
It was close to midnight when I finally stopped blaming myself and started blaming the system.
I was watching a deployment crawl forward in fits and starts, gas estimates drifting between probably fine and absolutely not, mempool congestion spiking without warning, retries stacking up because a single mispriced transaction had stalled an entire workflow. Nothing was broken in the conventional sense. Blocks were still being produced. Nodes were still answering RPC calls. But operationally, everything felt brittle.
That’s usually the moment I stop reading threads and start testing alternatives.
This isn’t about narratives or price discovery. It’s about where Vanry actually lives,not philosophically, but operationally. Across exchanges, inside tooling, on nodes, and in the hands of people who have to make systems run when attention fades and conditions aren’t friendly.
As an operator, volatility doesn’t just mean charts. It means cost models that collapse under congestion, deployment scripts that assume ideal block times, and tooling that works until it doesn’t, then offers no useful diagnostics. I’ve run infrastructure on enough general purpose chains to recognize the pattern: systems optimized for open participation and speculation often externalize their complexity onto operators. When usage spikes or incentives shift, you’re left firefighting edge cases that were never anyone’s priority.

That’s what pushed me to seriously experiment with Vanar Network, not as a belief system, but as an execution environment.
The first test is always deliberately boring. Stand up a node. Sync from scratch. Deploy a minimal contract set. Stress the RPC layer. What stood out immediately wasn’t raw speed, but predictability. Node sync behavior was consistent. Logs were readable. Failures were explicit rather than silent. Under moderate stress, parallel transactions, repeated state reads, malformed calls, the system degraded cleanly instead of erratically.
That matters more than throughput benchmarks.
I pushed deployments during intentionally bad conditions: artificial load on the node, repeated contract redeploys, tight gas margins, concurrent indexer reads. I wasn’t looking for success. I was watching how failure showed up. On Vanar, transactions that failed did so early and clearly. Gas behavior was stable enough to reason about without defensive padding. Tooling didn’t fight me. It stayed out of the way.
Anyone who has spent hours reverse engineering why a deployment half-succeeded knows how rare that is.
From an operator’s perspective, a token’s real home isn’t marketing material. It’s liquidity paths and custody reality. Vanry today primarily lives in a small number of centralized exchanges, in native network usage like staking and fees, and in infrastructure wallets tied to validators and operators. What’s notable isn’t breadth, but concentration. Liquidity is coherent rather than fragmented across half-maintained bridges and abandoned pools.
There’s a trade off here. Fewer surfaces mean less composability, but also fewer failure modes. Operationally, that matters.
One of the quieter wins was tooling ergonomics. RPC responses were consistent. Node metrics aligned with actual behavior. Indexing didn’t require exotic workarounds. This isn’t magic. It’s restraint. The system feels designed around known operational paths rather than hypothetical future ones.
That restraint also shows up as limitation. Documentation exists, but assumes context. The ecosystem is thin compared to general-purpose chains. UX layers are functional, not friendly. Hiring developers already familiar with the stack is harder. Adoption risk is real. A smaller ecosystem means fewer external stress tests and fewer accidental improvements driven by chaos.
If you need maximum composability today, other platforms clearly win.
