I used to think the phrase data is the new oil was mostly accurate.Not perfect.But close enough.
AI systems consume data. Better data produces better outputs. Companies compete to acquire it. The analogy seemed obvious.The deeper I went into AI, though, the less convincing that comparison became.
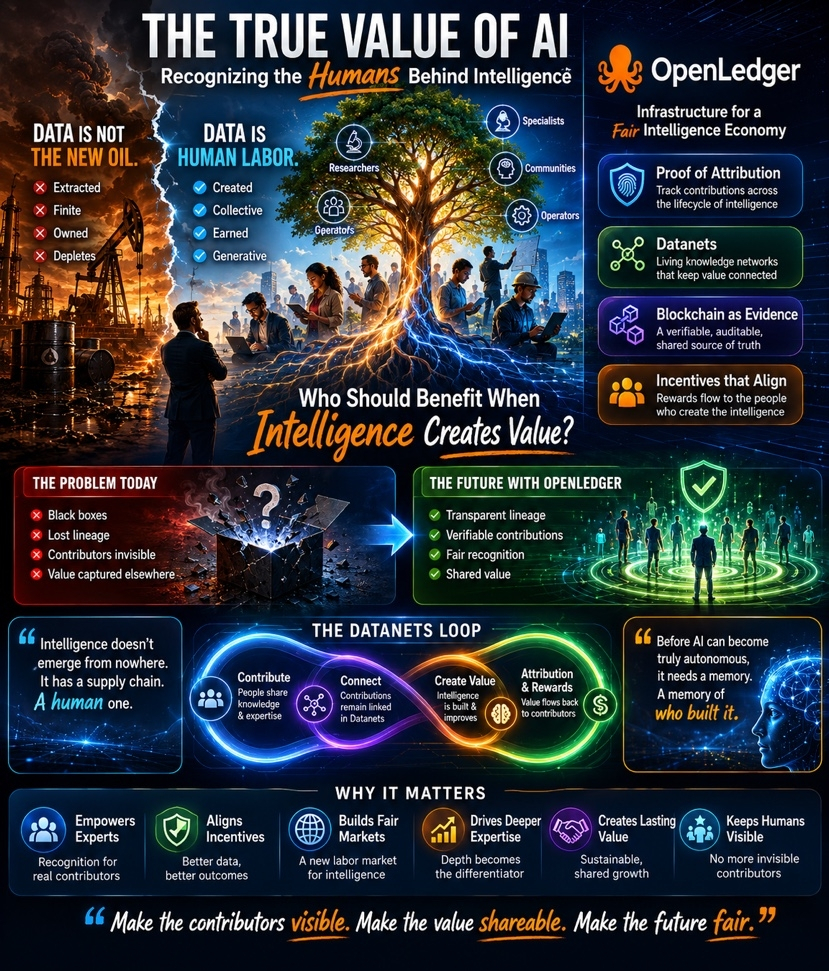
Oil is extracted.
Data is created.
That distinction matters more than I initially realized.
Every useful dataset sits on top of human effort that often becomes invisible once the model is deployed. Researchers publish findings. Specialists spend decades developing expertise. Communities challenge assumptions, refine ideas, and uncover edge cases. Operators document processes. Users provide corrections. Entire fields slowly accumulate knowledge through trial, disagreement, and repetition.
AI does not discover most of that from scratch.
It inherits it.
Which is why I have started thinking about data less as a resource and more as labor.
Collective labor.
Distributed labor.
A form of work performed by millions of people who rarely see themselves represented in the economic story that follows.And that’s where things start to feel strange.
When an AI system generates value, the conversation usually centers around the model, the company, or the product.
Not the people whose knowledge made the intelligence possible.
A model writes a report.Answers a question.
Generates a diagnosis.
Produces a recommendation.
Value appears.
Revenue follows.
The contributors disappear.The more I thought about it, the more it felt like a missing accounting system rather than a missing technology.
