
Am 16. März 2026 wird die NVIDIA GTC 2026 Konferenz offiziell eröffnet, und der Gründer und CEO von NVIDIA, Jensen Huang, hält die Eröffnungsrede.
Auf dieser Konferenz, die als "Jahres-Pilgerfahrt der KI-Branche" angesehen wird, erläuterte Jensen Huang die Transformation von NVIDIA von einem "Chip-Unternehmen" zu einem "AI-Infrastruktur- und Fabrikunternehmen". Angesichts der von den Märkten am meisten besorgten Fragen zur Nachhaltigkeit der Leistung und zum Wachstumspotenzial erklärte Jensen Huang detailliert die zugrunde liegende Geschäftslogik, die zukünftiges Wachstum antreibt – "Token Fabrik Ökonomie".

Die Leistungsaussichten sind äußerst optimistisch, "mindestens 10 Billionen Dollar Nachfrage bis 2027"
In den letzten zwei Jahren ist die weltweite Nachfrage nach KI-Computing exponentiell gestiegen. Mit der Weiterentwicklung großer Modelle von „Wahrnehmung“ und „Generierung“ hin zu „Schlussfolgerung“ und „Aktion (Aufgabenausführung)“ hat der Bedarf an Rechenleistung sprunghaft zugenommen. Huang Renxun äußerte sich hinsichtlich der Auftrags- und Umsatzobergrenzen, die den Markt stark beschäftigen, äußerst optimistisch.
In seiner Rede erklärte Huang Renxun unumwunden:
Etwa um diese Zeit im letzten Jahr sagte ich, wir sähen eine Nachfrage von 500 Milliarden Dollar mit hohem Vertrauen, die Blackwell und Rubin bis 2026 abdecken würde. Jetzt, genau hier und jetzt, sehe ich eine Nachfrage von mindestens 1 Billion Dollar bis 2027.
Jensen Huangs Billionen-Dollar-Erwartung ließ den Aktienkurs von Nvidia einst um mehr als 4,3 % steigen.
Darüber hinaus fügte er dieser Zahl hinzu:
Ist das realistisch? Genau darüber werde ich als Nächstes sprechen. Tatsächlich könnte es sogar zu Lieferengpässen kommen. Ich bin mir sicher, dass der tatsächliche Bedarf an Rechenleistung deutlich höher sein wird.
Jensen Huang wies darauf hin, dass sich die Systeme von Nvidia mittlerweile als die weltweit „kostengünstigste Infrastruktur“ erwiesen haben. Da Nvidia KI-Modelle in praktisch jedem Bereich ausführen kann, ermöglicht diese Vielseitigkeit, dass die von den Kunden investierten 1 Billion Dollar voll ausgeschöpft werden und eine lange Lebensdauer erhalten bleibt.
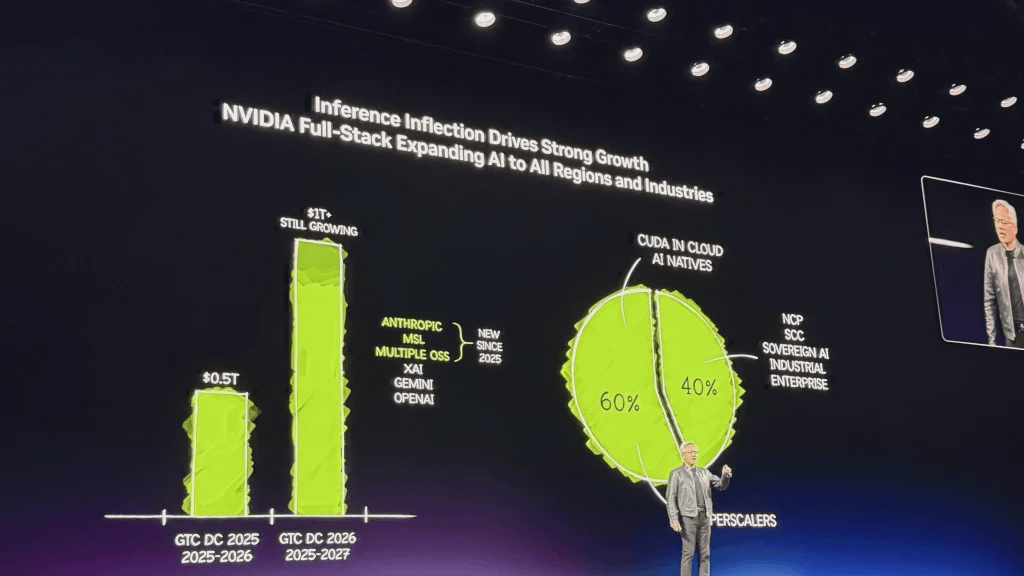
Derzeit stammen 60 % des Geschäfts von Nvidia von den fünf größten Hyperscale-Cloud-Service-Anbietern, während die restlichen 40 % breit über verschiedene Bereiche wie Sovereign Cloud, Enterprise, Industrie, Robotik und Edge Computing verteilt sind.
Token-Fabrik-Ökonomie: Die Leistung pro Watt bestimmt die Überlebensfähigkeit des Unternehmens.
Um die Gründe für diese Billionen-Dollar-Nachfrage zu erläutern, präsentierte Jensen Huang den CEOs globaler Unternehmen ein völlig neues Geschäftsmodell. Er wies darauf hin, dass zukünftige Rechenzentren keine Lagerhäuser mehr zur Speicherung von Dateien sein werden, sondern vielmehr „Fabriken“ zur Produktion von Token (den von KI generierten Grundeinheiten).

Huang Renxun betonte:
Jedes Rechenzentrum und jede Fabrik ist definitionsgemäß leistungsmäßig begrenzt. Eine Fabrik mit 1 GW Leistung wird niemals auf 2 GW erweitert; das ist ein physikalisches Gesetz. Bei einer festen Leistungsaufnahme hat derjenige die niedrigsten Produktionskosten, der den höchsten Durchsatz pro Watt erzielt.
