
OpenLedger properly the first time I looked at it. The short description made it sound simple: a blockchain project built around OPEN, with a focus on monetizing data, models, and agents. But that kind of description does not really explain the project. It makes everything sound cleaner than it actually is. Data goes in, models use it, contributors get paid, and the network grows. On the surface, that sounds easy to understand, but once I spent more time reading through the project, the idea became more complicated and more interesting.
What stood out to me is that OpenLedger is really trying to deal with attribution. In most systems today, data is used in the background. It may come from users, communities, researchers, developers, domain experts, public sources, or private datasets, but once it becomes part of a model pipeline, the original contributor usually disappears. Their knowledge may improve the final product, but they are rarely visible in the value chain.
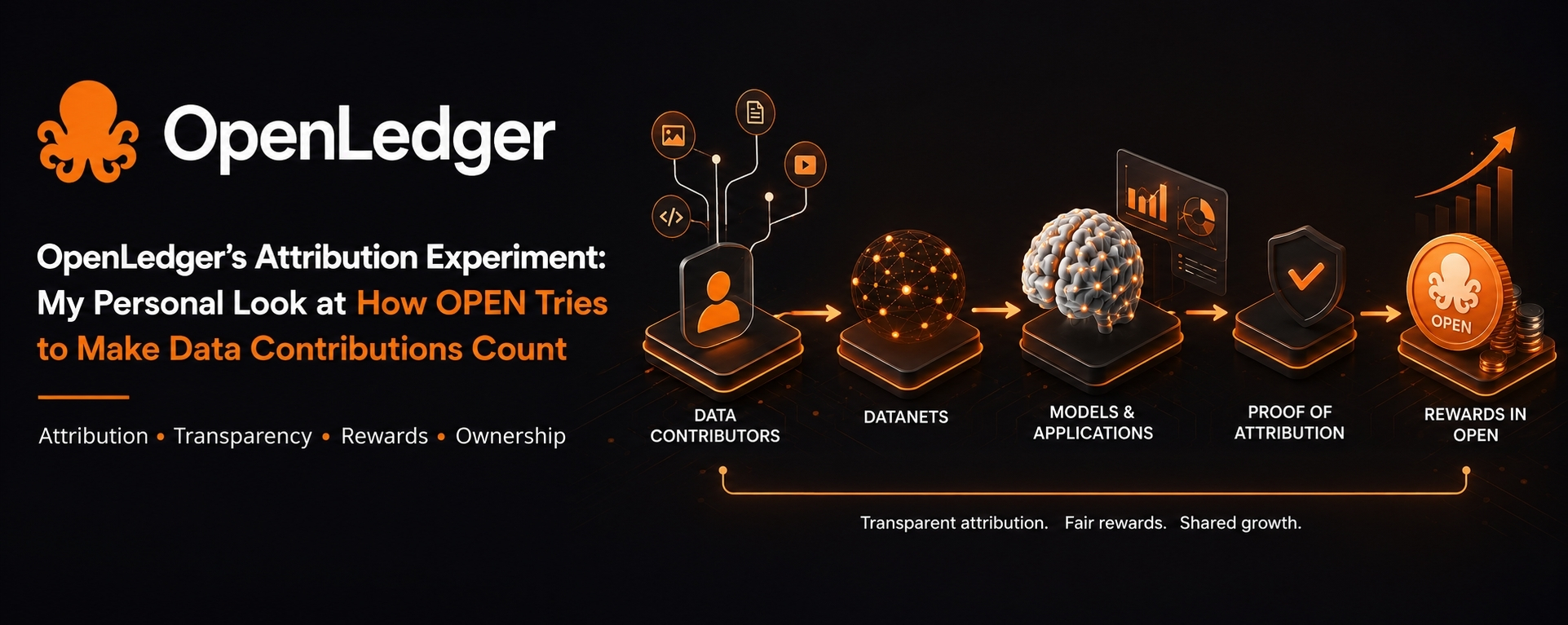
OpenLedger is trying to change that. The project wants to create a structure where data contributions can be tracked, measured, and rewarded when they actually help produce useful outputs. That is the main idea I kept coming back to while researching it. It is not just about putting models on a blockchain or adding a token to a product. The more serious question is whether a network can prove which data mattered and then distribute value back to the people or groups that contributed it.