We have sophisticated mechanisms for measuring compute.Sophisticated mechanisms for measuring capital.Sophisticated mechanisms for measuring ownership.Yet when it comes to measuring who actually contributed to intelligence itself, the infrastructure feels surprisingly incomplete.
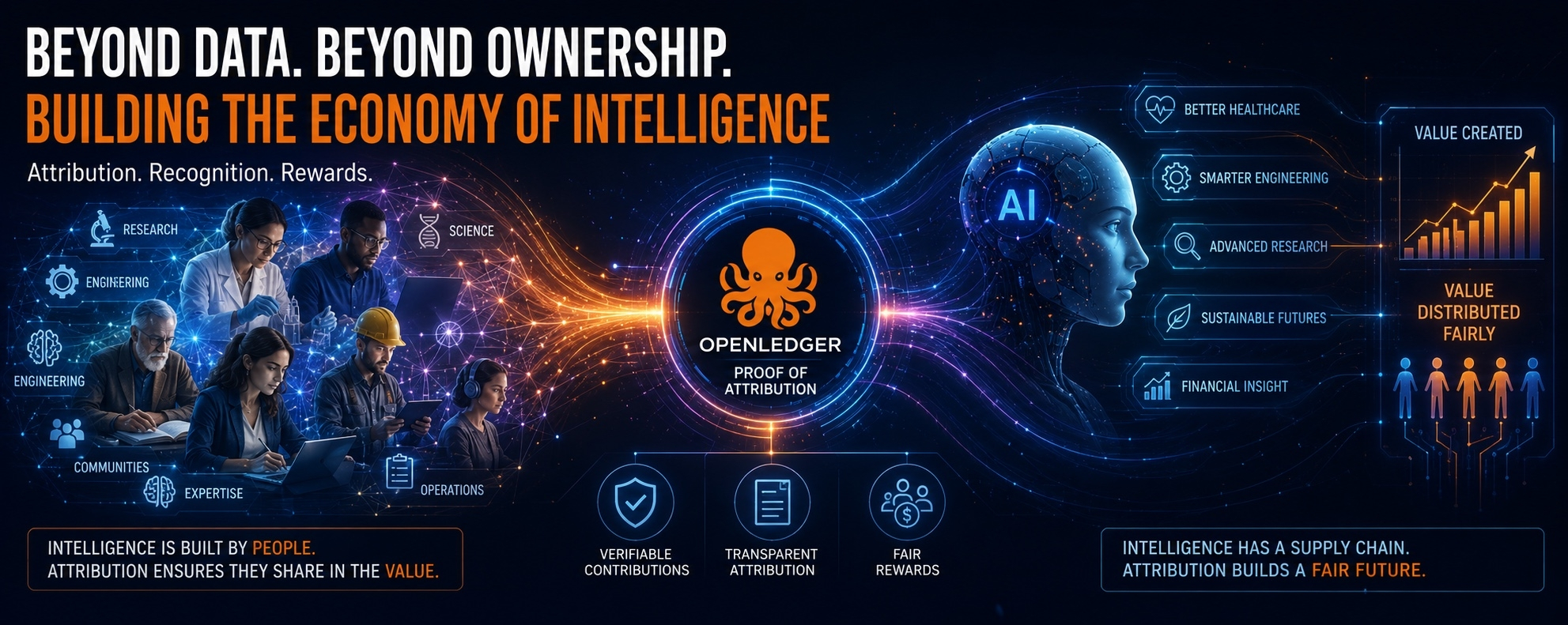
That question eventually led me to OpenLedger
My first reaction was skepticism.Probably because I have seen enough AI and crypto projects to develop a healthy reflex.Most of them start with a trend and work backward toward a justification.The technology often feels secondary.The narrative comes first.So I assumed OpenLedger would be another version of the same story.It was not
At least not from what I found after spending time with the whitepaper.
What stood out was not the blockchain.It was not the token.It wasn’t even the AI infrastructure.It was the economic problem sitting underneath everything.
Who should benefit when intelligence creates value?
Simple question.
Surprisingly difficult answer.