Jensen Huang unterteilt zukünftige KI-Dienstleistungen in vier Geschäftsebenen:
Kostenloses Tarifpaket (hoher Durchsatz, niedrige Geschwindigkeit)
Mittlere Stufe (~3 US-Dollar pro Million Token)
Fortgeschrittene Stufe (ca. 6 US-Dollar pro Million Token)
Hochgeschwindigkeitsschicht (~45 $ pro Million Token)
Ultraschnelle Transaktionsschicht (~150 US-Dollar pro Million Token)
Er wies darauf hin, dass KI mit zunehmender Größe der Modelle und Länge der Kontexte zwar intelligenter werde, die Token-Generierungsrate jedoch sinke. Jensen Huang erklärte:
In dieser Token-Fabrik werden Ihr Durchsatz und Ihre Token-Generierungsgeschwindigkeit direkt in Ihr genaues Einkommen im nächsten Jahr umgerechnet.
Jensen Huang betonte, dass die Architektur von NVIDIA es den Kunden ermöglicht, im kostenlosen Tarif einen extrem hohen Durchsatz zu erzielen und gleichzeitig die Leistung im Inferenztarif mit dem höchsten Wert um das 35-fache zu steigern.
Vera Rubin erzielt eine 350-fache Beschleunigung in zwei Jahren; Groq schließt die Lücke im Bereich ultraschneller Schlussfolgerungen.
Unter Berücksichtigung dieser physikalischen Grenzen stellte NVIDIA Vera Rubin vor, sein bisher komplexestes KI-Rechensystem. Jensen Huang erklärte:
Früher, wenn ich Hopper erwähnte, hielt ich immer einen Chip hoch, was ganz nett war. Aber als ich Vera Rubin erwähnte, dachten die Leute sofort an das gesamte System. In diesem vollständig flüssigkeitsgekühlten System, das komplett ohne herkömmliche Kabel auskommt, lässt sich ein Rack, dessen Aufbau früher zwei Tage dauerte, jetzt in nur zwei Stunden aufbauen.
Jensen Huang wies darauf hin, dass Vera Rubin durch ein extrem durchgängiges Hardware- und Software-Co-Design einen erstaunlichen Datensprung innerhalb desselben 1-GW-Rechenzentrums erzielt hat:
Innerhalb von nur zwei Jahren haben wir die Token-Generierungsrate von 22 Millionen auf 700 Millionen erhöht – eine Steigerung um das 350-Fache. Das Mooresche Gesetz sah im gleichen Zeitraum lediglich eine Steigerung um etwa das 1,5-Fache vor.
Um Bandbreitenengpässe bei extrem schnellen Inferenzvorgängen (z. B. 1000 Tokens/Sekunde) zu beheben, präsentierte NVIDIA seine finale Lösung durch die Integration des übernommenen Unternehmens Groq: asymmetrische, entkoppelte Inferenz. Jensen Huang erklärte:
Diese beiden Prozessoren weisen sehr unterschiedliche Merkmale auf. Der Groq-Chip verfügt über 500 MB SRAM, während ein Rubin-Chip 288 GB Speicher besitzt.

Jensen Huang wies darauf hin, dass NVIDIA über sein Dynamo-Softwaresystem die rechen- und speicherintensive „Vorfüllphase“ an Vera Rubin und die latenzkritische „Dekodierungsphase“ an Groq delegiert. Huang gab außerdem Empfehlungen zur Konfiguration der Rechenleistung in Unternehmen:
Wenn Ihre Arbeit hauptsächlich auf hohen Durchsatz ausgelegt ist, nutzen Sie Vera Rubin zu 100 %; wenn Sie einen großen Bedarf an der Generierung hochwertiger Token auf programmatischer Ebene haben, weisen Sie 25 % Ihres Rechenzentrumsplatzes Groq zu.
Es wurde bekannt, dass der von Samsung hergestellte Groq LP30-Chip bereits in Massenproduktion ist und voraussichtlich im dritten Quartal ausgeliefert wird, während das erste Vera Rubin-Rack bereits in der Microsoft Azure-Cloud läuft.
Darüber hinaus präsentierte Jensen Huang im Bereich der optischen Verbindungstechnologie den weltweit ersten in Serie gefertigten, gemeinsam verpackten optischen (CPO) Schalter Spectrum X und beruhigte damit die Marktdebatte über den Ansatz „Kupfer raus, Glasfaser rein“.
Wir benötigen mehr Produktionskapazitäten für Kupferkabel, mehr Produktionskapazitäten für optische Chips und mehr Produktionskapazitäten für CPO.
Agenten verdrängen das traditionelle SaaS-Modell; „Jahresgehalt + Token“ ist im Silicon Valley zum Standard geworden.
Neben den Hardware-Barrieren widmete Huang einen bedeutenden Teil seiner Ausführungen der Revolution in der KI-Software und den dazugehörigen Ökosystemen, insbesondere dem Aufkommen von Agenten.
Er bezeichnete das Open-Source-Projekt OpenClaw als „das populärste Open-Source-Projekt der Menschheitsgeschichte“ und sagte, es habe die Erfolge von Linux in den letzten 30 Jahren in nur wenigen Wochen übertroffen. Huang erklärte unmissverständlich, OpenClaw sei im Wesentlichen ein „Betriebssystem“ für automatisierte Computer.
Huang Renxun behauptete:
Jedes SaaS-Unternehmen (Software as a Service) wird sich zu einem AaaS-Unternehmen (Agent as a Service) entwickeln. Um den sicheren Einsatz dieser Agenten zu gewährleisten, die auf sensible Daten zugreifen und Code ausführen können, hat NVIDIA das Referenzdesign NeMo Claw für Unternehmen vorgestellt, das eine Richtlinien-Engine und einen Datenschutz-Router umfasst.
