#OpenLedger 做过联盟分佣、广告投放、渠道结算的人都知道,一个系统最怕的不是赚不到钱,而是后台算不清谁贡献了收益。谁带来的用户,谁完成了转化,谁该拿佣金,如果数据链路断掉,后面的分配就会越来越乱。
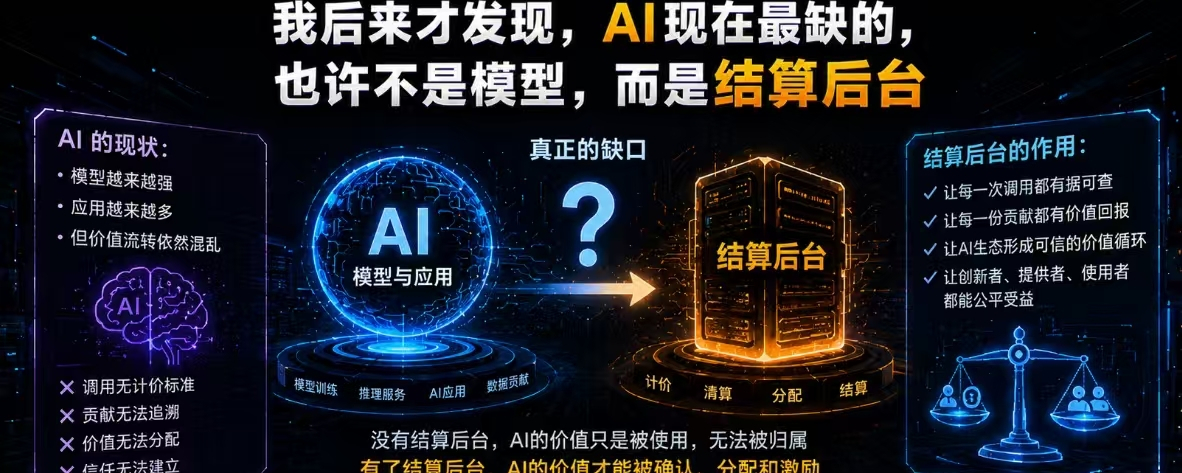
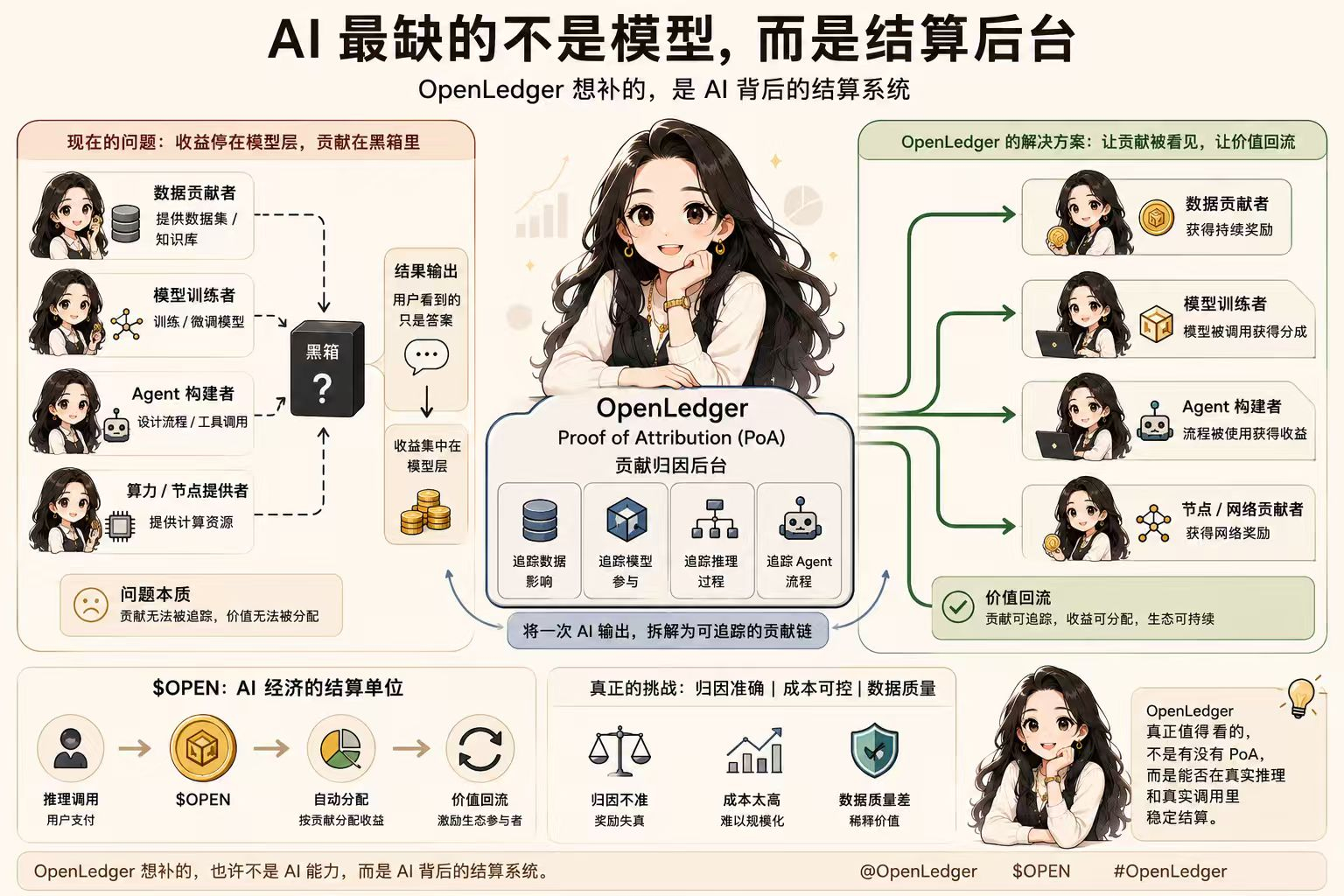
AI正在重演类似的问题。它越来越像平台经济,却还没有成熟的分佣后台。模型输出一个答案,背后可能用了很多数据、微调模型、知识库和Agent流程,但最后的收益往往只停在模型层。用户看到的是一句回答,平台看到的是调用量,可真正参与价值创造的数据贡献者、模型训练者、流程构建者,很多时候并没有进入后续收益分配。
收益停在模型层,贡献却停在黑箱里。
OpenLedger的Proof of Attribution,本质上是在给AI增加一套贡献归因后台。它要解决的是:模型回答之后,系统能不能追踪哪些数据影响了输出,哪些模型参与了推理,哪些Agent流程参与了结果生成。
也就是说,AI输出不再只是“模型说了一句话”,而开始有机会变成一条可追踪的贡献链。
