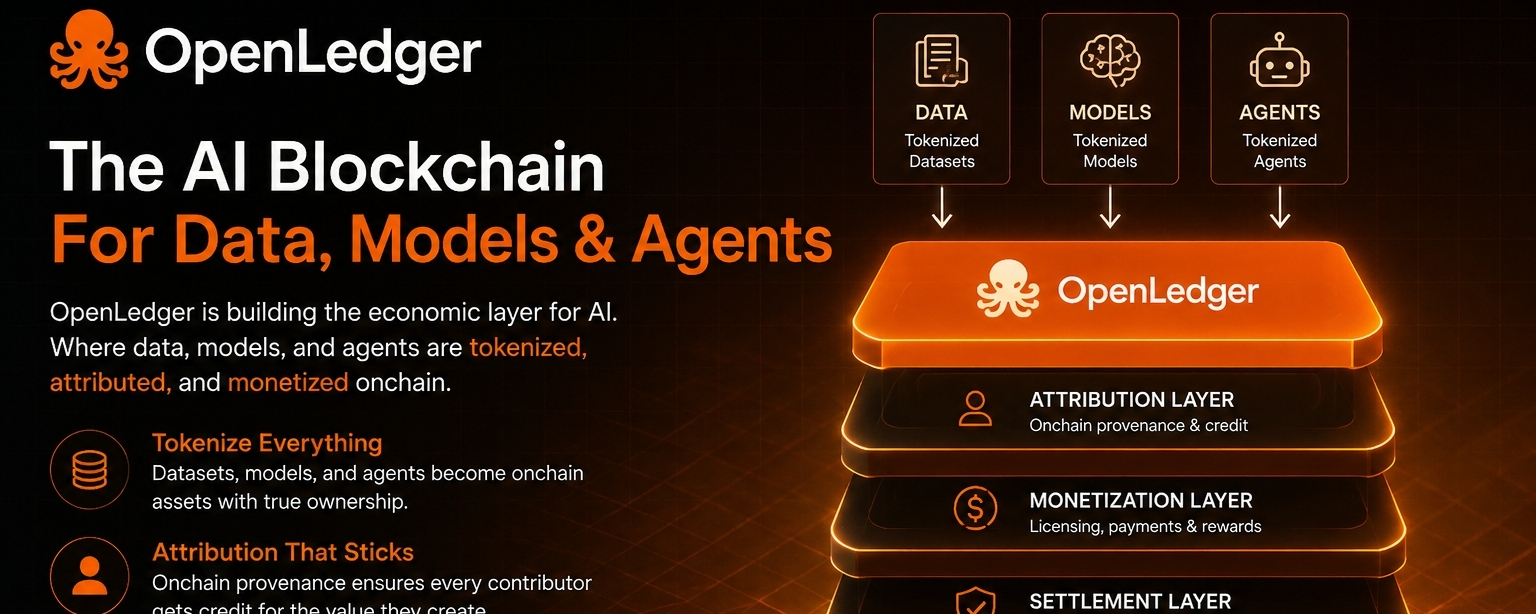
Khía cạnh thú vị hơn là OpenLedger dường như tập trung vào lớp phối hợp kinh tế đứng sau sự phát triển AI. Dự án không chỉ đơn giản hỏi làm thế nào để tạo ra các mô hình. Nó đang hỏi làm thế nào mà các người đóng góp, bộ dữ liệu, mô hình và ứng dụng có thể tương tác theo cách mà việc tạo ra giá trị có thể đo lường và sự tham gia vẫn bền vững.
Sự phân biệt đó rất quan trọng.
Quy trình truyền thống thường xem dữ liệu như một nguồn tài nguyên chỉ dùng một lần. Dữ liệu được thu thập, xử lý và hấp thụ vào các mô hình. Khi điều đó xảy ra, mối liên hệ giữa người đóng góp ban đầu và việc tạo ra giá trị trong tương lai trở nên khó theo dõi. Những người xây dựng có được trí tuệ, nhưng cấu trúc phân bổ và khuyến khích trở nên ngày càng mờ mịt.
OpenLedger cố gắng giảm ma sát này bằng cách giới thiệu cơ sở hạ tầng nơi dữ liệu, mô hình và các tác nhân AI có thể tồn tại trong một khung được thiết kế cho việc phân bổ và kiếm tiền. Thay vì xem dữ liệu như một đầu vào có thể vứt bỏ, hệ thống coi nó như một tài sản có thể tiếp tục tạo ra giá trị trong suốt vòng đời của các ứng dụng AI.
