
Đêm khuya rồi, lướt qua một câu chuyện nữa về cách mà một vài ông lớn công nghệ xây dựng những mô hình trị giá hàng nghìn tỷ trên lưng những người gán nhãn dữ liệu bị trả lương thấp ở Kenya và Philippines, những người phải đối mặt với nội dung khủng khiếp chỉ để nhận vài đồng xu trong khi các công ty thu lợi. Tôi luôn nghĩ rằng AI mã nguồn mở có nghĩa là công bằng hơn, nhưng càng đào sâu, tôi càng cảm thấy nó giống như việc khai thác cũ với tiếp thị tốt hơn. Sau đó, tôi đã dành vài tuần trong cộng đồng OpenLedger và đọc tài liệu trắng của họ từ đầu đến cuối. Lần đầu tiên, tôi thấy một con đường kỹ thuật thực sự cố gắng khép kín vòng tròn đó. Không hoàn hảo, nhưng chân thành. Đây là điều khiến tôi suy nghĩ. openledgerfoundation.com
Sự Thật Đau Đớn Về Dữ Liệu Trong AI
Chúng ta thường nói rất nhiều về việc căn chỉnh AI, nhưng hiếm khi nói về những con người làm cho sự căn chỉnh đó trở nên khả thi. Hiện tại, các công nhân dữ liệu—đặc biệt là ở các nền kinh tế đang phát triển—đang làm công việc vô hình để huấn luyện các bộ lọc, gán nhãn các bộ dữ liệu và dọn dẹp những hỗn độn để chatbot của chúng ta không phát ngôn những điều vô nghĩa hoặc tệ hơn. Các báo cáo vẫn tiếp tục xuất hiện: mọi người kiếm được dưới 2 đô la một giờ, đối mặt với chấn thương hình ảnh, không có tín dụng, không có quyền sở hữu, và không có cổ phần liên tục trong giá trị họ tạo ra. Các nền tảng tập trung coi đầu vào của họ như nguyên liệu thô, sau đó khóa các mô hình kết quả phía sau những cánh cửa đóng kín. Điều này không chỉ không công bằng; nó không bền vững. Nó nuôi dưỡng sự oán giận và để lại hầu hết thế giới ở bên ngoài nhìn vào.
Chứng nhận của OpenLedger (PoA) là phần khiến tôi dừng lại. Nó ghi lại một cách mật mã mọi đóng góp, tải lên dữ liệu, cải tiến, đánh giá trong suốt vòng đời và gắn liền với tác động có thể đo lường được. Khi một mô hình được huấn luyện trên bộ dữ liệu của bạn được sử dụng, bạn sẽ kiếm được $OPEN theo tỷ lệ. Không có người trung gian quyết định điều gì là có giá trị. Toán học và các hàm băm thực hiện công việc. Tôi đã hoài nghi lúc đầu, tính xác thực của blockchain nghe có vẻ tuyệt vời trên giấy, nhưng khi thấy cách họ liên kết các đóng góp đã được mã hóa với các nhật ký sử dụng đã thay đổi suy nghĩ của tôi. Đây không phải là từ thiện; đó là một yếu tố kinh tế biến lao động dữ liệu thụ động thành quyền sở hữu liên tục.
Tại Sao Tôi Bắt Đầu Chú Ý
Tôi đã theo dõi nhiều dự án "AI + crypto". Hầu hết cảm thấy như họ chỉ gắn một token vào các công cụ hiện có. OpenLedger có cảm giác khác vì họ bắt đầu từ chính quy trình AI. Tôi đã dành thời gian trong Discord của họ, đặt câu hỏi và nhận ra đội ngũ thực sự suy nghĩ về các động lực như một nhà kinh tế giỏi. Họ không hứa hẹn để thay thế những gã khổng lồ như GPT—họ đang xây dựng lớp mà các mô hình chuyên biệt phát triển cùng với chúng. Sự chuyển mình đó đã khiến tôi hiểu ra.
