
Liệu OpenLedger có thực sự biến dữ liệu thành “dòng tiền theo thời gian”?
Có phải chỉ mình mình đang nghĩ về điều này… hay bạn cũng từng để ý rồi? 🤔
Trong hầu hết hệ thống AI hiện tại, dữ liệu thường chỉ được xem như một dạng “đầu vào” thuần túy: đưa vào để huấn luyện, rồi gần như không còn được nhắc lại sau đó. Nhưng khi nhìn kỹ hơn vào cách các mô hình AI vận hành, mọi thứ không đơn giản như vậy, vì dữ liệu không hề tồn tại như những đơn vị tách biệt có thể đo đếm riêng lẻ.
Ý tưởng mà OpenLedger đang theo đuổi xuất phát từ chính điểm mơ hồ đó: làm sao để ghi nhận nguồn gốc dữ liệu và gắn giá trị kinh tế theo mức độ ảnh hưởng thực sự của nó trong suốt vòng đời của mô hình AI. Ban đầu, điều này nghe giống như một dạng mở rộng của việc mua bán dữ liệu thông thường, nhưng thực chất nó tham vọng hơn nhiều, vì nó cố biến dữ liệu thành một loại tài sản có khả năng tạo dòng giá trị theo thời gian thay vì chỉ là giao dịch một lần rồi kết thúc.
Để dễ hình dung hơn về quy mô của vấn đề, có thể nhìn vào thực tế huấn luyện AI hiện nay: các mô hình ngôn ngữ lớn thường được huấn luyện trên những tập dữ liệu ở quy mô rất lớn, như LLaMA 2 từng được huấn luyện trên khoảng 2 nghìn tỷ token, còn các mô hình lớn khác trong ngành có thể vượt mốc 1-5 nghìn tỷ token tùy kiến trúc và mục tiêu. Các dataset web crawl phổ biến như Common Crawl cũng chứa hàng trăm tỷ trang web thô, tương đương hàng trăm terabyte đến vài petabyte dữ liệu trước khi xử lý. Chi phí huấn luyện các mô hình này cũng cực lớn: các báo cáo công khai ước tính GPT-4 có thể tiêu tốn hơn 100 triệu USD chi phí compute, trong khi các mô hình lớn hiện đại thường cần hàng chục nghìn GPU-hours đến hàng triệu GPU-hours để hoàn thành training. Điều đáng nói là toàn bộ lượng dữ liệu và chi phí khổng lồ đó cuối cùng lại được “trộn” vào một mô hình duy nhất, khiến việc truy vết giá trị của từng phần dữ liệu gần như bất khả thi.
Vấn đề cốt lõi nằm ở chỗ: trong các mô hình AI hiện đại, dữ liệu bị trộn lẫn trong quá trình huấn luyện, nó bị biến đổi, hòa vào nhau và không còn giữ ranh giới rõ ràng. Vì vậy, khi một mô hình hoạt động tốt, rất khó để trả lời câu hỏi dữ liệu nào đã đóng góp bao nhiêu vào kết quả đó. Điều này giống như việc bạn nấu một nồi nước dùng lớn, và sau đó cố gắng chỉ ra chính xác từng hạt gia vị đã ảnh hưởng như thế nào đến hương vị cuối cùng - về mặt kỹ thuật, gần như không thể tách bạch.
Vậy nếu không thể tách riêng từng đóng góp, làm sao để xác định giá trị thật của dữ liệu?
Chính vì vậy, tham vọng của OpenLedger đòi hỏi hai lớp năng lực: một là khả năng truy vết dữ liệu trong toàn bộ vòng đời huấn luyện, và hai là khả năng phân phối lại giá trị dựa trên mức độ ảnh hưởng thực tế của dữ liệu đó. Nếu làm được, dữ liệu không còn là một input “vô danh” nữa mà trở thành một thực thể có lịch sử đóng góp rõ ràng, thậm chí có thể tiếp tục tạo ra phần thưởng nếu nó vẫn mang lại hiệu quả khi mô hình được triển khai trong thực tế.