Für Berufstätige steht dieser Wandel ebenfalls unmittelbar bevor. Jensen Huang skizziert eine neue Form des Arbeitsplatzes der Zukunft:
Zukünftig benötigt jeder Ingenieur in unserem Unternehmen ein jährliches Token-Budget. Sein Jahresgrundgehalt beträgt möglicherweise mehrere Hunderttausend Dollar, und ich werde etwa die Hälfte davon als Token-Zuteilung bereitstellen, um ihm eine zehnfache Effizienzsteigerung zu ermöglichen. Dies ist bereits die neue Einstellungstaktik im Silicon Valley: Wie viele Token beinhaltet Ihr Angebot?
Am Ende seiner Rede gab Jensen Huang einen ersten Einblick in die Feynman-Architektur der nächsten Generation, die als erste die horizontale Skalierung von Kupferleitungen und CPO ermöglichen wird. Noch faszinierender ist Nvidias Entwicklung von „Vera Rubin Space-1“, einem im Weltraum eingesetzten Rechenzentrumscomputer, der völlig neue Möglichkeiten für die Erweiterung der KI-Rechenleistung über die Erde hinaus eröffnet.
Der vollständige Text der Rede von Jensen Huang auf der GTC 2026, übersetzt (mit Hilfe eines KI-Tools):
Moderator: Begrüßen Sie Jensen Huang, Gründer und CEO von Nvidia, auf der Bühne.
Jensen Huang, Gründer und CEO:
Willkommen bei der GTC. Ich möchte alle daran erinnern, dass dies eine Technologiekonferenz ist. Es freut mich sehr, so viele Menschen so früh am Morgen in der Schlange stehen zu sehen und alle heute hier zu begrüßen.
Auf der GTC konzentrieren wir uns auf drei Hauptthemen: Technologie, Plattformen und Ökosystem. NVIDIA bietet derzeit drei Hauptplattformen an: die CUDA-X-Plattform, die Systemplattform und unsere neu eingeführte AI Factory-Plattform.
Bevor wir offiziell beginnen, möchte ich mich bei unseren Moderatoren der Vorberichterstattung bedanken: Sarah Guo von Conviction, Alfred Lin von Sequoia Capital (Nvidias erstem Risikokapitalgeber) und Gavin Baker, Nvidias erstem großen institutionellen Investor. Diese drei verfügen über profunde Technologiekenntnisse und üben erheblichen Einfluss im gesamten Technologie-Ökosystem aus. Selbstverständlich möchte ich mich auch bei allen hochkarätigen Gästen bedanken, die ich persönlich eingeladen habe. Ein großes Dankeschön an dieses herausragende Team!
Ich möchte mich auch bei allen heute anwesenden Unternehmen bedanken. NVIDIA ist ein Plattformunternehmen; wir verfügen über Technologie, Plattformen und ein umfassendes Ökosystem. Die heute anwesenden Unternehmen repräsentieren nahezu alle Akteure der 100 Billionen Dollar schweren Branche, und wir sind den 450 Unternehmen, die diese Veranstaltung gesponsert haben, zutiefst dankbar.
Diese Konferenz wird 1.000 technische Foren und 2.000 Redner umfassen, die jede Ebene der „fünfschichtigen Kuchen“-Architektur der künstlichen Intelligenz abdecken – von der Infrastruktur wie Land, Strom und Rechenzentren bis hin zu Chips, Plattformen, Modellen und den verschiedenen Anwendungen, die letztendlich die gesamte Branche vorantreiben.
CUDA: Zwanzig Jahre technologischer Akkumulation
Hier hat alles angefangen. Dieses Jahr feiert CUDA sein 20-jähriges Bestehen.
Seit zwei Jahrzehnten widmen wir uns der Entwicklung dieser Architektur. CUDA ist eine revolutionäre Erfindung: Die SIMT-Technologie (Single Instruction, Multithreaded) ermöglicht es Entwicklern, Programme in skalarem Code zu schreiben und sie zu Multithread-Anwendungen zu erweitern. Dadurch ist die Programmierung deutlich einfacher als mit der vorherigen SIMD-Architektur. Kürzlich haben wir Tiles hinzugefügt, um Entwicklern die Programmierung von Tensor Cores und den verschiedenen mathematischen Strukturen, auf denen die heutige künstliche Intelligenz basiert, zu erleichtern. Aktuell gibt es für CUDA Tausende von Tools, Compilern, Frameworks und Bibliotheken, Hunderttausende von öffentlichen Projekten in der Open-Source-Community und es ist tief in jedes Technologie-Ökosystem integriert.
Dieses Diagramm verdeutlicht die strategische Logik von NVIDIA vollständig, und ich präsentiere diese Folie von Anfang an. Das schwierigste und wichtigste Ziel ist die Anzahl der installierten Systeme am unteren Rand des Diagramms. In den letzten zwei Jahrzehnten haben wir weltweit Hunderte Millionen GPUs und Computersysteme mit CUDA im Einsatz.
Unsere GPUs decken alle Cloud-Plattformen ab und bedienen nahezu alle Computerhersteller und Branchen. Die enorme installierte Basis von CUDA ist der Hauptgrund für dieses stetige Wachstum. Diese installierte Basis zieht Entwickler an, die wiederum neue Algorithmen entwickeln und bahnbrechende Innovationen erzielen. Diese Innovationen schaffen neue Märkte, neue Märkte bilden neue Ökosysteme und ziehen weitere Unternehmen an, wodurch die installierte Basis weiter wächst – dieser Kreislauf beschleunigt sich kontinuierlich.
Die Downloads von NVIDIA-Bibliotheken wachsen rasant, in großem Umfang und mit stetig steigender Geschwindigkeit. Dieser positive Kreislauf ermöglicht es unserer Computerplattform, eine Vielzahl von Anwendungen und einen kontinuierlichen Strom neuer Innovationen zu unterstützen.