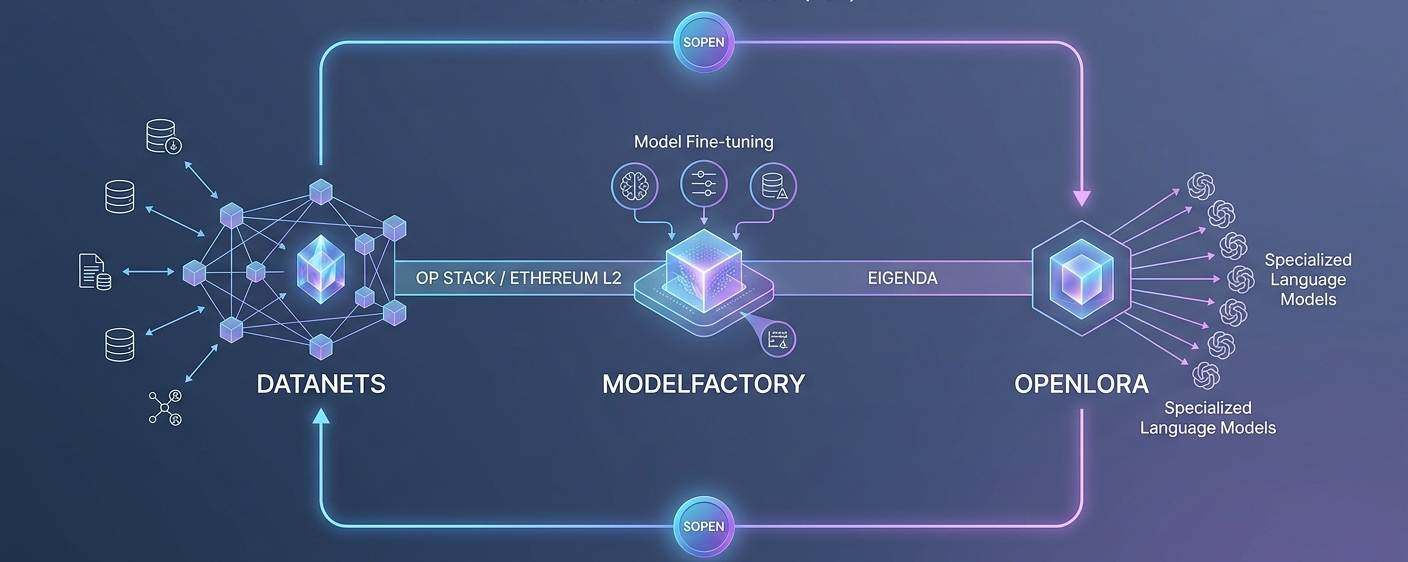
🧩 Cách Công Nghệ Thực Sự Hoạt Động (Giữ Đơn Giản)
OpenLedger hoạt động như một L2 trên Ethereum trong OP Stack với EigenDA để đảm bảo dữ liệu có sẵn. Lựa chọn thông minh: bạn nhận được bảo mật Ethereum và khả năng tương thích EVM mà không phải trả giá gas cao sẽ giết chết các tương tác AI thường xuyên như bước huấn luyện hoặc gọi suy luận. Phí thấp và tốc độ cao quan trọng khi bạn liên tục chuyển dữ liệu và mô hình.
• Datanets là mạng lưới cộng tác dữ liệu thuộc sở hữu cộng đồng. Bất kỳ ai cũng có thể đóng góp dữ liệu theo lĩnh vực cụ thể (tài liệu tài chính, ghi chú y tế, vụ án pháp lý, dữ liệu cảm biến). Các đóng góp sẽ được mã hóa, phiên bản hóa và ghi nhận. Các cộng đồng cùng nhau quản lý chất lượng thay vì một công ty giữ mọi thứ cho riêng mình.
• ModelFactory là môi trường tinh chỉnh không mã. Bạn chỉ cần chỉ định nó đến một Datanet, chọn một cơ sở mã nguồn mở và xây dựng một mô hình ngôn ngữ chuyên biệt (SLM) mà không cần phải có bằng tiến sĩ trong ML. Nó hạ thấp rào cản để các chuyên gia trong lĩnh vực như bác sĩ, nhà giao dịch, luật sư—có thể tạo ra các công cụ thực sự hiểu thế giới của họ tốt hơn một mô hình khổng lồ chung chung.
• OpenLoRA xử lý việc phục vụ hiệu quả. Nó cho phép hàng ngàn mô hình chuyên biệt này sống cùng nhau và tải động. Chi phí giảm mạnh, làm cho "AI có thể trả phí" trở nên thực tế người dùng phải trả tiền cho mỗi truy vấn, và doanh thu chảy ngược về qua PoA cho những người đã xây dựng dữ liệu và mô hình. xangle.io
Tôi thừa nhận, khi lần đầu thấy "xây dựng mô hình không mã", tôi đã lắc đầu. Nghĩ rằng nó sẽ chỉ là chiêu trò. Sau khi nhìn vào kiến trúc, tôi ngạc nhiên vì sự thực tế của nó, tập trung vào các mô hình SLM nhỏ hơn và hiệu quả hơn, hỗ trợ cho các mô hình nền tảng lớn thay vì cạnh tranh trực tiếp.
Các nhà phê bình có thể nói rằng đây chỉ là một blockchain ngách khác mà sẽ không được chấp nhận. Tại sao không chỉ sử dụng Hugging Face cộng với một số L2 hiện có? Điểm công bằng. Nhưng điều đó bỏ qua vấn đề động lực. Trên các nền tảng ngày nay, các đóng góp vẫn không sở hữu phần của họ hoặc được trả tiền khi dữ liệu của họ tạo ra doanh thu. OpenLedger nhúng quyền sở hữu và phần thưởng vào chính giao thức. Nếu không có vòng khép kín đó, dữ liệu chất lượng sẽ khô cạn theo thời gian. Chiếc bánh đà chỉ quay khi mọi người được trả công xứng đáng cho những gì họ mang lại.