Most AI systems today operate like giant black boxes. Information goes in. Outputs come out. Revenue gets generated somewhere in the process.
What gets lost is the lineage.
Where did the knowledge originate?
Whose expertise improved the model?
Which contributions actually influenced the result?
Who helped transform raw information into something useful?
OpenLedger approaches those questions through what it calls Proof of Attribution.
At first, I assumed it was primarily a technical mechanism. The more I thought about it, the more it looked like accounting.Not accounting for money.Accounting for contribution.
The goal isn’t merely to identify that data exists. It’s to create a framework where contributions can be tracked across the lifecycle of intelligence itself.That’s an important distinction.
Because attribution isn’t really about recognition.It’s about incentives.If contributors remain invisible, the economic rewards naturally concentrate around whoever owns the final interface.We have seen that movie before.
The internet spent two decades rewarding distribution.
Platforms captured attention.Platforms controlled access.Platforms accumulated value.
Creators, experts, and contributors often operated downstream from the entities that owned the pipes.
AI may change that equation.Not because distribution disappears.Because expertise becomes scarcer.
A general purpose model can answer a million questions.A domain specific model can solve a million dollar problem.Those aren’t the same thing.
And increasingly, I suspect markets will care more about the second category. The future probably isn’t one model that knows everything.It’s thousands of intelligence systems that know particular things exceptionally well.
Healthcare.
Law.
Engineering.
Scientific research.
Manufacturing.
Climate modeling.
Financial analysis.
Every one of those domains depends on specialized knowledge that takes years to develop.Depth becomes the differentiator.And depth comes from people.Which makes attribution impossible to ignore.
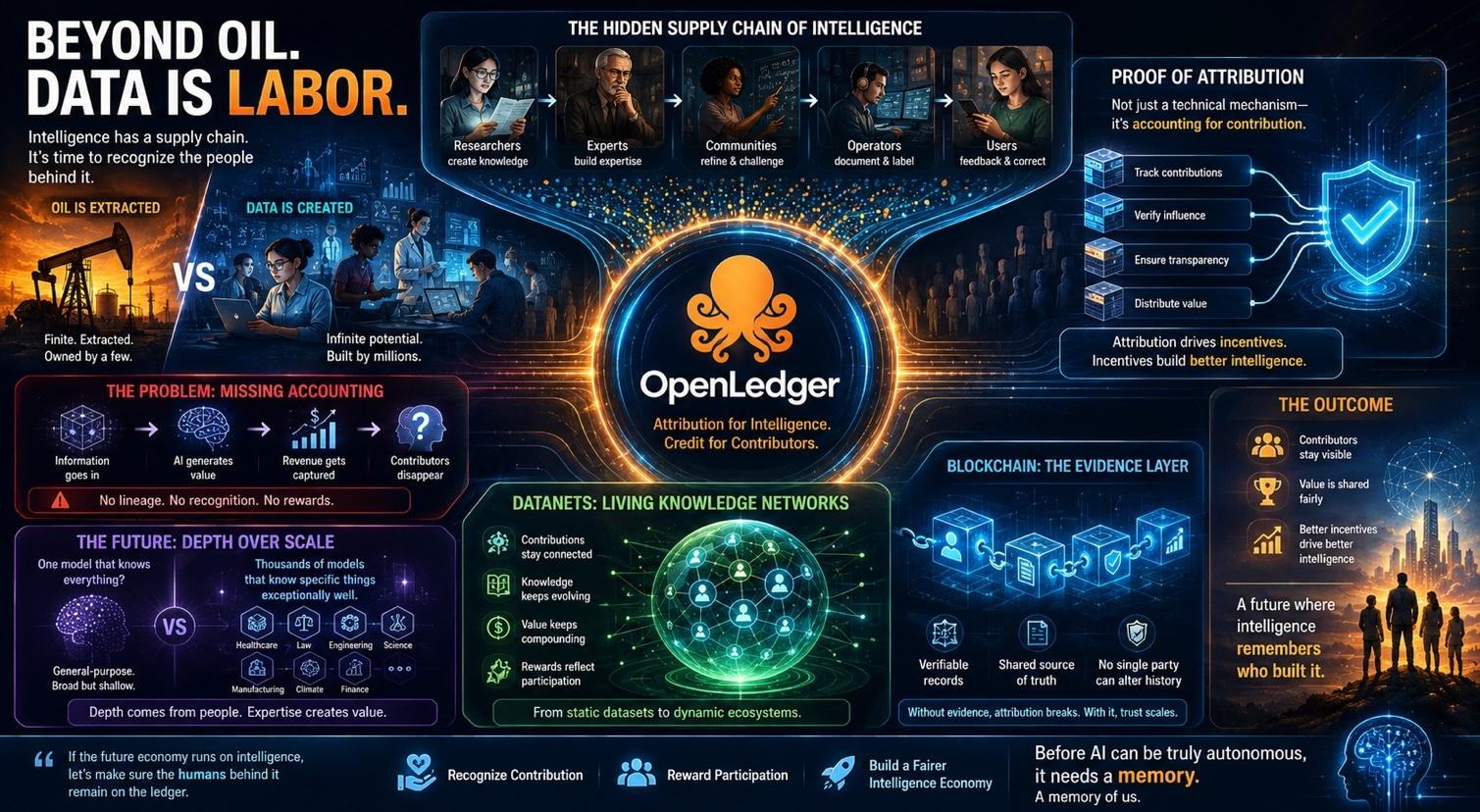
That shift is what made OpenLedger’s Datanets concept particularly interesting to me.The way I interpret it Datanets function as living knowledge networks rather than static datasets.
Information doesn’t simply get collected and consumed.
Contributions remain connected to an ongoing system.
Knowledge continues generating value.
Attribution continues tracking that value.
Rewards continue reflecting participation.
At least that’s the ambition.
It’s a fundamentally different model from the way data is typically treated today.