Noch wichtiger ist jedoch die extrem lange Lebensdauer dieser Infrastrukturen. Der Grund dafür liegt auf der Hand: Die auf NVIDIA CUDA lauffähigen Anwendungen sind unglaublich vielfältig und decken alle Phasen des KI-Lebenszyklus, verschiedene Datenverarbeitungsplattformen und ein breites Spektrum wissenschaftlicher Solver ab. Daher ist der praktische Nutzen einer einmal installierten NVIDIA-GPU extrem hoch. Aus diesem Grund ist der Cloud-Preis unserer vor sechs Jahren eingeführten Ampere-Architektur-GPUs sogar gestiegen.
Die Ursache dafür liegt in unserer großen installierten Basis, der leistungsstarken Flywheel-Architektur und unserem umfangreichen Entwickler-Ökosystem. Wenn diese Faktoren zusammenwirken, zusammen mit unseren kontinuierlichen Software-Updates, sinken die Rechenkosten stetig. Beschleunigtes Rechnen verbessert die Anwendungsleistung deutlich, und dank unserer langfristigen Wartung und Weiterentwicklung der Software profitieren Nutzer nicht nur von anfänglichen Leistungssprüngen, sondern auch von dauerhaft reduzierten Rechenkosten. Wir bieten weltweit langfristigen Support für jede GPU, da diese architektonisch kompatibel sind.
Wir sind aufgrund der enormen Anzahl an Installationen dazu bereit – jede neue Optimierungsversion kommt Millionen von Nutzern zugute. Diese dynamische Kombination ermöglicht es NVIDIA-Architekturen, ihre Reichweite kontinuierlich zu erweitern und ihr eigenes Wachstum zu beschleunigen, während gleichzeitig die Rechenkosten gesenkt werden, was letztendlich neues Wachstum anregt. CUDA ist dabei das Herzstück.
Von GeForce zu CUDA: Eine 25-jährige Entwicklung
Unsere Reise mit CUDA begann eigentlich vor 25 Jahren.
GeForce – viele von Ihnen sind mit GeForce aufgewachsen. GeForce ist NVIDIAs erfolgreichstes Marketingprogramm. Wir begannen mit der Gewinnung zukünftiger Kunden, als Sie sich unsere Produkte noch nicht leisten konnten – Ihre Eltern wurden zu den ersten NVIDIA-Nutzern und kauften unsere Produkte Jahr für Jahr, bis Sie eines Tages zu exzellenten Informatikern heranwuchsen und zu echten Kunden und Entwicklern wurden.
Dies ist das Fundament, das GeForce vor 25 Jahren gelegt hat. Vor 25 Jahren erfanden wir den programmierbaren Shader – eine ebenso naheliegende wie bahnbrechende Erfindung, die Beschleuniger programmierbar machte, und den weltweit ersten programmierbaren Beschleuniger, den Pixel-Shader. Fünf Jahre später entwickelten wir CUDA – eine unserer wichtigsten Investitionen überhaupt. Mit begrenzten Ressourcen investierten wir den Großteil unserer Gewinne in die Verbreitung von CUDA von GeForce auf jeden Computer. Wir waren so entschlossen, weil wir an sein Potenzial glaubten. Trotz anfänglicher Schwierigkeiten hielt das Unternehmen 13 Generationen lang, ganze zwei Jahrzehnte, an diesem Glauben fest, und heute ist CUDA allgegenwärtig.
Es war der Pixel-Shader, der die GeForce-Revolution auslöste. Vor etwa acht Jahren stellten wir RTX vor – eine grundlegende architektonische Überarbeitung für das moderne Zeitalter der Computergrafik. GeForce brachte CUDA in die Welt, und dank ihm erkannten viele Wissenschaftler, darunter Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton und Andrew Ng, dass GPUs ein leistungsstarkes Werkzeug zur Beschleunigung von Deep Learning sein konnten und lösten damit vor einem Jahrzehnt den KI-Boom aus.
Vor zehn Jahren beschlossen wir, programmierbares Shading mit zwei völlig neuen Konzepten zu kombinieren: Hardware-Raytracing, das technisch extrem anspruchsvoll war, und einer damals zukunftsweisenden Idee – wir sahen bereits vor etwa einem Jahrzehnt voraus, dass KI die Computergrafik revolutionieren würde. So wie GeForce die KI in die Welt gebracht hat, wird KI nun ihrerseits die Implementierung von Computergrafik grundlegend verändern.
Heute zeige ich Ihnen die Zukunft. Dies ist unsere Grafiktechnologie der nächsten Generation, die wir Neural Rendering nennen – eine tiefgreifende Verschmelzung von 3D-Grafik und künstlicher Intelligenz. Das ist DLSS 5, sehen Sie selbst.
Neuronales Rendering: Die Verschmelzung von strukturierten Daten und generativer KI
Ist das nicht atemberaubend? Computergrafiken sind zum Leben erwacht.
Was haben wir gemacht? Wir haben steuerbare 3D-Grafiken (das eigentliche Fundament der virtuellen Welt) mit ihren strukturierten Daten kombiniert und anschließend generative KI und probabilistische Berechnungen integriert. Das eine ist vollständig deterministisch, das andere probabilistisch und dennoch hochrealistisch – wir haben diese beiden Konzepte vereint und so durch strukturierte Daten eine präzise Steuerung erreicht, während gleichzeitig Inhalte in Echtzeit generiert werden. Das Ergebnis sind visuell beeindruckende und vollständig steuerbare Inhalte.
Das Konzept der Integration strukturierter Informationen in generative KI wird sich in verschiedenen Branchen weiter verbreiten. Strukturierte Daten sind die Grundlage für vertrauenswürdige KI.
