Thị trường hôm nay cảm giác yên tĩnh hơn bình thường. Không chết — chỉ là cái năng lượng kỳ lạ ở giữa, nơi mà không có cái nào đang pump nhưng cũng không có cái nào thực sự bleeding cả. Mình đã chỉ... lướt qua. Nhìn những thứ mình đã đánh dấu nhưng chưa bao giờ thực sự đọc.
Đó là cách mình rơi vào OpenLedger.
Mình không tìm kiếm nó một cách cụ thể. Mình đang nghĩ về toàn bộ vấn đề dữ liệu AI — bạn biết đấy, cái cảm giác khó chịu mơ hồ rằng mọi mô hình bạn sử dụng đã trở nên thông minh hơn nhờ tiêu thụ những thứ mà mọi người tạo ra, và không ai nhận được gì từ đó. Các nhà văn, lập trình viên, nhà nghiên cứu. Chỉ là... những người đóng góp im lặng cho một thứ mà họ sẽ không bao giờ sở hữu một phần nào.
Vì vậy, tôi bắt đầu đọc về $OPEN , và ban đầu tôi cảm thấy như một lời hứa "chúng tôi đang sửa chữa AI" khác. Tôi gần như đã đóng tab.
Nhưng sau đó một điều nhỏ đã thu hút sự chú ý của tôi và tôi không thể bỏ qua.
OpenLedger không chỉ cố gắng trả tiền cho mọi người vì dữ liệu. Nó đang cố gắng làm cho việc đóng góp dữ liệu có thể truy xuất được — như, vĩnh viễn, có thể xác minh được — đến những mô hình thực sự đã sử dụng nó.
Và tôi đã phải ngồi với điều đó một lúc. Bởi vì đó là hai điều rất khác nhau.
Hầu hết mọi người, khi họ nghe "được trả tiền cho dữ liệu của bạn," hình dung điều gì đó như một cuộc khảo sát. Bạn gửi cái gì đó, ai đó trả cho bạn một khoản phí cố định, xong. Giao dịch. Không liên quan đến kết quả.
Điều mà OpenLedger dường như đang nhắm tới là khác biệt: nếu một mô hình được đào tạo từ tập dữ liệu của bạn trở nên thông minh hơn, được sử dụng nhiều hơn, tạo ra giá trị — bạn nên có quyền yêu cầu điều đó. Không chỉ là khoản phí nộp một lần. Đóng góp đó sẽ được ghi lại trên chuỗi, gắn liền với hiệu suất của mô hình, có thể truy xuất theo thời gian.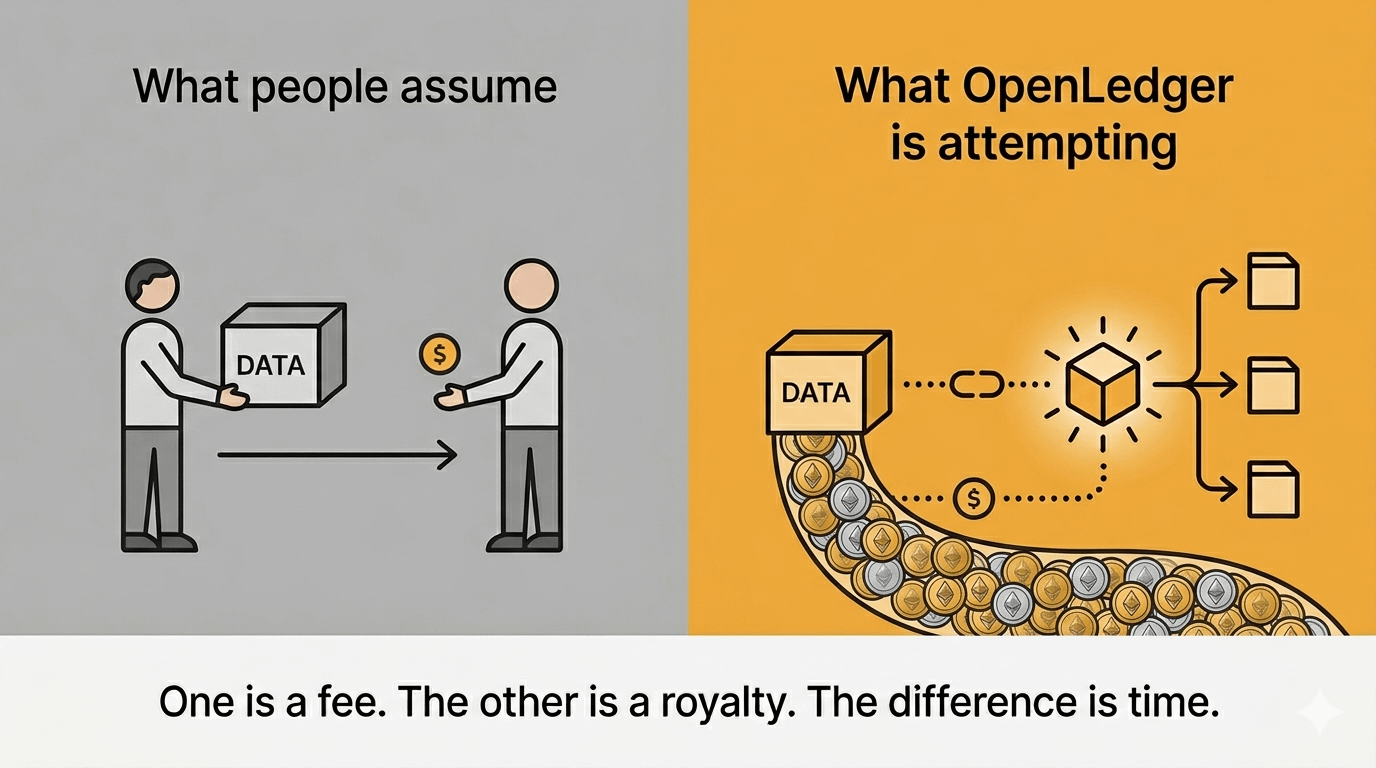
Tôi nghĩ rằng đây chỉ là một phiên bản đẹp hơn của cùng một thứ. Nhưng thực sự thì không phải.