Nhưng điểm khó nhất lại nằm ở chính bài toán đo lường. Khi dữ liệu đã bị hòa trộn trong quá trình huấn luyện, việc tách riêng ảnh hưởng của từng phần trở nên cực kỳ phức tạp và tốn kém về mặt tính toán. Ngay cả khi có những kỹ thuật ước lượng như loại bỏ từng phần dữ liệu để quan sát sự thay đổi của mô hình, kết quả vẫn chỉ mang tính tương đối. Điều này tạo ra một rủi ro rất lớn: hệ thống phân phối giá trị có thể vô tình ưu tiên những thứ dễ đo hơn, thay vì phản ánh đúng giá trị thực sự của dữ liệu.
Trong môi trường crypto, vấn đề này còn trở nên nhạy cảm hơn. Vì toàn bộ hệ thống vận hành dựa trên incentive, nếu cách đo lường sai lệch, người tham gia sẽ nhanh chóng tìm cách tối ưu hóa để được ghi nhận nhiều hơn thay vì tập trung vào chất lượng dữ liệu thực. Nói cách khác, dữ liệu có thể bị “thiết kế để được thưởng”, thay vì được tạo ra để cải thiện mô hình AI. Đây là một dạng lệch hệ thống rất phổ biến khi tài chính được gắn trực tiếp vào tín hiệu kỹ thuật.
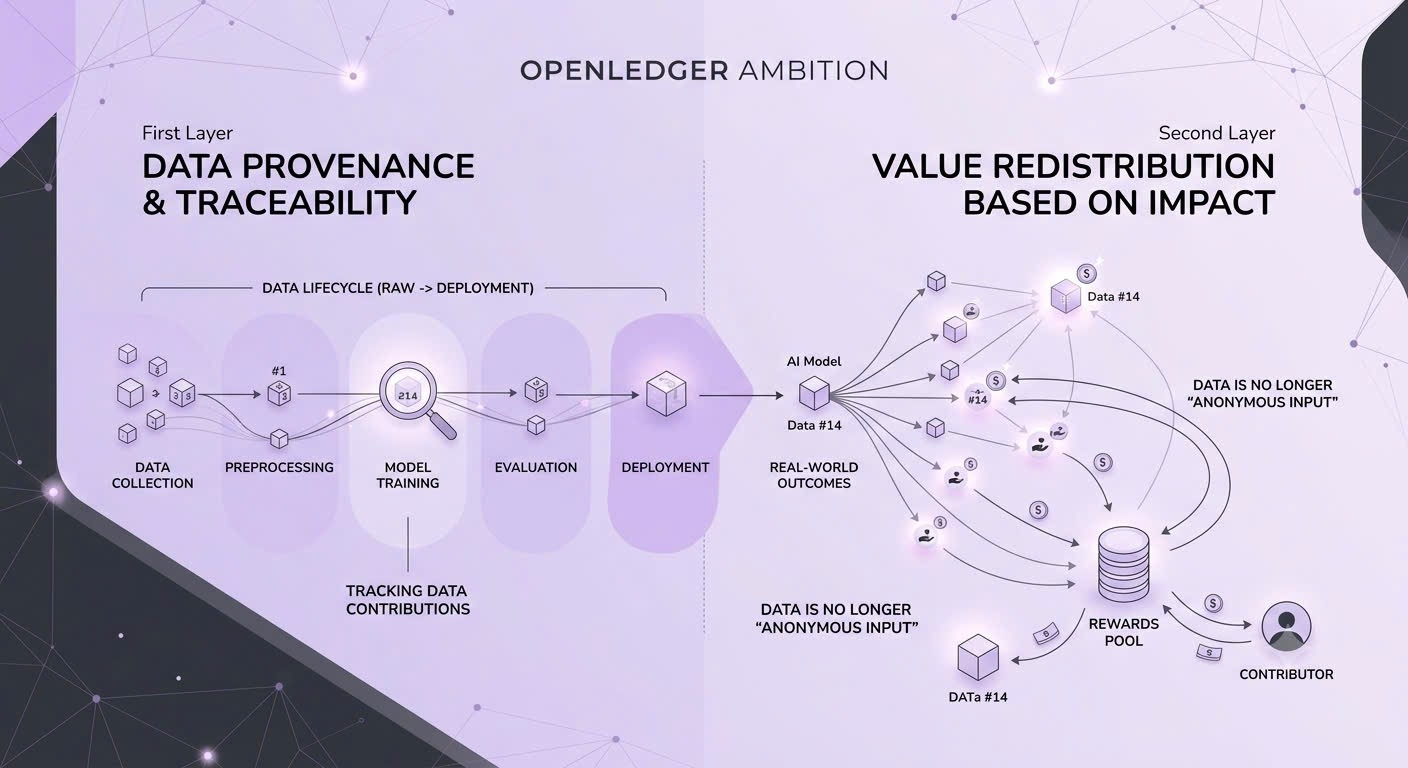
Nếu không giải quyết được bài toán này, hệ quả sẽ khá rõ ràng: việc phân phối giá trị trở nên méo mó, một số dữ liệu có thể được trả công quá mức trong khi những dữ liệu thật sự quan trọng lại không được ghi nhận đúng mức. Chi phí tính toán cũng sẽ tăng mạnh nếu cố gắng truy vết chính xác từng đóng góp, khiến hệ thống khó mở rộng quy mô.
Chính vì vậy, OpenLedger nhấn mạnh rất nhiều vào bài toán “đóng góp dữ liệu” này, vì nó không phải là một tính năng phụ mà là nền tảng quyết định toàn bộ mô hình có tồn tại được hay không. Mục tiêu của họ, xét đến cùng, là xây dựng một hệ thống nơi dữ liệu được ghi nhận nguồn gốc, được theo dõi trong quá trình sử dụng trong AI, và được phân phối lại giá trị dựa trên mức độ ảnh hưởng thực tế. Nếu thành công, dữ liệu sẽ không còn là tài sản bị định giá một lần, mà trở thành một dạng tài sản có khả năng tạo thu nhập theo thời gian.