Beschleunigungsplattform für strukturierte und unstrukturierte Daten
Nun zeige ich Ihnen ein technisches Architekturdiagramm.
Strukturierte Daten – verarbeitet von bekannten Plattformen wie SQL, Spark, Pandas und Velox sowie wichtigen Plattformen wie Snowflake, Databricks, Amazon EMR, Azure Fabric und Google BigQuery – basieren auf Dataframes. Diese Dataframes sind wie riesige Tabellenkalkulationen, die alle Informationen der Geschäftswelt enthalten und die Grundlage der Unternehmens-IT bilden.
Im Zeitalter der KI müssen wir KI befähigen, strukturierte Daten zu nutzen und deren Verarbeitung extrem zu beschleunigen. In der Vergangenheit diente die Beschleunigung der Verarbeitung strukturierter Daten dazu, die Effizienz von Unternehmen zu steigern. Zukünftig wird KI diese Datenstrukturen weit schneller nutzen als der Mensch, und KI-Systeme werden strukturierte Datenbanken umfassend verwenden.
Im Bereich unstrukturierter Daten stellen Vektordatenbanken, PDFs, Videos und Audiodateien weltweit den Großteil der Datenformate dar – etwa 90 % der jährlich generierten Daten sind unstrukturiert. Früher waren diese Daten nahezu unbrauchbar: Wir lasen sie, speicherten sie in Dateisystemen, und das war’s. Wir konnten sie nicht abfragen, und es war schwierig, Daten abzurufen, da unstrukturierten Daten einfache Indexierungsmethoden fehlten; wir mussten ihre Bedeutung und ihren Kontext verstehen. Heute kann KI dies leisten – mithilfe multimodaler Wahrnehmungs- und Verarbeitungstechnologien kann KI PDF-Dokumente lesen, ihre Bedeutung verstehen und sie in eine größere, abfragefähige Struktur einbetten.
Nvidia hat zu diesem Zweck zwei Basisbibliotheken erstellt:
cuDF: Wird zur beschleunigten Verarbeitung von Dataframes und strukturierten Daten verwendet.
cuVS: Wird zur Vektorspeicherung, semantischen Daten und zur Verarbeitung unstrukturierter KI-Daten verwendet.
Diese beiden Plattformen werden in Zukunft zu einer der wichtigsten grundlegenden Plattformen werden.
Heute haben wir Partnerschaften mit mehreren Unternehmen bekanntgegeben. IBM – der Erfinder der SQL-Sprache – wird cuDF nutzen, um seine WatsonX-Datenplattform zu beschleunigen. Dell hat sich mit uns zusammengetan, um die Dell AI Data Platform zu entwickeln, die cuDF und cuVS integriert, und konnte in realen Projekten bei NTT Data deutliche Leistungsverbesserungen erzielen. Auf Google Cloud-Seite beschleunigen wir nun nicht nur Vertex AI, sondern auch BigQuery und haben eine Partnerschaft mit Snapchat geschlossen, um dessen Rechenkosten um fast 80 % zu senken.
Die Vorteile von beschleunigtem Rechnen sind dreifach: Geschwindigkeit, Skalierbarkeit und Kosten. Dies entspricht der Logik des Mooreschen Gesetzes – durch beschleunigtes Rechnen werden Leistungssprünge erzielt, während gleichzeitig Algorithmen kontinuierlich optimiert werden, sodass alle von stetig sinkenden Rechenkosten profitieren können.
NVIDIA hat eine beschleunigte Rechenplattform entwickelt, die zahlreiche Bibliotheken, darunter RTX, cuDF und cuVS, vereint. Diese Bibliotheken sind in globale Cloud-Dienste und OEM-Netzwerke integriert und erreichen so Nutzer weltweit.
Enge Zusammenarbeit mit Cloud-Service-Anbietern
Partnerschaften mit großen Cloud-Service-Anbietern
Google Cloud: Wir beschleunigen Vertex AI und BigQuery, integrieren JAX/XLA nahtlos und sind führend in PyTorch – NVIDIA ist weltweit der einzige Beschleuniger, der sowohl PyTorch als auch JAX/XLA optimal unterstützt. Wir haben Kunden wie Base10, CrowdStrike, Puma und Salesforce in das Google Cloud-Ökosystem integriert.
AWS: Wir beschleunigen die Entwicklung von EMR, SageMaker und Bedrock, die eng mit AWS integriert sind. Besonders freut mich in diesem Jahr die Integration von OpenAI in AWS. Dies wird das Wachstum der AWS-Cloud-Computing-Nutzung deutlich ankurbeln und OpenAI dabei helfen, seine regionalen Bereitstellungen und Rechenkapazitäten auszubauen.
Microsoft Azure: Der NVIDIA-Supercomputer mit 100 PFLOPS ist der erste von uns entwickelte und auf Azure bereitgestellte Supercomputer und bildet eine wichtige Grundlage für unsere Zusammenarbeit mit OpenAI. Wir beschleunigen die Entwicklung von Azure-Cloud-Diensten und AI Foundry, arbeiten gemeinsam an der regionalen Erweiterung von Azure und intensiv an der Bing-Suche. Unsere **Confidential Computing**-Funktionen – die gewährleisten, dass selbst Mobilfunkanbieter keinen Zugriff auf Nutzerdaten und -modelle haben – machen NVIDIA-GPUs zu den weltweit ersten, die Confidential Computing unterstützen. Dies ermöglicht die sichere Bereitstellung von OpenAI- und Anthropic-Modellen in Cloud-Umgebungen weltweit. Beispielsweise haben wir gemeinsam mit Synopsys die gesamten EDA- und CAD-Workflows beschleunigt und auf Microsoft Azure bereitgestellt.
Oracle: Wir waren Oracles erster KI-Kunde, und ich bin stolz darauf, als Erster das Konzept der KI-Cloud Oracle erläutert zu haben. Seitdem ist das Unternehmen rasant gewachsen, und wir haben zahlreiche Partner für Oracle gewonnen, darunter Cohere, Fireworks und OpenAI.