Nó gần giống như cách mà bản quyền hoạt động trong âm nhạc. Bạn viết một bài hát một lần, nó được sử dụng hàng ngàn lần, bạn tiếp tục kiếm tiền. Ngoại trừ "bài hát" ở đây là một tập dữ liệu. Và "số lần nó được sử dụng" là mỗi lần suy diễn chạy xuống dòng.
Nhận thức đó khiến tôi cảm thấy hơi không thoải mái. Bởi vì nếu điều đó thực sự hoạt động — nếu đóng góp thực sự có thể truy xuất ở mức độ đó — thì toàn bộ cách chúng ta nghĩ về thị trường dữ liệu AI trông có phần nguyên thủy ngay bây giờ.
Nhưng đây là phần làm tôi bận tâm.
Khả năng truy xuất nghe có vẻ sạch sẽ trong lý thuyết. Trong thực tế, các mô hình không sử dụng dữ liệu theo cách một-một. Chúng kết hợp, biến đổi, trộn mười ngàn người đóng góp thành một cập nhật trọng số mà không giống bất kỳ nguồn nào. Vậy làm thế nào để bạn thực sự truy xuất đóng góp của mình qua điều đó? Ai quyết định dữ liệu của bạn được hưởng bao nhiêu tín dụng so với 40,000 cái khác đã được đào tạo cùng nó?
Tôi không hoàn toàn bị thuyết phục rằng điều này sẽ đứng vững dưới áp lực. Vấn đề phân bổ trong học máy thực sự khó — không phải "chúng ta cần công cụ tốt hơn" khó, mà giống như "điều này có thể không thể giải quyết về mặt triết lý" khó. Và nếu mô hình phân bổ thậm chí chỉ hơi có thể bị lợi dụng, toàn bộ điều này bắt đầu trông ít giống hệ thống bản quyền và nhiều hơn như một hệ thống điểm mà cảm thấy công bằng nhưng không phải vậy.
Đó không phải là tôi nói rằng nó thất bại. Tôi thực sự vẫn chưa biết. Nhưng tôi nghĩ những người nhảy vào $OPEN mà không đặt câu hỏi đó đang bỏ qua câu hỏi quan trọng nhất.
Điều làm cho điều này thú vị bất kể thế nào — và tôi cứ quay lại điều này — là ai sẽ bị ảnh hưởng nếu nó hoạt động.
Thực ra không phải là các nhà giao dịch bán lẻ. Đó là những người thực sự sản xuất dữ liệu có cấu trúc, chất lượng cao. Các nhà nghiên cứu. Các chuyên gia trong lĩnh vực ngách. Những người trong các lĩnh vực mà dữ liệu đào tạo tốt thực sự khan hiếm và thực sự có giá trị. Nếu những người đó bắt đầu nhận được bồi thường tương xứng với việc dữ liệu của họ cải thiện đầu ra mô hình... điều đó sẽ thay đổi cấu trúc khuyến khích xung quanh phát triển AI theo cách mà rất khó để suy nghĩ đầy đủ ngay bây giờ.
Nó cũng lặng lẽ tái định vị $OPEN từ "token AI crypto" thành cái gì đó thực sự có nhu cầu lặp lại gắn liền với việc sử dụng mô hình thực tế. Không phải nhu cầu hô hào. Nhu cầu tiện ích. Loại nhu cầu không biến mất khi câu chuyện xoay chuyển.
Tôi nghĩ đó chỉ là một chợ dữ liệu khác. Nó thực sự đang cố gắng trở thành cái gì đó gần gũi hơn với một lớp phân bổ bên dưới AI.
Liệu điều đó có thể đạt được hay không là một câu hỏi khác.
Dù sao đi nữa. Biểu đồ vẫn trông không thuyết phục với tôi. Tôi có lẽ sẽ chỉ tiếp tục theo dõi cái này từ xa trong thời gian tới — xem cách mà phía người đóng góp dữ liệu thực sự phát triển trước khi hình thành một quan điểm mạnh mẽ hơn.
Tôi vẫn đang nghĩ về vấn đề bản quyền đó. Phần đó vẫn chưa rời khỏi tôi.