That is where Proof of Attribution becomes important. From my understanding, this is OpenLedger’s attempt to connect data contributions with model behavior and usage. If a dataset helps improve a model, and that model is later used by applications or users, the system should be able to identify the contribution and reward it. The blockchain is used as a public record and settlement layer around this process.
I found this idea stronger than the usual broad infrastructure pitch because it focuses on a specific problem. OpenLedger is not trying to claim that every part of model training should happen on-chain. That would not be practical. Instead, the chain appears to be used for coordination, records, payments, registrations, and rewards. The heavy computation can happen elsewhere, while the chain keeps track of ownership, usage, and attribution.
That makes sense to me, but it also creates a very hard challenge. Attribution sounds fair in theory, but it is not easy to do well. A model does not usually produce a clear receipt showing which exact data points shaped a specific output. Influence can be spread across many examples. Sometimes a piece of data helps directly. Sometimes it helps only in a broad or indirect way. Sometimes an output resembles a source because the model memorized it, and sometimes the connection is much harder to prove.
This is where I became both interested and cautious. OpenLedger’s entire economic loop depends on attribution being credible. If the system rewards the wrong contributors, trust breaks down. If it rewards duplicated or low-quality data, people may start gaming the system. If useful contributors are underpaid because their influence is difficult to measure, they may not stay. If attribution becomes too expensive or complicated, developers may avoid it.
So, for me, the important question is not simply whether OpenLedger has an attribution system. The important question is whether that system can be trusted by contributors, used by developers, and understood well enough by the wider community.
The Datanets are another part of the project that made me pay attention. A Datanet is basically a focused data network around a specific subject or use case. Instead of treating all data as one large pile, OpenLedger seems to encourage specialized datasets. This makes sense because useful data is not always general. A healthcare model needs different information from a smart contract security model. A mapping-related model needs different data from a wallet assistant. A financial or trading-focused system would need different signals again.
This part of the project feels practical because specialized data is genuinely valuable. More data is not always better. Better data, with context and quality, can matter much more. If OpenLedger can help communities build strong Datanets around useful domains, then it has something meaningful to work with.
But this is also where I see one of the biggest risks. A Datanet only matters if the data inside it is actually good. If incentives attract low-effort uploads, copied material, outdated information, or misleading contributions, the quality of the network can decline quickly. Any system that pays people for contribution has to think carefully about spam, duplication, and manipulation.
I kept asking myself who verifies the data, who filters the weak contributions, and how quality is measured. In some domains, this is especially important. Bad data in a simple entertainment use case may be annoying. Bad data in healthcare, security, finance, or legal contexts can be dangerous. OpenLedger’s long-term success will depend not only on attracting contributors, but on attracting the right contributors and keeping the data layer useful.
Another thing I noticed is that OpenLedger is not only focused on collecting data. It also wants to give builders tools to turn that data into usable models. Model Factory is part of that direction. It is meant to help people train, fine-tune, register, and deploy models using the OpenLedger environment. That matters because most developers do not want to manually manage every step of provenance, deployment, payment, and attribution.
OpenLoRA also stood out to me because it feels connected to a real technical need. LoRA adapters are a practical way to customize models without retraining everything from the beginning. Instead of creating a full separate model for every use case, builders can use smaller adapters that adjust behavior for specific tasks. This can reduce cost and make specialized deployment easier.
This part made OpenLedger feel more grounded to me. The project is not just saying contributors should be paid. It is also trying to create a path where data becomes models, models become products, products create usage, and usage creates rewards. That loop is what OpenLedger needs to prove.
Still, good architecture does not automatically mean good adoption. Developers are usually practical. They will not use OpenLedger only because the idea sounds fair. They will use it if the tools save time, reduce cost, improve results, or give access to data and attribution features they cannot easily get elsewhere. If the documentation is weak, if deployment is difficult, if fees are confusing, or if the system adds too much friction, builders may not stay.