CoreWeave: Die weltweit erste KI-native Cloud, die speziell für GPU-Hosting und KI-Cloud-Dienste entwickelt wurde, verfügt über einen hervorragenden Kundenstamm und eine starke Wachstumsdynamik.
Palantir + Dell: Die drei Parteien haben gemeinsam eine brandneue KI-Plattform auf Basis der Ontology Platform und der AI Platform von Palantir entwickelt, die KI in jedem Land und in jeder abgeschotteten Umgebung vollständig lokalisiert einsetzen kann – von der Datenverarbeitung (Vektorisierung oder Strukturierung) bis hin zum kompletten beschleunigten Rechenstack für KI.
NVIDIA hat diese besondere Partnerschaft mit globalen Cloud-Service-Anbietern aufgebaut – wir bringen Kunden in die Cloud und schaffen so ein für alle Seiten vorteilhaftes Ökosystem.
Vertikale Integration, horizontale Offenheit: Nvidias Kernstrategie
Nvidia ist das weltweit erste vertikal integrierte und horizontal offene Unternehmen.
Die Notwendigkeit dieses Modells ist ganz einfach: Beschleunigtes Rechnen ist weder eine Frage der Chips noch des Systems; die vollständige Beschreibung lautet Anwendungsbeschleunigung. CPUs können Computer zwar insgesamt schneller machen, aber dieser Weg ist an seine Grenzen gestoßen. Zukünftig können nur noch anwendungs- oder domänenspezifische Beschleunigungen Leistungssprünge und Kostensenkungen ermöglichen.
Genau deshalb muss NVIDIA sich intensiv mit verschiedenen Bibliotheken, Anwendungsbereichen und Branchen auseinandersetzen. Wir sind ein vertikal integriertes IT-Unternehmen; anders geht es nicht. Wir müssen die Anwendungen, die Anwendungsbereiche und die Algorithmen genau verstehen und sie in jedem Szenario einsetzen können – in Rechenzentren, der Cloud, On-Premises-Umgebungen, am Edge und sogar in Robotersystemen.
Gleichzeitig verfolgt NVIDIA einen horizontal offenen Ansatz und ist bereit, seine Technologie in die Plattform jedes Partners zu integrieren, damit die ganze Welt in den Genuss der Vorteile beschleunigten Rechnens kommen kann.
Die Teilnehmerstruktur der diesjährigen GTC verdeutlicht dies perfekt. Die Finanzdienstleistungsbranche stellte den größten Anteil der Teilnehmer – wir hoffen, Entwickler statt Händler zu sehen. Unser Ökosystem erstreckt sich über die gesamte Wertschöpfungskette. Unabhängig davon, ob ein Unternehmen 50, 70 oder 150 Jahre alt ist, war das letzte Jahr sein erfolgreichstes überhaupt. Wir stehen am Anfang von etwas sehr Bedeutendem.
CUDA-X: Eine beschleunigte Rechenmaschine für verschiedene Branchen
Nvidia ist in verschiedenen vertikalen Sektoren stark vertreten:
Autonomes Fahren: Weitreichende und tiefgreifende Auswirkungen
Finanzdienstleistungen: Quantitatives Investieren wandelt sich von der manuellen Merkmalsentwicklung hin zum supercomputergestützten Deep Learning und erlebt damit seinen „Transformer-Moment“.
Gesundheitswesen: Ein „ChatGPT-Moment“ bricht an, der Bereiche wie KI-gestützte Wirkstoffforschung, KI-gestützte Diagnostik und Kundenservice im Gesundheitswesen umfasst.
Industrie: Die größte Bauwelle der Welt ist im Gange, überall schießen Fabriken für künstliche Intelligenz, Chipfabriken und Rechenzentrumsfabriken wie Pilze aus dem Boden.
Unterhaltung und Spiele: Die Echtzeit-KI-Plattform unterstützt Übersetzungen, Live-Streaming, Spielinteraktion und intelligente Einkaufsagenten.
Robotik: Mit über einem Jahrzehnt Erfahrung und einer kompletten Palette von drei wichtigen Computerarchitekturen (Trainingscomputer, Simulationscomputer und Bordcomputer) wurden auf dieser Ausstellung 110 Roboter präsentiert.
Telekommunikation: Eine Branche mit einem Wert von rund 2 Billionen US-Dollar. Basisstationen werden sich von reinen Kommunikationsfunktionen zu KI-Infrastrukturplattformen weiterentwickeln. Eine solche Plattform, Aerial, arbeitet eng mit Unternehmen wie Nokia und T-Mobile zusammen.
Im Zentrum all dieser Bereiche stehen unsere CUDA-X-Bibliotheken – das Fundament von NVIDIA als Algorithmenunternehmen. Diese Bibliotheken sind die wertvollsten Ressourcen des Unternehmens und ermöglichen es der Computerplattform, in verschiedenen Branchen einen echten Mehrwert zu bieten.
Eine der wichtigsten Bibliotheken ist cuDNN (CUDA Deep Neural Network Library), die die künstliche Intelligenz revolutionierte und den Boom der modernen KI auslöste.
(CUDA-X-Demovideo wird abgespielt)
Alles, was Sie gerade gesehen haben, war eine Simulation – einschließlich des physikbasierten Solvers, des KI-gestützten Physikmodells und des physikalischen KI-Robotermodells. Es handelte sich ausschließlich um Simulationen; es gab keine handgezeichneten Animationen oder Gelenk-Rigging. Genau darin liegt die Kernkompetenz von NVIDIA: diese Möglichkeiten durch ein tiefes Verständnis von Algorithmen und die nahtlose Integration von Rechenplattformen zu erschließen.