如果贡献路径能被识别,数据贡献者、模型训练者、Agent构建者,才有机会进入后续收益分配。这时候,数据不再只是被模型吞掉的原料,模型不再只是一个黑箱,Agent也不只是调用工具,而是进入一个能记录贡献、计算影响、分配收益的系统。
AI负责生成答案,OpenLedger想补的,是答案背后的结算能力。

对$OPEN 来说,真正值得观察的,不是它有没有AI标签,而是它能不能进入这条结算链路。如果推理调用发生,模型访问发生,Datanets被使用,贡献奖励开始分配,那么$OPEN才可能作为gas、推理费用、模型访问、奖励分配和治理中的真实结算单位。
不过,这也是OpenLedger最难的一层。
归因如果不准,奖励就会失真;归因如果成本太高,系统就很难规模化;数据质量如果守不住,低质贡献和恶意插入也会稀释真正的价值。所以OpenLedger真正值得看的,不只是有没有Proof of Attribution,而是它能不能在真实推理和真实调用里稳定结算。
AI会越来越像基础设施。模型会越来越多,Agent会越来越多。但如果后台始终算不清谁贡献了价值、谁影响了结果、收益该流向谁,AI经济就会越来越像一个只有入口、没有分账的黑箱。
OpenLedger想补的,也许不是AI能力,而是AI背后的结算系统。