
I gotta clear something up first: I'm not here to hype $OPEN, I'm here to reflect on why I didn't spot something like OpenLedger back in the day.
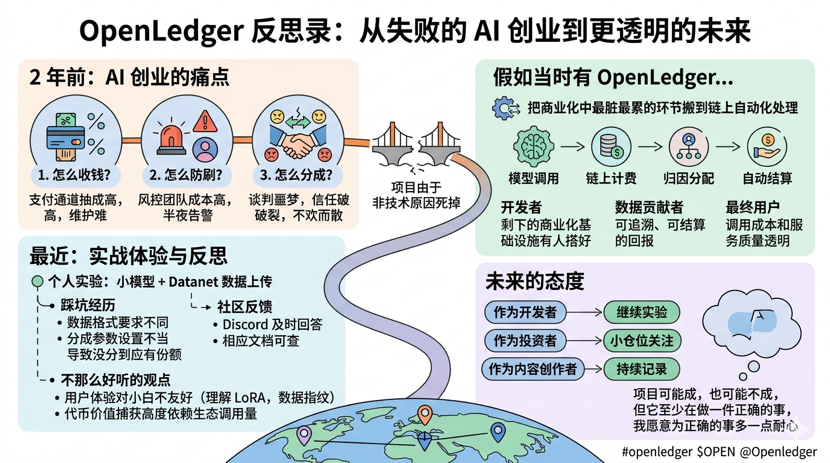
Two years ago, I teamed up with a couple of friends to launch an AI project aimed at providing automatic product description generation for small and medium-sized e-commerce businesses. Technically, it wasn't rocket science, but commercializing it was the tough part. We spent over six months focused on three key issues: first, how to collect payments; second, how to prevent users from gaming the system; and third, how to share profits with partners who provided us with training data.
In the end, this project flopped, not because the tech was weak, but because we didn't nail these three things. We needed a payment gateway to collect cash, and every transaction came with a cut; we had to set up a risk management team to prevent abuse, which meant waking up in the middle of the night to handle alerts; and negotiating profit shares was a total nightmare, with partners thinking we were greedy, and us feeling the same about them, leading to a messy breakup.$HEI
If we had infrastructure like OpenLedger back then, our story might be completely different.
What OpenLedger is doing essentially automates the dirtiest, hardest, and most contentious parts of commercializing AI on-chain. Model calls → on-chain billing → attribution distribution → automatic settlement, the entire chain does not require any human intervention or centralized trust assumptions. For developers, this means you just need to train the model, and the rest of the commercialization infrastructure is set up for you; for data contributors, this means every contribution has traceable and liquidatable rewards; for end-users, this means lower calling costs and more transparent service quality.
This is a very fundamental, infrastructure-related matter. It's not sexy, and it won't make you rich overnight, but it addresses real issues.
I've spent a considerable amount of time experimenting with OpenLedger lately. I hooked up a small fine-tuning model to its system and uploaded several batches of corresponding training data to the relevant Datanet. The whole process wasn't that smooth; I hit quite a few snags—like the data format requirements being different from what I thought, and the revenue share parameters not being set correctly at first, causing my uploaded data to miss out on its rightful share. But every snag had someone responding on Discord, and every issue had relevant documentation available. This community atmosphere makes me feel that the team is taking this seriously.
But I also want to say a few things that might not be so pleasant.
The current user experience with OpenLedger is still not friendly enough for newbies. If you don't know what LoRA is, what data fingerprints are, or what attribution weights mean, you won't be able to use it. This means it will only serve professional users for a long time, far from the vision of "letting everyone get a piece of the AI economy."
Moreover, $OPEN as a token value capture mechanism, currently relies heavily on the ecological call volume. If the call volume doesn't pick up, the fundamentals of the token won't hold up, which in turn affects the enthusiasm of ecosystem participants. This is a classic flywheel startup issue, and we need to observe whether it can get spinning.
My current stance is: as a developer, I will continue experimenting with @OpenLedger ; as an investor, I will maintain a small position and keep an eye on it; as a content creator, I will continue to document my real experiences. This project may succeed or fail, but at least it's doing something right, and I'm willing to be a bit patient for the right thing. $BTC
If you've also been burned by AI startups, you might feel the same way I do. #OpenLedger