KI-native Unternehmen und das neue Computerzeitalter
Sie haben gerade Branchenriesen gesehen, die die heutige Gesellschaft prägen, wie Walmart, L'Oréal, JPMorgan Chase, Roche und Toyota, sowie eine Vielzahl von Unternehmen, von denen Sie noch nie gehört haben – sogenannte KI-native Unternehmen. Diese Liste ist sehr umfangreich und umfasst unter anderem OpenAI, Anthropic und viele aufstrebende Unternehmen, die verschiedene Branchen bedienen.
Die Branche hat in den letzten zwei Jahren ein phänomenales Wachstum erlebt. Risikokapitalinvestitionen in Startups erreichten einen Rekordwert von 150 Milliarden US-Dollar. Noch wichtiger ist, dass die Höhe einzelner Investitionen erstmals von Millionen auf Hunderte von Millionen oder sogar Milliarden US-Dollar gestiegen ist. Der Grund dafür ist einfach: Erstmals in der Geschichte benötigt jedes Unternehmen in diesem Sektor enorme Rechenressourcen und eine große Anzahl von Token. Die Branche schafft, generiert oder steigert den Wert von Token von Organisationen wie Anthropic und OpenAI.
So wie die PC-Revolution, die Internet-Revolution und die mobile Cloud-Revolution jeweils eine Reihe epochemachender Unternehmen hervorgebracht haben, wird auch diese Generation der Transformation von Computerplattformen eine Reihe hoch einflussreicher Unternehmen hervorbringen, die in der zukünftigen Welt zu einer wichtigen Kraft werden.
Drei historische Durchbrüche, die all dies ermöglichten
Was genau ist in den letzten zwei Jahren passiert? Drei wichtige Ereignisse.
Erstens: ChatGPT, das den Beginn der Ära der generativen KI einläutet (Ende 2022 bis 2023)
Es kann nicht nur wahrnehmen und verstehen, sondern auch einzigartige Inhalte generieren. Ich habe die Verschmelzung von generativer KI und Computergrafik demonstriert. Generative KI verändert grundlegend die Art und Weise, wie wir Daten verarbeiten – von der Abfrage hin zur Generierung – und hat tiefgreifende Auswirkungen auf Computerarchitektur, Bereitstellungsmethoden und die Gesamtbedeutung.
Zweitens: Logisches Denken (KI), dargestellt durch O1.
Logisches Denken ermöglicht es KI, selbstreflektiert zu arbeiten, zu planen und Probleme zu analysieren – auch solche, die sie nicht direkt versteht, werden in überschaubare Schritte zerlegt. Dadurch wirkt generative KI glaubwürdig und kann auf Basis realer Informationen schlussfolgern. Um dies zu erreichen, wird die Anzahl der Token im Eingabekontext und die Anzahl der für das logische Denken verwendeten Ausgabetoken deutlich erhöht, was die Rechenkomplexität erheblich steigert.
Drittens: Claude Code, das erste intelligente Agentenmodell.
Es kann Dateien lesen, Code schreiben, kompilieren, testen, auswerten und iterativ verbessern. Claude Code hat die Softwareentwicklung revolutioniert – 100 % der NVIDIA-Ingenieure nutzen mindestens eines von Claude Code, Codex oder Cursor; kein Softwareentwickler kommt ohne die Unterstützung von KI aus.
Dies ist ein völlig neuer Wendepunkt: Man fragt die KI nicht mehr „Was, wo und wie“, sondern lässt sie „erschaffen, ausführen und aufbauen“. Sie kann proaktiv Werkzeuge einsetzen, Dateien lesen, Probleme analysieren und Maßnahmen ergreifen. Die KI hat sich von der Wahrnehmung über die Generierung zum logischen Denken weiterentwickelt und kann nun tatsächlich Dinge erledigen.
In den letzten zwei Jahren hat sich der Rechenaufwand für Inferenz um das Zehntausendfache erhöht, während die Nutzung um das Hundertfache gestiegen ist. Ich war schon immer der Überzeugung, dass sich der Rechenaufwand in den letzten zwei Jahren millionenfach erhöht hat – diese Ansicht teilen alle, OpenAI und Anthropic. Mehr Rechenleistung führt zu mehr Token, höheren Einnahmen und intelligenterer KI. Der Wendepunkt für Inferenz ist erreicht.
Das Zeitalter der Billionen-Dollar-KI-Infrastruktur
Vor einem Jahr um diese Zeit sagte ich hier, dass wir großes Vertrauen in die Nachfrage und die Bestellungen von Blackwell und Rubin hätten, die sich bis 2026 auf rund 500 Milliarden Dollar belaufen würden. Heute, ein Jahr nach der GTC, kann ich Ihnen sagen: Mit Blick auf 2027 sehe ich die Summe bei mindestens einer Billion Dollar. Und ich bin überzeugt, dass die tatsächliche Nachfrage nach Rechenleistung weit darüber hinausgehen wird.
2025: Nvidias Jahr der Reduzierung
2025 ist das Jahr der Inferenz bei NVIDIA. Unser Ziel ist es, in jeder Phase des KI-Lebenszyklus – über das Training hinaus – Exzellenz zu gewährleisten und so sicherzustellen, dass unsere investierte Infrastruktur weiterhin effizient, mit einer längeren effektiven Lebensdauer und geringeren Stückkosten arbeitet.
Gleichzeitig traten Anthropic und Meta offiziell der NVIDIA-Plattform bei und decken zusammen ein Drittel des weltweiten Bedarfs an KI-Rechenleistung ab. Open-Source-Modelle erreichen Spitzenleistung und sind allgegenwärtig.
NVIDIA ist derzeit die weltweit einzige Plattform, die alle KI-Modelle in allen KI-Bereichen – Sprache, Biologie, Computergrafik, Computer Vision, Spracherkennung, Protein- und Chemieanalyse, Robotik usw. – ausführen kann, egal ob am Netzwerkrand oder in der Cloud und unabhängig von der Programmiersprache. Die Architektur von NVIDIA ist in all diesen Szenarien vielseitig einsetzbar und macht uns damit zur kostengünstigsten und zuverlässigsten Plattform.