Trong bức tranh thực tế hiện nay, phần lớn các hệ thống dữ liệu hoặc AI marketplace vẫn hoạt động theo mô hình trả tiền một lần, nghĩa là người đóng góp dữ liệu gần như không còn quyền lợi gì nếu dữ liệu đó tiếp tục tạo ra giá trị về sau. Một số dự án AI kết hợp blockchain chỉ dừng lại ở mức ghi nhận đơn giản, chưa thực sự giải quyết được bài toán đo lường ảnh hưởng. So với bức tranh đó, hướng đi của OpenLedger rõ ràng tham vọng hơn khi cố gắng định lượng “impact” thực sự thay vì chỉ ghi nhận sự tồn tại của dữ liệu.
Tuy nhiên, cũng cần nhìn nhận rằng đây là một bài toán cực khó. Việc gắn incentive với dữ liệu luôn tạo ra nguy cơ hệ thống bị tối ưu hóa sai hướng, và ranh giới giữa đo lường đúng và đo lường sai là rất mong manh. Chỉ cần một số giả định kỹ thuật không chính xác, toàn bộ cơ chế phân phối có thể bị lệch đi đáng kể.
Dù vậy, nếu nhìn ở góc độ dài hạn, đây vẫn là một trong những hướng đi đáng chú ý trong nền kinh tế AI. Vì hiện tại, dữ liệu đang bị xem như một nguồn tài nguyên tiêu hao, trong khi thực tế nó có thể là nền tảng tạo giá trị liên tục nếu có cơ chế ghi nhận đúng cách. Và chính khoảng trống đó là lý do những mô hình như OpenLedger xuất hiện.
Có thể nó sẽ thành công, cũng có thể nó sẽ gặp giới hạn khi triển khai ở quy mô lớn. Nhưng ít nhất, nó đang đặt lại một câu hỏi quan trọng mà phần lớn hệ thống hiện tại chưa trả lời được: làm thế nào để định giá đúng giá trị thật sự của dữ liệu trong AI.