Я довго відкладав це на потім, але у неділю все ж вирішив нарешті апгрейднути свій старий ПК.
Здавалося б, звичайна справа - зайти на сайт Розетки, подивитися ціни, обрати найкращу, замовити. А ось і ні. Коли я побачив ціни, рука сама потягнулася чухати потилицю. Планки DDR5, які ще влітку кштували досить помірно, тепер відкусували від мого гаманця значно більше.
"Що взагалі відбувається з ринком?" - подумав я, та поліз в мережу шукати галузеві звіти від аналітиків. Відповід виявилася простою і водночас приголомшовою.
Попит на пам'ять злетів не через те, що люди масово вирішили апгрейднути свої компьютери. Причина - штучний інтелект! Дата-центри, що навчають і запускають великі мовні моделі, поглинають пам'ять мільярдами гігабайт. Память стала стратегичним ресурсом цифрової епохи - як нафта у ХХ столітті!
Мабуть на цьому місці уважний читач подумає "... ну ти і Капітан Очевидність" і буде правий, з усіми ціми пампами та дампами крипторинку я взагалі випав з звичайного життя.
І це змусило мене задуматися глибше: а що саме означає "пам'ять" для ШІ? Не просто гігабайти на платі, а щось значно тонше - здатність зберігати контекст, розуміти зв'язки між поняттями, "пам'ятати" не факти, а сенси. Саме тут на сцену виходить концепція семантичної пам'яті - і саме її реалізував на рівні інфраструктури AI-native блокчейн @Vanarchain через свій перший шар інтелекту myNeutron.
Почну з загальної проблеми AI-агентів під назвою "амнезія"
Кожен чат з ChatGPT, Claude чи Gemini - як нова зустріч. Контекст зникає після сесії. Документи, нотатки, попередні рішення - все треба пояснювати заново.
Для простої розмови - терпимо.
Для AI-агента, який аналізує RWA, веде переговори або керує проєктом - це вже не незручність, а фундаментальне обмеження.
Off-chain векторні бази на кшталт Pinecone чи Weaviate намагаються вирішити цю проблему: зберігають embeddings, дозволяють семантичний пошук. Але це надбудова поверх системи, яка не була для цього створена. Дані не персистентні на блокчейні, контекст губиться при перемиканні між інструментами, верифікація відсутня, цілісне бачення втрачається, питання приватності відкрите.