Góc Nhìn Về Quyền Con Người Quan Trọng
Đây không phải là công nghệ trừu tượng. Đối với một người chú thích dữ liệu ở Nairobi hoặc Manila làm việc với nội dung độc hại chỉ để kiếm vài xu, PoA cung cấp một cái gì đó mang tính cách mạng: tín dụng có thể xác minh và bồi thường định kỳ. Mỗi khi dữ liệu được gán nhãn của họ cải thiện một mô hình đã triển khai, họ sẽ kiếm được. Điều này biến những công việc tạm thời thành sự tham gia giống như cổ phần trong nền kinh tế sáng tạo. Ở một khía cạnh rộng hơn, nó chống lại chủ nghĩa thực dân kỹ thuật số bằng cách trao cho những người đóng góp từ các nước Nam Toàn cầu quyền tự chủ kinh tế và quyền quản lý thực sự thông qua token. Đây không phải là một giải pháp hoàn hảo cho quyền lao động, nhưng đó là một cải tiến cấu trúc mà AI tập trung không có động lực để cung cấp. Phần này thực sự đã khiến tôi cảm động khi công nghệ cuối cùng cũng căn chỉnh các động lực với phẩm giá con người thay vì ngược lại. brookings.edu
Tokenomics Thực Sự Đáp Ứng Một Mục Đích
$OPEN không chỉ là một token quản trị hoặc gas. Nó là nhiên liệu: trả tiền cho việc huấn luyện và suy luận, staking cho các validator và tác nhân (với việc cắt giảm cho hành vi xấu), thưởng cho các đóng góp thông qua PoA, và bỏ phiếu về quy tắc chất lượng mô hình và hướng đi của hệ sinh thái. Tổng cung 1 tỷ, với phân bổ mạnh cho cộng đồng/hệ sinh thái để thúc đẩy sự sử dụng thực sự thay vì những đợt bán tháo sớm. Thiết kế ưu tiên tiện ích có nghĩa là hoạt động AI có giá trị hơn đồng nghĩa với nhu cầu cao hơn cho token. Tôi thích rằng nó được gắn trực tiếp với công việc được thực hiện trên mạng thay vì những lời hứa mơ hồ.
Nơi Điều Này Có Thể Dẫn Đến Trong Năm Năm Tới
Hãy tưởng tượng hàng ngàn mô hình chuyên biệt, có thể kiểm toán được chạy cho tài chính, chăm sóc sức khỏe, giáo dục và ngôn ngữ địa phương—mỗi mô hình đều có nguồn gốc rõ ràng, một phần thuộc về những người đã xây dựng chúng. Các tác nhân AI tự trả chi phí và chia sẻ doanh thu lại cho những người tạo dữ liệu. Một nền kinh tế sáng tạo toàn cầu nơi chuyên môn của bạn hoặc bộ dữ liệu được chọn lọc kỹ lưỡng của bạn trở thành một tài sản sống. Nó sẽ không thay thế các phòng thí nghiệm lớn, nhưng nó có thể tạo ra lớp giữa phong phú giúp AI trở nên dễ tiếp cận, đáng tin cậy và đa dạng hơn. Tôi lạc quan nhưng không mù quáng, việc thực thi sẽ quyết định mọi thứ.
Điều gì khiến bạn ngạc nhiên nhất khi đọc điều này? Bạn có nghĩ rằng việc ghi nhận trên chuỗi có thể thực sự chuyển giao quyền lực ra khỏi tay các công ty công nghệ lớn, hay là đã quá muộn? Tôi rất muốn nghe phản hồi hoặc câu chuyện từ những người đã đóng góp dữ liệu trong các lĩnh vực của họ. Nếu bất kỳ điều gì trong số này gây tiếng vang, hãy chia sẻ bài viết để chúng ta thu hút thêm nhiều ánh nhìn vào những dự án đang ít nhất cố gắng xây dựng sự công bằng vào trong hệ sinh thái.
Tôi tin rằng chúng ta đang ở đầu của việc coi những người đóng góp dữ liệu là những đồng sở hữu thực sự thay vì những đầu vào có thể vứt bỏ. OpenLedger không hoàn hảo, nhưng nó đang đặt ra những câu hỏi đúng và cung cấp các yếu tố thực tế để trả lời chúng.
Bạn nghĩ gì về quyền sở hữu dữ liệu, đó có phải là mảnh ghép còn thiếu, hay là một điều gì khác? Hãy để lại ý kiến của bạn trong phần bình luận. Hãy thảo luận.
Kiểm tra whitepaper tự mình: https://www.openledgerfoundation.com/white-paper