Most datasets resemble extraction.
Information enters the system once.
The connection to its source gradually disappears.
Economic value accumulates elsewhere.
Datanets seem designed around the opposite assumption.
Knowledge should remain economically linked to the people and communities responsible for producing it.That’s also where the blockchain component started making practical sense to me.Not because blockchains magically improve every problem.They don’t.
Most things don’t need one.
But attribution introduces a trust problem.
If contributions determine ownership, contribution records need to be verifiable.If rewards are distributed based on participation, participation needs to be auditable.
If multiple parties are involved in producing intelligence there needs to be a shared source of truth that no single participant controls.
Suddenly, the ledger is not the product.
It’s the evidence layer.
Without it attribution becomes difficult to prove.
And if attribution can’t be proven, the incentive system eventually breaks.The longer I sat with the whitepaper, the less it felt like an AI project and the more it felt like infrastructure for a future labor market.
A labor market where intelligence itself becomes an asset class.Not intelligence generated by machines alone.Intelligence assembled from human expertise, data, feedback, refinement, and continuous contribution.That’s a very different framing.
And honestly, one that I don’t think enough people are paying attention to yet.Most discussions around AI still revolve around model capabilities.
Bigger context windows.
Faster inference.
More parameters.
Higher benchmarks.
But they only answer one side of the equation.
The other side is economic.
Who gets compensated?
Who gets recognized?
Who captures the value?
Who gets written out of the story?
Those questions become harder to avoid as AI systems become more useful.
Because intelligence doesn’t emerge from nowhere.It has a supply chain.
Maybe that’s why OpenLedger keeps sticking in my head
Not because it’s promising autonomous intelligence.
Not because it’s combining crypto and AI.
But because it’s asking a question that feels increasingly unavoidable.If the future economy runs on intelligence, how do we make sure the people who contributed that intelligence remain visible?
Before AI can become truly autonomous, it may need something much more basic.
A reliable memory.
A way to remember where intelligence came from.
A way to track contribution across time.
A way to ensure that when value is created, the humans behind that value don’t simply disappear from the ledger of history.