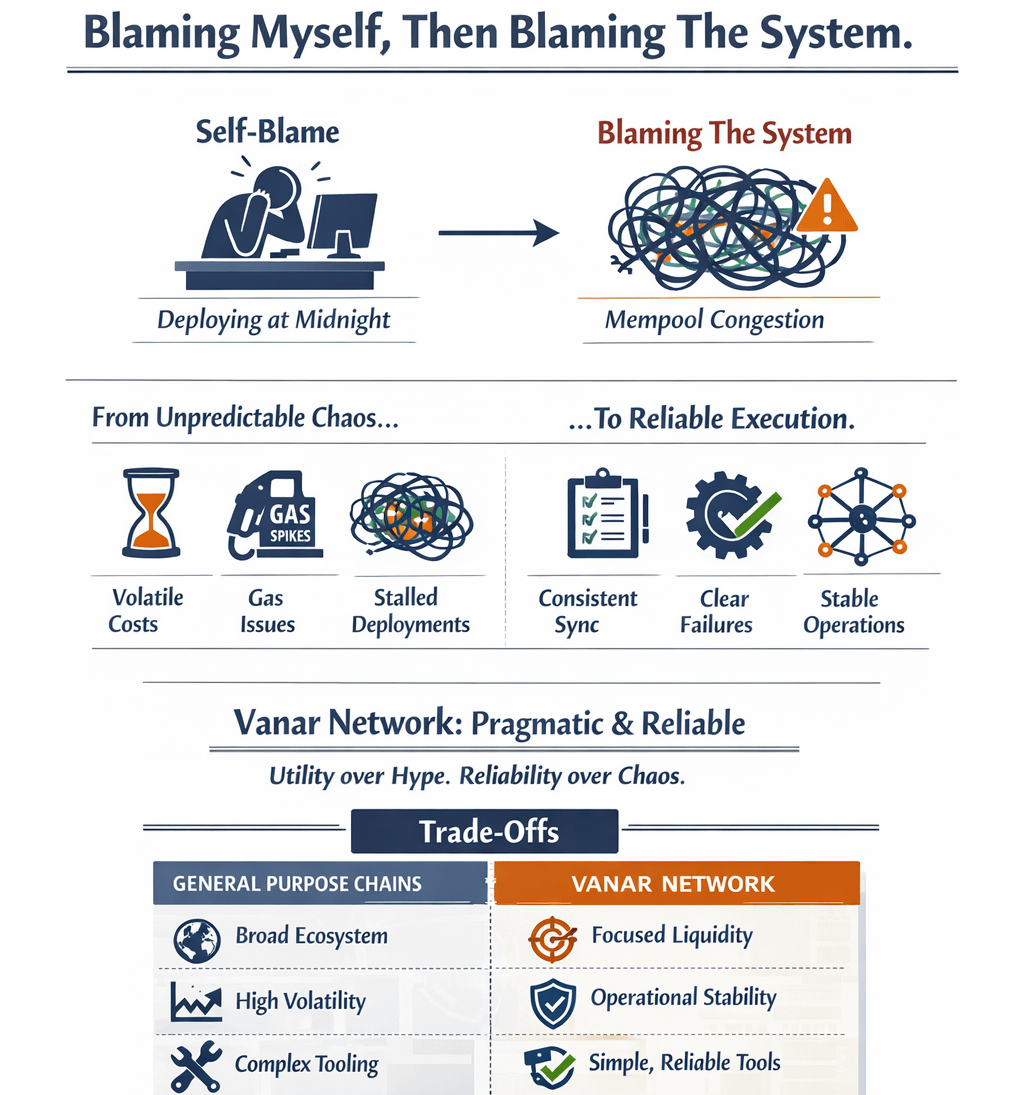
Compared to larger chains, Vanar trades ecosystem breadth for operational coherence, narrative velocity for execution stability, and theoretical decentralization scale for systems that behave predictably under load. None of these are absolutes. They’re choices.
As an operator, I care less about ideological purity and more about whether a system behaves the same at two in the morning as it does in a demo environment.
After weeks of testing, what stuck wasn’t performance numbers. It was trust in behavior. Nodes didn’t surprise me. Deployments didn’t gaslight me. Failures told me what they were.
That’s rare.
I keep coming back to the same metaphor. Vanar feels less like a stage and more like a utility room. No spotlights. No applause. Just pipes, wiring, and pressure gauges that either work or don’t.
Vanry lives where those systems are maintained, not where narratives are loudest. In the long run, infrastructure survives not because it’s exciting, but because someone can rely on it to keep running when nobody’s watching.
Execution is boring. Reliability is unglamorous.
But that’s usually what’s still standing at the end.
@Vanarchain #vanar $VANRY