Для мене це замкнуте коло виглядає саме так:
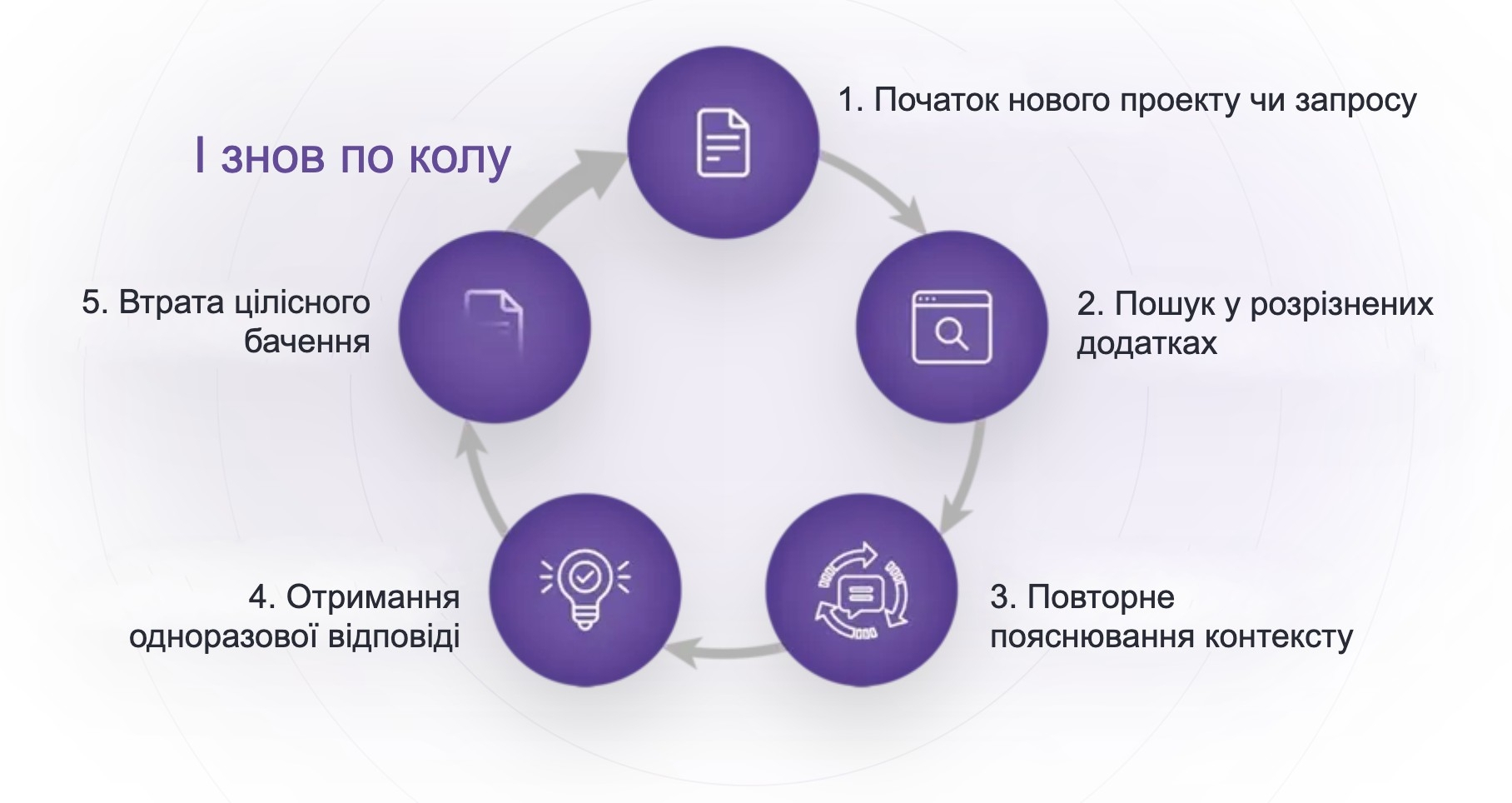
Записник, який ви постійно забуваєте вдома, - не пам'ять!
І ось тут з'является головний герой мого посту, myNeutron.
myNeutron - перший споживчий продукт на базі Neutron, семантичного шару Vanar. За даними команди проєкту, він був запущений у жовтні 2025 року і вже працює в реальному використанні.
Працює це так:
Завантажуєш файли - PDF, нотатки, чати, веб-сторінки - одним кліком через Chrome extension. AI автоматично тегає і витягує не просто текст, а зв'язки між поняттями. Результат стискається в Seeds - які зберігають сенс, а не байти. Заявлений командою коефіціент стиснення до 500:1 через комбінацію neural та algorithmic підходів.
Seeds портуються. Інжектиш контекст у будь-який AI - ChatGPT, Claude, Grok або Gemini. Перемикаєшся між інструментами - пам'ять лишається. Семантичний пошук працює на запитах звичаними людськими мовами з citation джерел; заявлена швидкість відповіді - до 200ms (дані проєкту).
І, як на мене, головне: Seeds можна заанкорити на Vanar Chain. Персистентно, верифіковано, з підтвердженою власністю. Дані не зникають разом із сесією або сервісом.
Чому це важливо?
Чесно кажучи, мене дратує, коли дехто кажє "... ми маємо AI memory", а на ділі - тимчасовий кеш у додатку, який скидається при перезапуску.
myNeutron показує інше: portable, persistent, on-chain ready. Агенти не перезапускаються - вони продовжують з того місця, де зупинились. Це не теорія - це працює вже зараз.
При цьому $VANRY використовується для оплати compression, storage та запитів у мережі - так токен інтегрований у реальне використання інфратсруктури, а не існує окремо від продукту.
Ця тема "зачепила" мене, тому завтра продовжу про Kayon: чому он-чейн міркування з пояснюванністю - це наступний крок після пам'яті.
Залишайтеся на зв'язку! #Vanar