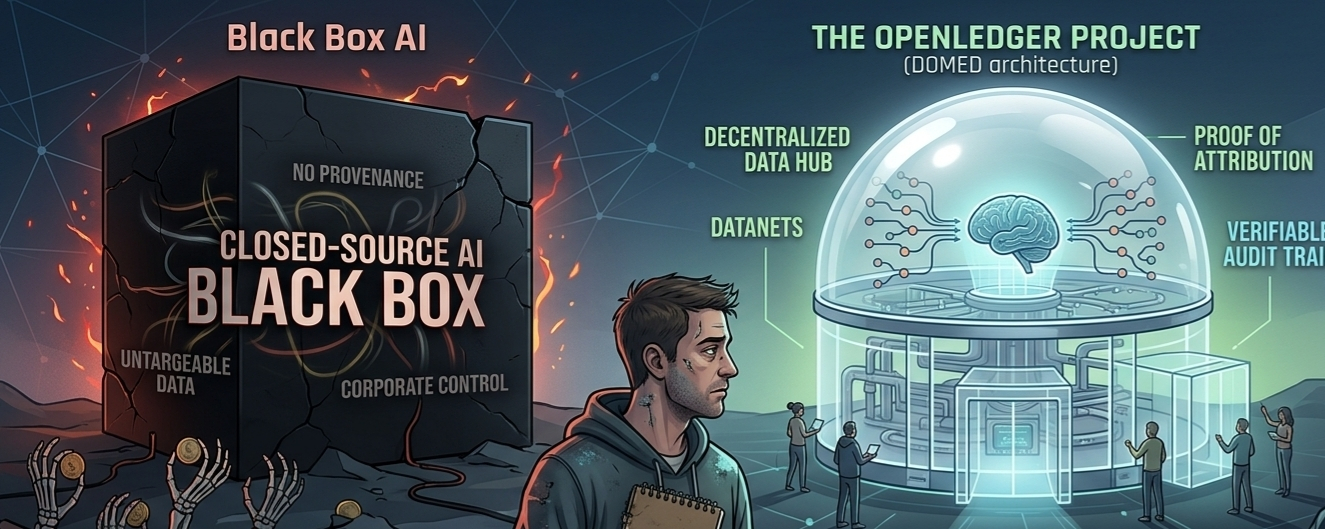

Let’s be honest: 99% of the crypto-AI crossover is an absolute joke. It's a depressing circus of lazy GPT wrappers, vaporware layer-2s, and teams dusting off their old 2021 "decentralized compute" pitch decks just to dump a micro-cap token on retail.
But I’ve been digging into OpenLedger lately, and it’s the first thing in a long time that made me stop scrolling and actually think. I’m not pitching a token here. I want to look past the marketing fluff because if they can actually pull off what they are proposing, we are looking at the foundational architecture for how data and intelligence scale over the next decade.
Here is the actual reality of what’s under the hood.
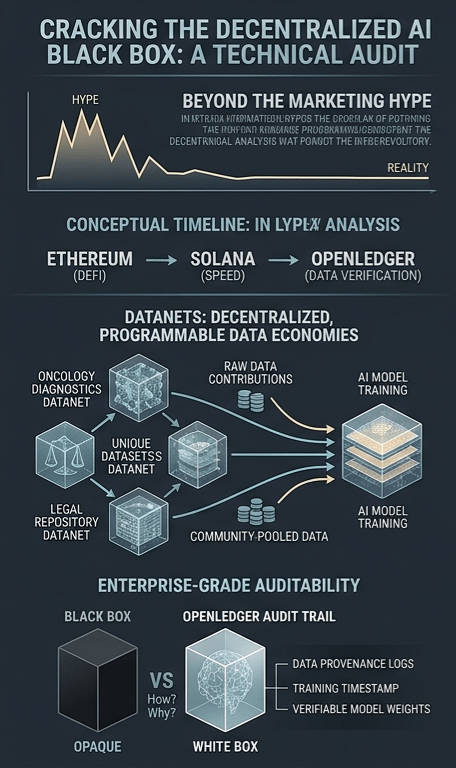
1. Moving Beyond the Marketing Sticker
Most crypto-AI projects treat artificial intelligence as a narrative play. They build a standard EVM fork, stick a basic chatbot on their website, and tell you that paying for an API key with a memecoin is "decentralized AI." It’s incredibly lazy.
OpenLedger is trying to build a state machine that actually understands AI natively.
Look at the history: Ethereum was built for moving and locking capital (DeFi). Solana was built for hyper-fast execution. OpenLedger’s architecture is focused purely on handling data pipeline and validation logic at the protocol level. The validators aren't just verifying basic wallet balances; they are verifying data inputs and model states. It's a pivot away from "code is law" toward a model where verified data and compute equal actual economic value.
2. Datanets and the Fight for Data Sovereignty
We keep hearing that "data is the new oil," which is a terrible analogy because oil is controlled by monopolies that extract value while leaving everyone else with nothing. Right now, Big Tech models scrape our collective information, train a closed-source model, and monetize it behind a paywall.
OpenLedger's workaround for this is what they call Datanets.
Think of a Datanet as a specialized, sovereign data hub. If you create a Datanet for oncology diagnostics, a community can pool raw CT scans, medical journals, and expert annotations. Instead of a tech giant stealing this data, the Datanet acts as a programmable economic zone. When a developer wants to use that specific dataset to fine-tune a model, the underlying smart contracts handle the tracking. It’s not just a decentralized Dropbox; it’s an immutable ledger tracking exactly who contributed what.
3. Proof of Attribution: Solving the Micro-Payment Nightmare
This is the hardest engineering problem in the entire stack, and it's what makes or breaks the project. How do you fairly pay millions of fractional contributors when an AI output only uses a tiny slice of their data?
