
The real challenge with @OpenLedger isn't getting a million people to show up. That part is almost easy, if you dangle the right token incentives. The hard part is getting a millIon people to bring data that actually helps, and then keeping them honest about it.

I have watched enough Web3 projects launch with great fanfare and then quietly die bEcause their contributor base turned into a ghost town of bots abot Low-effOrt copy-pasters. The token price spikes, everyone rushes in, and within weeks thE quality craters. OpenLedger is trying something different, Or at least more ambitious. They built a system that does not just reward you for uplOading a dataset, but for how useful that dataset turns out to be over time. ThAt is the twist.
Here is how it works in plain terms. You contribute sometHing, say a labeled set of medical images Or a collection of conversational transcripts. The blockchain recOrds your fingerprint on that daTa. Later, some developer in another country buIlds an AI model using your dataset, alongside a thousand others. OpenLedger runs what they call an influence engine, which is basically a fancy forensic tool that traces which pieces of data made the model smarter. If your images helped the model spot tumors more accurately, you get paid every time someone uses that model's output. Not just once. Every time.
That sounds like a Dream, right? Upload once, earn forever. But the fine print matters. The system watches your data like a hawk. If you flOod it with junk, your reputation score drops, and so does your cut of future rewards. If you deliberately poison the well, yOu lose staked tokens. It is not a passive income machine; it is a reputation economy with sharp teeth.
The econoMics also get messy in ways people do not always talk about. Most of the money from each AI query goes to the model creators and the validators who secure thE network. The remaining slice, sometimes a very thin one, gets split among everyone whose data contributed to that query. If your data was one of a thoUsand pieces used, your share might be microscopic. You would need scale, cOnsistent quality, and some luck to see real returns.
And then there is the governance question, which raRely comes up in the marketing materials. Who decides what counts as quality? Who arbitrates disputes wheN two contributors claim credit for the same insight? OpenLedger uses a token voting system, but voting power scales with hOw many tokens you stake. The same wealthy participants who capture the largest share of rewards also hold the most sway over the rules. It is not a democraCy of one person, one vote. It is a plutocracy of one token, one vote. That might be fiNe if you trust that wealth correlates Iith wisdom. But history suggests otherwise.
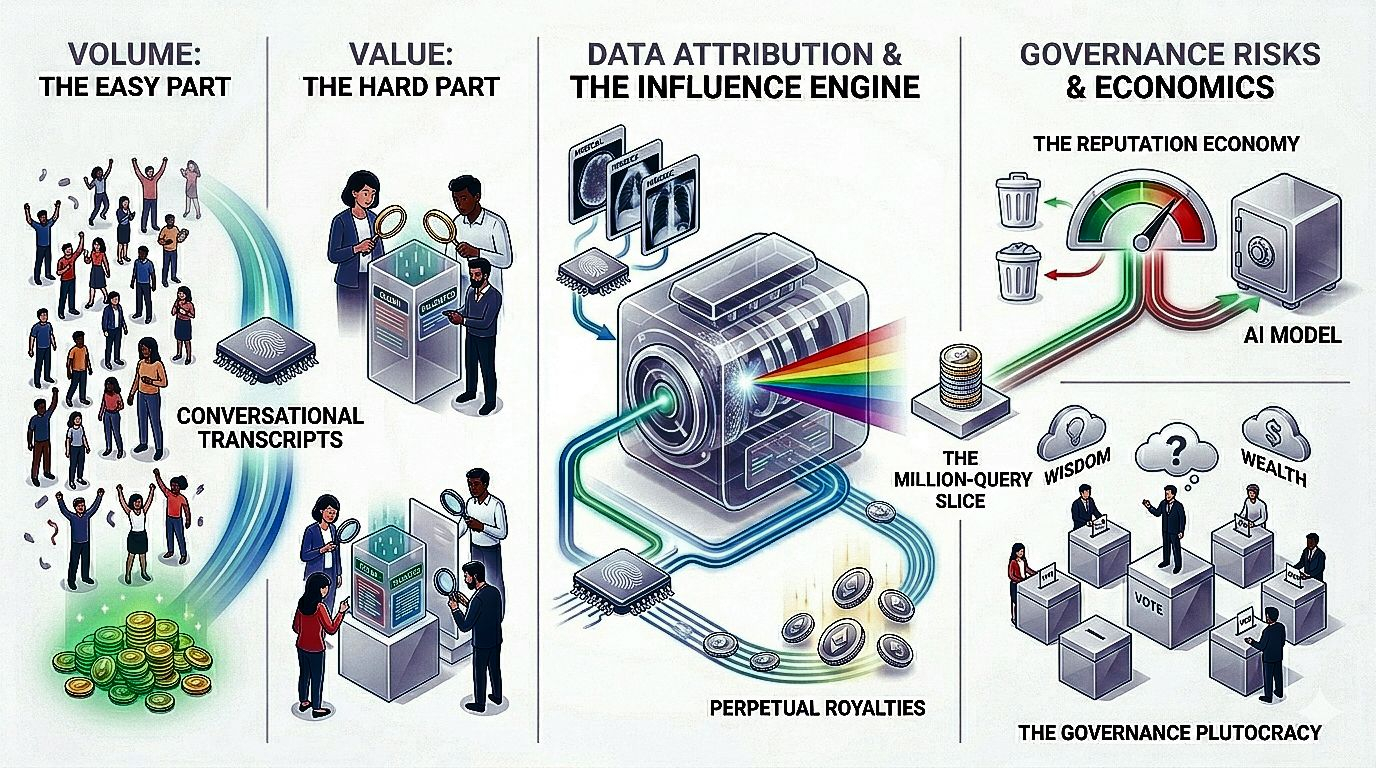
The million-coNtributor puzzle is not a technical problem. It is a human one. You can build all the clever attribution engines you want, but at the end of the day, someone sitTing at a laptop has to decide whether the effort of contributing good data is worth more than the effort of doIng somethiNg else. OpenLedger is betting that perpetual, influence-based royalties tip that balance. I am not sure yet. But I am curious enough to keep watching.



