Tôi không tìm kiếm điều gì cụ thể. Thấy $OPEN được nhắc đến trong một bài viết, nhấp vào, bắt đầu đọc về hệ thống Proof of Attribution — và rồi tôi cứ… ở lại lâu hơn tôi dự đoán.
Đây là điều khiến tôi phải suy nghĩ.
Mọi người đều coi @OpenLedger như một câu chuyện về quyền sở hữu dữ liệu. Tải lên dữ liệu của bạn, sở hữu đóng góp của bạn, kiếm tiền từ AI. Đó là thông điệp. Đó là câu chuyện mà toàn bộ cộng đồng #OpenLedger rally quanh. Và bề ngoài thì có lý — cuối cùng, một hệ thống mà những người thực sự cung cấp dữ liệu cho máy móc được chia phần.
Nhưng càng đọc về cách Proof of Attribution thực sự hoạt động cơ học, tôi càng nhận ra khung sở hữu chỉ là một nửa câu chuyện. Phần mà mọi người thường bỏ qua là khi phần thưởng thực sự kích hoạt.
Bạn không kiếm được khi tải lên. Bạn kiếm được khi suy diễn.
Khoản thanh toán chỉ xảy ra khi một mô hình được truy vấn — khi ai đó chạy nó, sử dụng nó, hỏi nó điều gì đó. Dữ liệu của bạn nằm trong một Datanet, đã được xác minh, phân loại, ghi lại trên chuỗi? Vẫn chưa có giá trị kinh tế cho đến khi mô hình của nhà phát triển thực sự được gọi. Dòng $OPEN distribution chảy từ phí suy diễn, được chia sẻ giữa các nhà phát triển mô hình, những người staking, và người đóng góp dữ liệu tại thời điểm sử dụng.
Tôi nghĩ đây là một chi tiết kỹ thuật nhỏ lúc đầu. Nhưng thực sự… nó thay đổi toàn bộ bức tranh.
Bởi vì điều đó có nghĩa là giá trị kinh tế của đóng góp của bạn không được xác định bởi những gì bạn đưa vào. Nó được xác định bởi tần suất mô hình được xây dựng dựa trên đóng góp của bạn được sử dụng. Bạn không đang kiếm tiền từ dữ liệu của mình. Bạn đang nắm giữ một phần thụ động trong đường cong áp dụng của mô hình của người khác. Đó là hai điều hoàn toàn khác nhau.
Và tôi không chắc hầu hết mọi người đang tải lên Datanets ngay bây giờ hiểu được sự khác biệt đó.
Người đóng góp hưởng lợi nhiều nhất không nhất thiết phải là người có dữ liệu chất lượng cao nhất. Đó là người mà dữ liệu của họ tình cờ chảy vào một mô hình mà một nhà phát triển xây dựng tốt và quảng bá đủ mạnh để tạo ra khối lượng suy diễn nhất quán. Đó là một cược rất khác với "dữ liệu của tôi có giá trị, tôi nên được thưởng."
Nhưng đây là phần vẫn khiến tôi bận tâm.
Nếu khối lượng suy diễn là điều thực sự mở khóa kinh tế — và hiện tại khối lượng suy diễn rất mỏng theo bất kỳ tiêu chuẩn nào, mạng lưới chỉ mới khởi chạy mainnet vào tháng 11 năm 2025 — thì câu chuyện về việc kiếm tiền công bằng chủ yếu là triển vọng. Đây là một thiết kế hoạt động tuyệt vời khi có nhu cầu. Điều nó không thể làm là sản xuất ra nhu cầu đó. Máy đánh giá là vững chắc. Logic thanh toán là tinh tế. Nhưng nếu các yêu cầu suy diễn không chảy với quy mô, những người đóng góp dữ liệu ngồi trong Datanets chỉ đang… chờ đợi.
Tôi liên tục quay lại điều đó. Cơ chế là có thật. Lớp công bằng thực sự là mới lạ. Nhưng điều khiến nó có ý nghĩa kinh tế — khối lượng truy vấn, việc sử dụng mô hình nhất quán, các nhà phát triển chọn xây dựng ở đây thay vì mọi tùy chọn cơ sở hạ tầng AI khác — phần đó không được đảm bảo bởi thiết kế. Nó phải được kiếm trong thị trường.