The current proposal is Proof of Attribution (PoA). This is a cryptographic framework meant to trace a model's specific output back to the training data weights that influenced that exact response.
If an AI generates a highly complex legal document, the PoA layer maps the influence vector in real-time. For example:
40% of the weight came from a specific legal repository.
30% came from a developer's fine-tuning parameters.
20% goes to the node provider running the heavy hardware.
10% goes to the network treasury.
Instead of a flat subscription fee, the economy shifts toward real-time value streaming based on actual data influence.
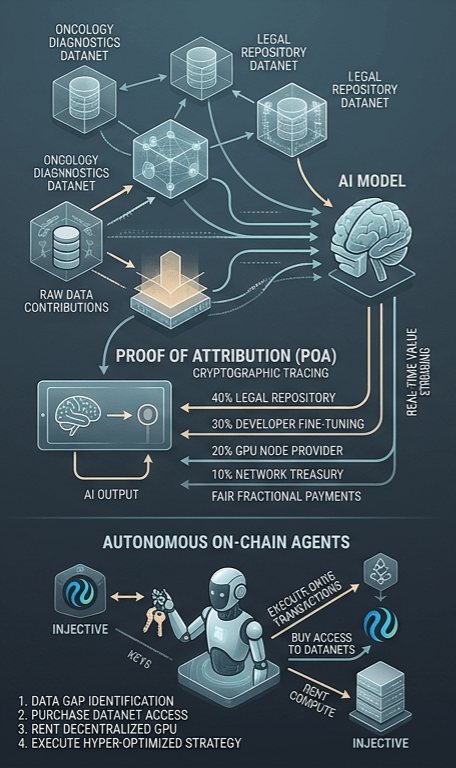
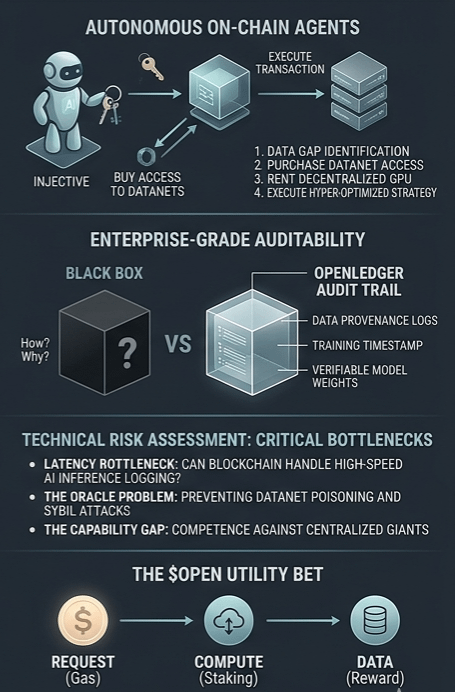
4. The Real Target: Autonomous On-Chain Agents
The ultimate goal here isn't to build tools for humans to play with. The real endgame is building the plumbing for autonomous AI agents to act as independent economic entities.
We aren't talking about simple trading bots. We are talking about autonomous code that can:
1. Identify a gap in its own training data.
2. Search for and buy access to a specific Datanet.
3. Rent decentralized GPU power to run an update.
4. Execute a hyper-optimized strategy across a network like Injective.
When an agent can hold its own keys, spend capital, and earn revenue natively without a human intermediary, you get entirely self-sustaining, code-based businesses.
5. Cracking the AI Black Box
Regulators and enterprises are terrified of LLMs because they are complete black boxes. If a hospital or a legacy bank asks a proprietary model a mission-critical question, the model cannot explain how or why it reached its conclusion. You can't easily audit a multi-billion-parameter neural network.
By moving metadata onto a public, verifiable ledger, OpenLedger opens up the pipeline. It logs:
* The exact provenance of the training data.
* The timestamp of the training run.
* The exact model weights used for a specific query.
This turns a sketchy black box into an auditable trail, which is exactly what enterprise compliance teams actually need before they touch any AI tool.
6. The Red Flags: Why This Might Fail
I like the vision, but let’s stop drinking the Kool-Aid for a second and talk about the massive engineering roadblocks.
The Latency Bottlenec AI inference requires massive computational speed. If you try to log every single weight adjustment or micro-thought onto a blockchain state machine in real-time, the network will completely choke under the weight of its own data. They have to find a radically efficient way to compress this data before it hits the chain, or it will be too slow to be usable.
The Poisoned Well (Oracle Probleme: Proof of Attribution only works if the incoming data is pristine. If a Datanet gets flooded with synthetic garbage, sybil attacks, or poisoned data vectors, the network will end up mathematically rewarding bad actors.
The Capability Gap: Open-source and decentralized models are constantly playing catch-up with centralized titans like OpenAI or Google. OpenLedger can build the most elegant decentralized economy on earth, but if the underlying models aren't smart enough to solve real problems, users will just stick to centralized alternatives.
7. Cutting Through the Tokenomics
Most tokens in this niche are useless governance tokens designed to give founders an exit. With OPEN, the utility is directly tied to network velocity. It’s the gas required for inference requests, the reward mechanism for data providers, and the economic collateral that node operators have to stake to ensure honest behavior.
It’s a binary bet. If the network successfully coordinates data and compute for millions of daily queries, the structural demand for the token is real. If the ecosystem fails to attract real developers, the utility drops to zero.
The Bottom
OpenLedger isn’t trying to build another slightly faster blockchain. They are making a massive bet on a future where we move away from renting intelligence from centralized corporations who gatekeep our data on corporate cloud servers. It’s a highly ambitious, technically risky gamble to build an open, decentralized operating system for machine intelligence. It could completely fall apart under technical complexity—but it’s one of the few things in crypto actually worth watching right now.
