
Honestly, most nodes in decentralized compute networks are stressing daily over balancing GPU memory costs and response speed. If you cram massive models with hundreds of billions of parameters into GPU memory, you'll barely have any compute space left to handle high-concurrency heterogeneous requests. @OpenLedger OpenLedger's recent disclosure on underlying initialization and dynamic release processes essentially employs a brutally efficient memory slicing and time-for-space scheduling logic to forcefully break through the ceiling imposed by physical hardware.
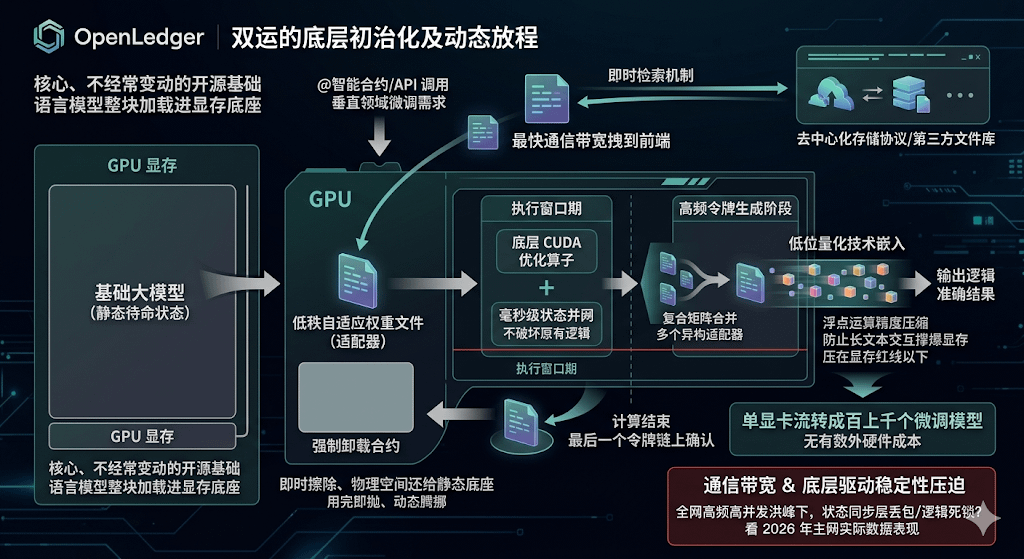
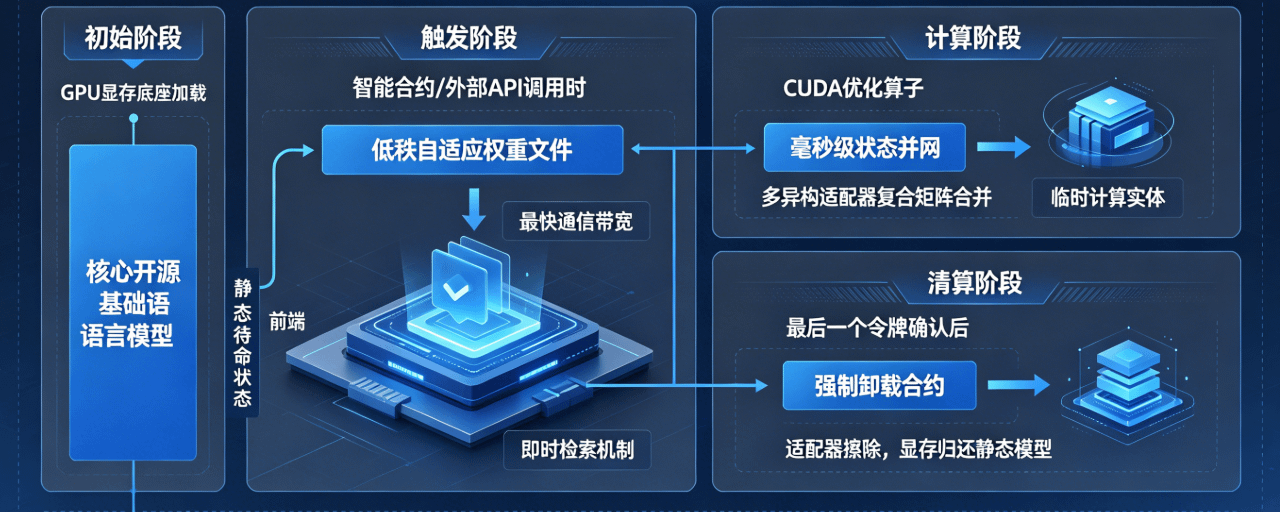
This clearing process has a very clear boundary for separating hot and cold data when it actually runs. Initially, during the startup phase of the mainnet, nodes will only load the most core, rarely changing open-source foundational language model blocks into the GPU's VRAM base. This base remains in a static standby state until it receives specific call instructions. Only when a certain smart contract on-chain or an external API clearly specifies a fine-tuning requirement for a vertical domain will the system trigger its instant retrieval mechanism, pulling the corresponding low-rank adaptive weight files from decentralized storage protocols or third-party file repositories to the front end using the fastest communication bandwidth.
This dynamically pulled adapter, during the window for entering the compute kernel, will directly utilize low-level CUDA optimized operators to achieve millisecond-level state integration without disrupting the original logic of the foundational model. What's even more hardcore is that this merging isn't limited to a single linear relationship; the system supports multiple heterogeneous adapters to perform composite matrix merging within the same execution window, allowing for the rapid assembly of a temporary computational entity with multiple specialized capabilities.
Once the network integration is successful, the merged temporary model will immediately enter the high-frequency token generation phase. During this phase, to prevent high-density long text interactions from completely maxing out the VRAM, the system will forcefully embed low-bit quantization techniques in the computation flow, compressing the floating-point operation precision to the bandwidth range that the hardware is most comfortable with. This way, it preserves the logical accuracy of the final output while keeping the instantaneous memory usage firmly below the red line.
The place where this architecture's real combat effectiveness is reflected is actually in the clearing and winding-up phase after computation. As soon as the last token of the inference request completes on-chain confirmation and is returned to the user, the system will immediately trigger a forced contract unload, completely erasing the recently merged adapter from the VRAM, restoring the precious physical space back to the foundational static large model.
This disposable, dynamic maneuvering approach has successfully enabled a single GPU in the heterogeneous network to handle hundreds to thousands of finely-tuned models simultaneously without increasing hardware costs. However, this high-frequency VRAM wiping and instant integration put extreme pressure on the node's communication bandwidth and the stability of the underlying drivers. If a massive demand for high-frequency arbitrage arises across the network, will the node's intensive pulling and unloading of adapters tens of thousands of times in a short period lead to sudden packet loss or logical deadlocks in the native state synchronization layer? We'll have to see how much this clearing's physical boundary can withstand the flood in the actual mainnet performance in 2026. $OPEN