Có lẽ điều đó rõ ràng trong hồi tưởng. Nhưng cách nó được trình bày, bạn sẽ nghĩ rằng việc tải lên dữ liệu tốt là đủ. Nó không đủ. Đó là một điều kiện khởi đầu, chứ không phải là một điều kiện đủ.
Dù sao đi nữa. Vẫn đang theo dõi cách mà phía suy diễn phát triển trong quý tiếp theo. Đó mới là con số thực sự để theo dõi — không phải giá, không phải kích thước cộng đồng. Có bao nhiêu mô hình đang được gọi, và tần suất ra sao.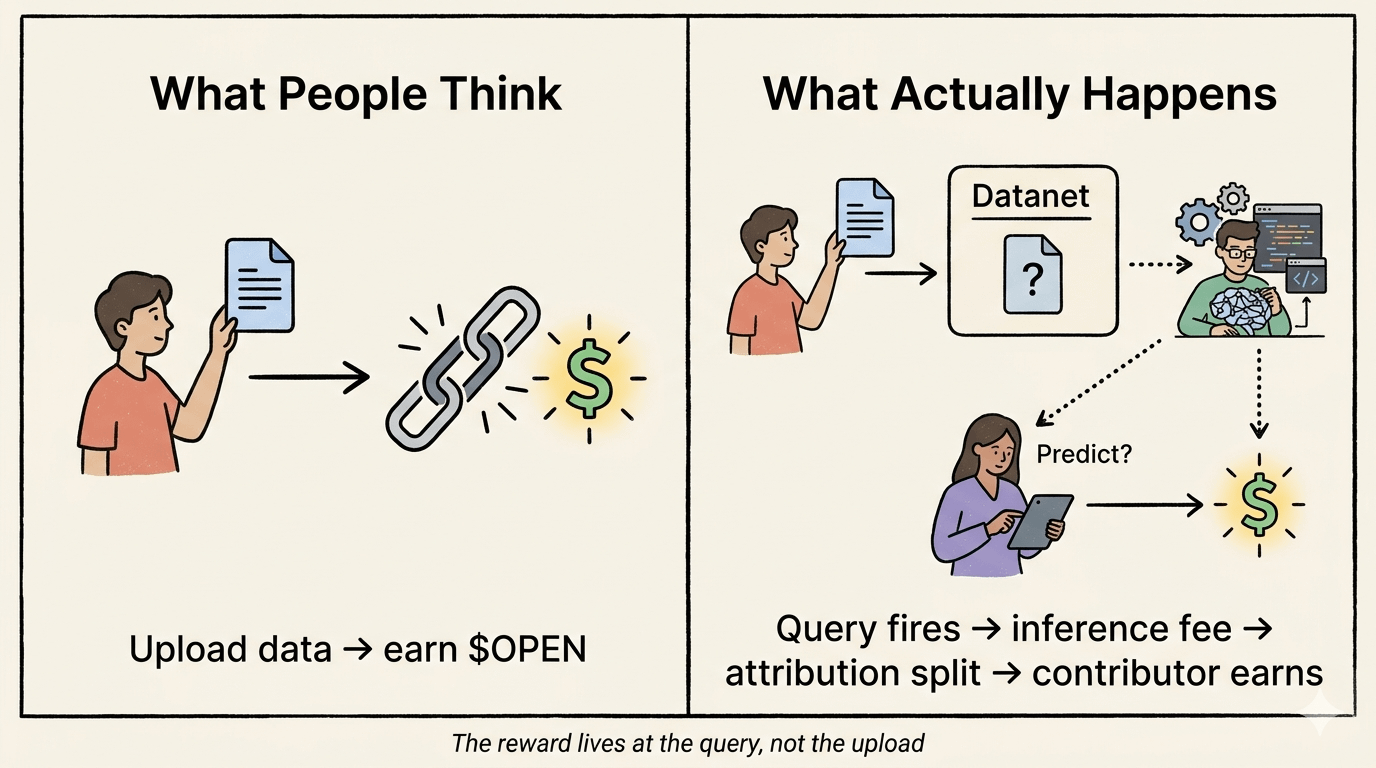
Mọi thứ khác chỉ là cơ sở hạ tầng đang chờ lý do để hoạt động.