
#OpenLedger 大雷以前帮一个小团队做过垂直客服模型。
模型效果还行,测试阶段也顺利。真正麻烦的是上线之后。每个客户都想要自己的版本:电商想改话术,金融想加合规检查,教育客户又要另一套问答边界。问题不是模型不能用,而是每多一个定制版本,就多一份部署和长期服务成本。
对小团队来说,模型不是一次性交付,而是长期服务。服务的客户越多,如果每个版本都要单独占一份 GPU 资源,收入还没放大,成本先放大了。训练只做了一次,部署却要重复很多遍,小团队很容易被这一步拖住。
这是专业 AI 的一个现实问题:模型训练出来,不等于活下来。
很多小模型最后不是卡在训练阶段,而是卡在部署成本、切换成本和长期服务成本上。OpenLedger 的 OpenLoRA,瞄准的正是这个痛点。

传统方式下,每个微调模型都要单独部署,资源开销会随着版本数量迅速膨胀。OpenLoRA 的思路,是通过动态加载 LoRA 适配器,让同一套基础资源可以服务更多专业模型。请求到来时,系统调用对应的适配器完成推理,而不是让每个模型长期单独占用大量显存。
这件事的意义不只是“省钱”。它真正改变的是专业模型能不能被持续服务。成本降下来,小团队才有机会把不同客户、不同场景、不同数据训练出的模型持续跑起来,而不是训练完之后放在仓库里。
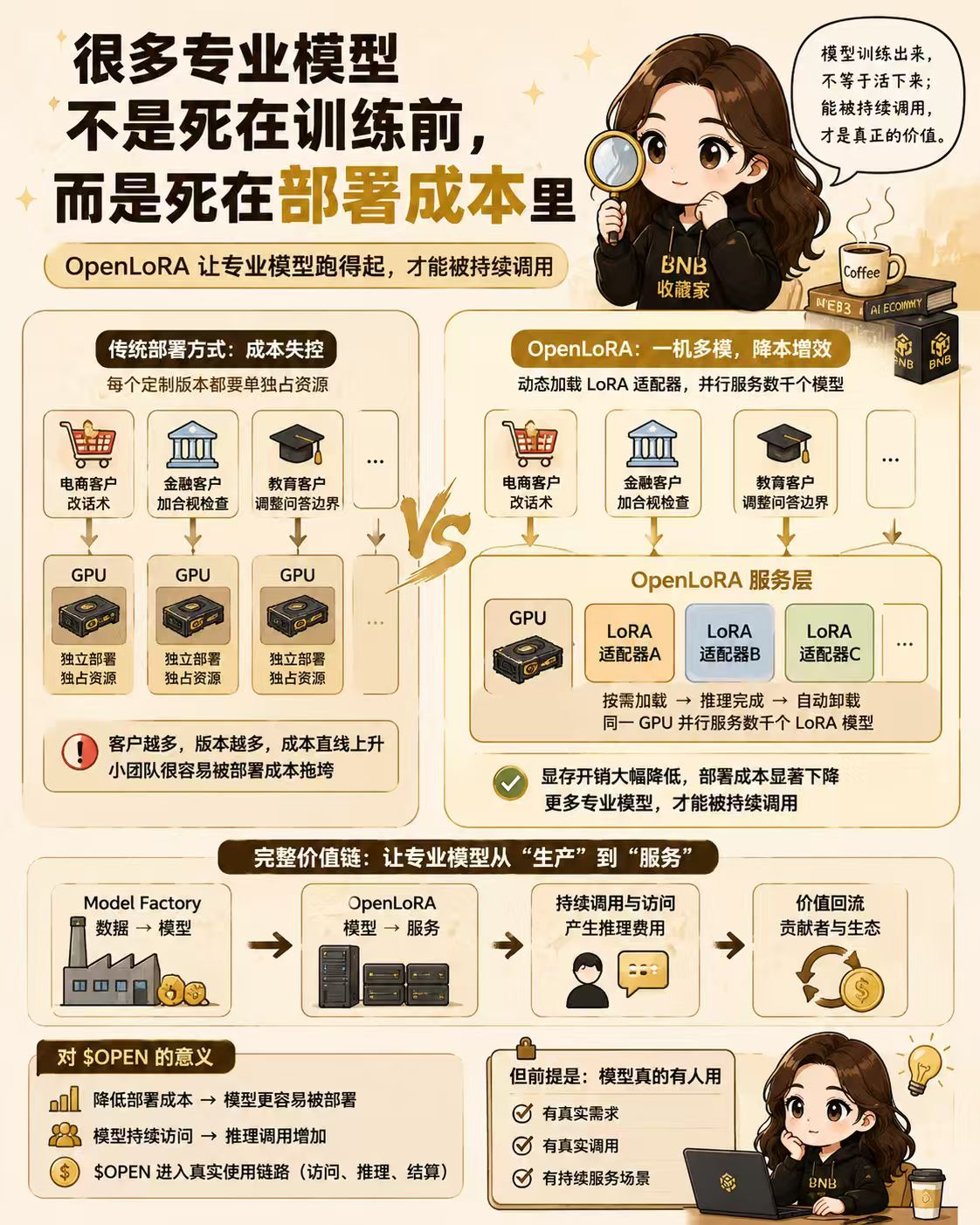
如果说 Model Factory 解决的是“数据怎么变成模型”,OpenLoRA 要解决的就是“模型怎么低成本跑起来”。一个偏生产,一个偏服务。前者让专业数据有机会进入模型生产,后者让这些模型有机会进入持续调用。
对 $OPEN 来说,OpenLoRA 的意义,不是多了一个技术组件,而是让“调用”这件事变得更经济。如果专业模型能以更低成本被部署、访问和推理,open才有机会进入模型访问、推理调用和持续服务这些真实使用链路,而不是只停在模型发布那一刻。
不过,低成本部署不是万能药。
如果模型本身没有需求,没有真实的调用场景,成本再低也只是降低库存成本。OpenLoRA 让部署更便宜,但能不能活下来,最终取决于模型有没有人真正用。真正要观察的,不是 OpenLedger 上模型数量是否漂亮,而是专业模型是否被持续调用。
模型被训练出来,只是放上了货架。真正让它活下来的,是持续调用。
很多 AI 项目都在比模型参数和训练能力,但专业模型真正的生命,不在训练完成的那一刻,也不在被发布到平台的那一刻,而在被持续访问、持续推理、持续服务客户的那一段路。
收藏家才认为,OpenLedger 想补的,正是专业模型活下来的那条跑道。