The blockchain side is useful, but I do not see it as the whole story. OpenLedger runs as an Ethereum Layer 2 using the OP Stack, which seems like a practical choice. It gives the project cheaper and faster transactions than Ethereum mainnet while staying connected to the broader Ethereum environment. The chain can be used for model registration, dataset records, inference payments, attribution records, and reward distribution.
That said, launching a chain is not enough anymore. Many projects can create an L2. The real question is whether anything important happens on it. For OpenLedger, the chain becomes valuable only if contributors, developers, applications, and users treat it as the place where model-related value is recorded and settled.
So I see the chain as necessary infrastructure, not the main proof. The main proof will be actual usage: active Datanets, deployed models, paid inference, real contributor rewards, and independent applications that depend on OpenLedger because it solves a problem.
OPEN, the native token, has a clear role inside the system. It is used for gas, governance, model registration, deployment, inference payments, and contributor rewards. The total supply is capped at 1 billion tokens, and a large share is allocated to community and ecosystem growth. On paper, this fits the project’s design because OPEN is supposed to move through the network as contributors, builders, and users interact.
But I try to be careful when looking at token utility. A token can have many use cases listed in documentation and still struggle if the underlying network does not create real demand. For OPEN, the important question is whether usage creates demand naturally. If users pay for model access, builders deploy useful models, and contributors earn because their data is actually helping, then the token has a stronger role. If activity depends mostly on rewards and campaigns, then the economic picture becomes weaker.
I also noticed the project’s disclosure around a buyback plan connected to liquidity allocation and enterprise data contributor rewards. I do not see that as automatically negative, but it reminded me that token operations can become complicated. When contributor incentives, liquidity, ecosystem funding, and market perception overlap, transparency becomes very important. For a project like OpenLedger, trust in the token economy matters almost as much as trust in the attribution system.
The ecosystem signals are interesting, but I would not overstate them. OpenLedger has mentioned activity across areas like DeFi, healthcare, mapping, wallets, and other applications. Binance Research also referenced more than 50 ecosystem initiatives and several collaborations. The Trust Wallet-related work caught my attention because wallets are one of the few crypto products with broad user exposure. If wallet experiences become more intelligent and intent-based, users will need more transparency around recommendations and actions. That type of use case fits OpenLedger’s attribution idea better than vague examples.
Still, I try to separate signals from proof. Crypto has seen many partnerships that sounded important but did not lead to much real usage. What I would rather see over time is data that is harder to fake: how many Datanets are active, how many developers are deploying models, how much inference is happening, how much OPEN is being used for actual network activity, and whether contributors are receiving meaningful rewards from real usage.
The most promising thing about OpenLedger, in my view, is that it is focused on a real problem. Data contributors are often invisible, and specialized data can be extremely valuable. OpenLedger is trying to make that value traceable and rewardable. I also like that the project has an internal logic. Datanets collect specialized data. Model Factory helps turn that data into models. OpenLoRA helps with lighter customization and deployment. Proof of Attribution tries to measure contribution. OPEN handles payments, rewards, and network activity.
The pieces connect in a way that makes sense.
But the concerns are also real. Attribution has to be accurate enough to trust. Data quality has to be protected. Developers need tools that actually work. Users need reasons to pay for outputs. OPEN needs demand from real usage, not just incentive cycles. Enterprise adoption needs to be proven over time, not only mentioned in announcements.
After exploring OpenLedger, I see it as a project with a strong idea and a difficult path. The idea of rewarding data contributors based on actual model impact is worth taking seriously. It addresses a real imbalance in how data and knowledge are used. But the project still has to show that this can work at scale, with real contributors, real products, real demand, and reliable attribution.
My perspective is cautiously interested. I do not see OpenLedger as something to blindly praise, and I would not treat this as investment advice. I see it as a project trying to solve a hard problem in a space where many projects prefer easier narratives. That makes it worth following, but the next stage has to be about evidence. The concept is clear enough. Now the important question is whether the network can prove that attribution, rewards, and actual usage can work together in practice.