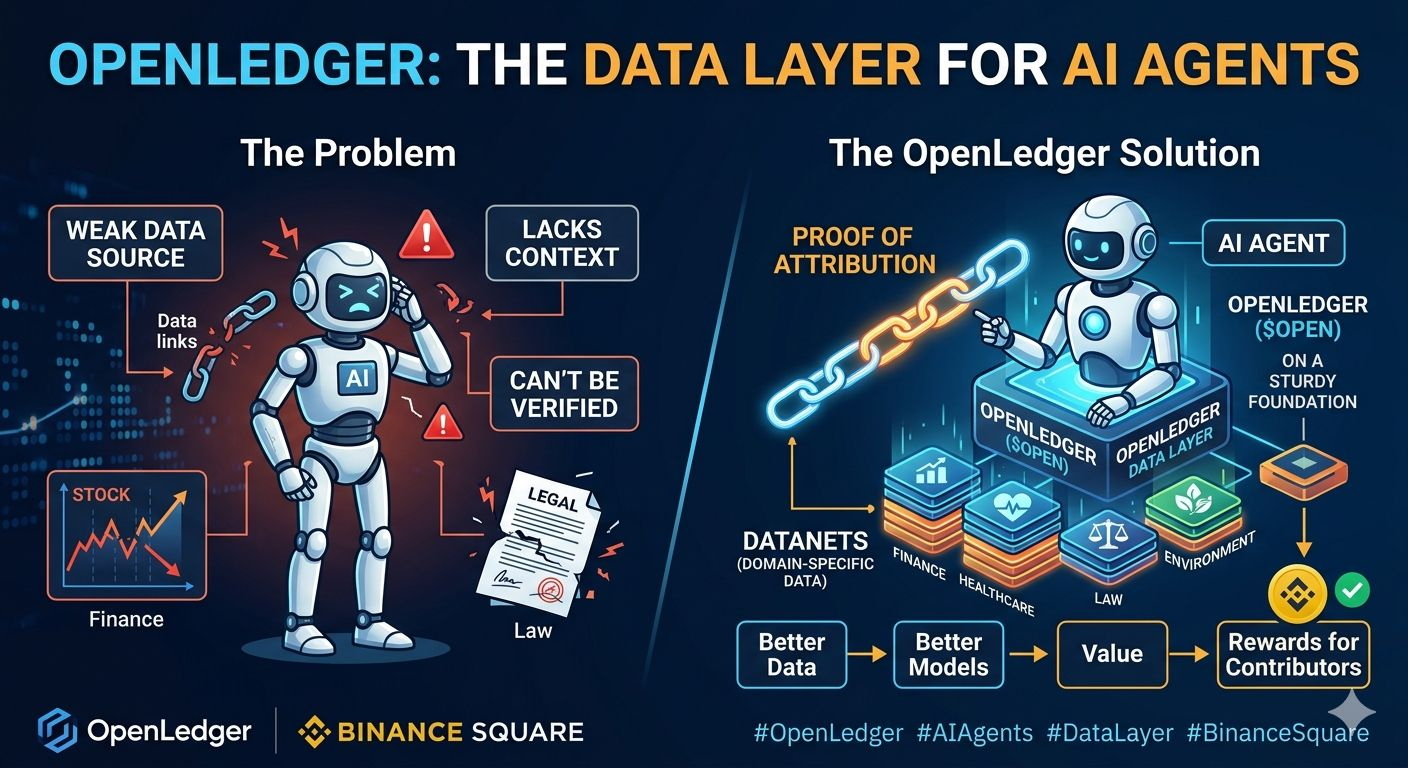
Most people focus on what AI Agents can *do*—calling APIs, trading, and executing tasks. But the real bottleneck isn’t action; **it’s the data.**
A brilliant model with weak, unverified, or outdated data will make flawed decisions.
* 📉 **Finance:** Outdated market inputs create bad signals.
* 🏥 **Healthcare:** Missing data provenance poses severe risks.
* ⚖️ **Legal:** Unverified context leads to wrong conclusions.
For AI Agents to handle serious, high-value use cases, they need a reliable, verifiable data layer. That is exactly where **OpenLedger ($OPEN )** comes into play.
### 🗂️ Datanets: Context Over Chaos
AI Agents don’t operate in a vacuum—they require strict context. OpenLedger solves this through **Datanets**, which organize data by specialized domains (Finance, Law, Healthcare, Gaming) rather than pooling it together.
* Prevents generic, unverified noise from bleeding into specialized tasks.
* Attaches clear **identity, jurisdiction, and timing** to datasets.
* Ensures agents build on a structured, verifiable foundation instead of a fast but unreliable automation loop.
### 🔍 Proof of Attribution: Ending the "Black Box"
Traditional AI outputs are a dead end; you see the answer but can't trace the source. If an agent fails, debugging is impossible. If it succeeds, data contributors aren't recognized.
OpenLedger’s **Proof of Attribution (PoA)** changes the game:
* ⛓️ **Traceability:** It mathematically links an agent's output back to the specific data that trained or fine-tuned the model.
* 🤝 **Trust:** Enables builders and users to verify *why* an agent made a decision before risking significant capital or data.
### 🔄 The Incentive Loop for the Agent Economy
High-quality data doesn't appear out of thin air—it requires motivation. By utilizing Proof of Attribution, OpenLedger opens the door to programmatically reward data contributors when their data helps generate value.
💸 **The Flywheel:** Better Data ➡️ Better Models ➡️ Superior Agent Decisions ➡️ Higher Value Inferences ➡️ Increased Rewards for Contributors.
### ⚖️ The Reality Check
The thesis is incredibly strong, but OpenLedger still faces practical hurdles to scale:
* Can Datanets consistently scale while keeping data quality high?
* Will Proof of Attribution remain precise as agent reasoning loops become more complex?
* Will costs stay sustainable as inference demands spike?
🔮 The Bottom Line
As the agent economy moves toward full autonomy, the need for responsible, interpretable data becomes non-negotiable. **OpenLedger ($OPEN)** might not be the front-end layer users see, but it has the architecture (Datanets + Proof of Attribution + ModelFactory) to become the ultimate trusted backend for AI Agents.