Phần nổi bật với tôi là điều này chuyển cuộc trò chuyện từ hiệu suất mô hình đơn thuần sang trách nhiệm đóng góp.
Những người xây dựng thường nói về các mô hình tốt hơn. Họ dành ít thời gian để thảo luận về cách mà việc sản xuất dữ liệu bền vững thực sự diễn ra. Tuy nhiên, nhiều sản phẩm AI cuối cùng bị hạn chế bởi chất lượng dữ liệu hơn là khả năng của mô hình thô. Nếu những người đóng góp không có lý do để tiếp tục tham gia, chất lượng dữ liệu sẽ xấu đi. Khi chất lượng dữ liệu xấu đi, hiệu suất ứng dụng cuối cùng cũng sẽ theo.
Đây là điểm áp lực của việc áp dụng.
Để OpenLedger có ý nghĩa, những người xây dựng phải quyết định rằng việc phân bổ và cấu trúc khuyến khích đủ quan trọng để tích hợp vào quy trình làm việc của họ. Công nghệ tự nó chỉ là một phần của phương trình. Thách thức lớn hơn là hành vi. Các nhà phát triển đã quen với các dòng chảy hiện có, bộ dữ liệu tập trung và công cụ AI đã được thiết lập. Bất kỳ cơ sở hạ tầng mới nào phải giảm đủ ma sát để biện minh cho việc thay đổi những thói quen đó.
Nếu sự chuyển mình đó xảy ra, những người xây dựng sẽ có được điều gì đó giá trị: một con đường rõ ràng hơn giữa đóng góp và phần thưởng. Các nhà cung cấp dữ liệu có lý do mạnh mẽ hơn để tham gia. Những người tạo ra mô hình có quyền truy cập vào các nguồn thông tin có thể phong phú hơn. Các nhà phát triển ứng dụng hoạt động trên một hệ thống mà dòng giá trị có thể được theo dõi một cách minh bạch hơn.
Hãy xem xét một kịch bản thực tế.
Một đội xây dựng một trợ lý chăm sóc sức khỏe chuyên biệt cần kiến thức theo miền mà các mô hình đa mục đích không thể cung cấp một cách đáng tin cậy. Họ yêu cầu sự đóng góp liên tục từ các chuyên gia, nhà nghiên cứu và các nguồn dữ liệu ngách. Dưới các cấu trúc truyền thống, việc duy trì sự tham gia của người đóng góp trở nên khó khăn vì mối quan hệ giữa đóng góp và giá trị tương lai là yếu.
Một khung như OpenLedger cố gắng tạo ra một cấu trúc mà trong đó các đóng góp vẫn được nhìn thấy và kết nối kinh tế với trí tuệ đang được sản xuất. Thay vì liên tục xây dựng lại sự tham gia từ đầu, những người xây dựng có thể vận hành trong một hệ thống được thiết kế để khuyến khích đóng góp lâu dài.
Điều đó không tự động giải quyết vấn đề.
Một rủi ro chân thành vẫn còn đó.
Cơ sở hạ tầng có thể tạo ra các cơ chế phân bổ, nhưng không thể ép buộc sự tham gia có ý nghĩa. Nếu các nhà đóng góp chất lượng cao, những người xây dựng mô hình, và các nhà phát triển ứng dụng không sử dụng tích cực mạng lưới, thì thiết kế kinh tế trở nên kém liên quan. Các hệ thống phối hợp trở nên mạnh mẽ chỉ khi đủ số lượng người tham gia đồng ý phối hợp thông qua chúng.
Đây là lý do tại sao việc áp dụng mạng lưới quan trọng hơn chỉ kiến trúc kỹ thuật.
Luận điểm mạnh mẽ nhất xung quanh OpenLedger không phải là nó giúp tạo ra AI. Nhiều dự án đã theo đuổi mục tiêu đó. Luận điểm mạnh mẽ hơn là nó cố gắng giảm một trong những bất cập cấu trúc dai dẳng nhất của AI: sự ngắt kết nối giữa những người đóng góp trí tuệ và những người thu lợi từ giá trị đó. Nếu những người xây dựng ngày càng coi việc phân bổ dữ liệu và cấu trúc khuyến khích là cơ sở hạ tầng cần thiết thay vì các tính năng tùy chọn, thì cách tiếp cận của OpenLedger sẽ dễ hiểu hơn nhiều.
\u003cm-54/\u003e\u003ct-55/\u003e\u003cc-56/\u003e