Aktuell stammen 60 % des Umsatzes von NVIDIA von den fünf weltweit führenden Hyperscale-Cloud-Anbietern. Die restlichen 40 % verteilen sich auf verschiedene Bereiche wie regionale Cloud-Lösungen, Sovereign Cloud, Enterprise-Lösungen, Industrielösungen, Robotik und Edge Computing. Die breite Abdeckung von KI-Lösungen ist die Grundlage für die Widerstandsfähigkeit des Unternehmens – dies ist zweifellos eine völlig neue Revolution der Computerplattformen.
Grace Blackwell und NVLink 72: Kühne architektonische Innovation
Als die Hopper-Architektur noch ihren Höhepunkt erreichte, entschieden wir uns für eine vollständige Neugestaltung des Systems. Wir erweiterten NVLink von 8-fach auf NVLink 72 und zerlegten und rekonstruierten das gesamte Rechensystem. Die Einführung von Grace Blackwell NVLink 72 war ein großes technologisches Wagnis und für keinen unserer Partner einfach. Wir möchten allen Beteiligten unseren aufrichtigen Dank aussprechen.
Gleichzeitig haben wir NVFP4 eingeführt – nicht nur einen herkömmlichen FP4-Prozessor, sondern einen völlig neuen Tensor-Kern und eine neuartige Recheneinheit. Wir haben gezeigt, dass NVFP4 Inferenz ohne Präzisionsverlust ermöglicht und gleichzeitig deutliche Verbesserungen bei Leistung und Energieeffizienz bietet. Zudem eignet es sich gleichermaßen für das Training. Darüber hinaus sind eine Reihe neuer Algorithmen wie Dynamo und TensorRT-LLM entstanden, und wir haben sogar Milliarden von Dollar in den Bau eines Supercomputers namens DGX Cloud investiert, der speziell für die Optimierung von Kernels entwickelt wurde.
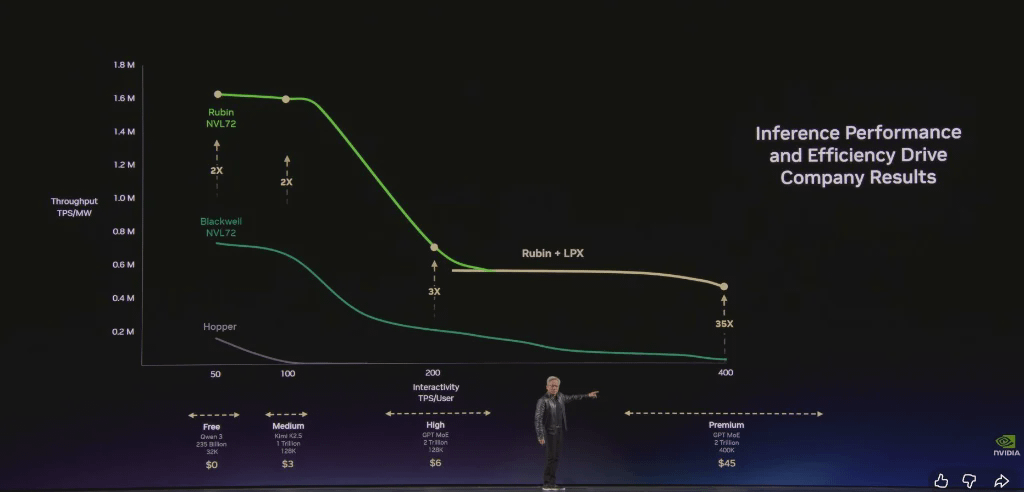
Die Ergebnisse belegen unsere herausragende Inferenzleistung. Daten von SemiAnalysis – dem bisher umfassendsten Benchmark für KI-Inferenzleistung – zeigen, dass NVIDIA sowohl bei der Token-pro-Watt-Leistung als auch bei den Kosten pro Token deutlich vorne liegt. Das Mooresche Gesetz hätte für die H200 möglicherweise eine 1,5-fache Leistungssteigerung ergeben, wir haben jedoch eine 35-fache erreicht. Dylan Patel von SemiAnalysis meinte sogar: „Huang ist vorsichtig; tatsächlich sind es 50-fach.“ Und er hat Recht.
Ich möchte ihn hier zitieren: „Jensen hat die Wahrheit verschleiert (Huang Renxun war in seiner Berichterstattung zurückhaltend).“
Nvidias Kosten pro Token sind weltweit am niedrigsten und werden derzeit von keinem anderen Unternehmen übertroffen. Der Grund dafür liegt in der Extreme Co-Design-Technologie.
Nehmen wir Fireworks als Beispiel: Bevor NVIDIA seine gesamte Software und Algorithmen aktualisierte, lag die durchschnittliche Token-Verarbeitungsgeschwindigkeit bei etwa 700 Token pro Sekunde; nach dem Update erreichte sie fast 5.000 Token pro Sekunde – eine Steigerung um das Siebenfache. Das ist die Leistungsfähigkeit optimaler kollaborativer Entwicklung.
KI-Fabrik: Vom Rechenzentrum zur Token-Fabrik
Früher dienten Rechenzentren der Dateispeicherung; heute sind sie Fabriken, die Token produzieren. Jeder Cloud-Service-Anbieter und jedes KI-Unternehmen wird die Effizienz der Tokenproduktion künftig als zentrale Kennzahl nutzen.
Das ist mein Kernargument:
Vertikale Achse: Durchsatz – Anzahl der pro Sekunde bei festem Leistungspegel generierten Token
Horizontale Achse: Token-Geschwindigkeit – die Reaktionsgeschwindigkeit pro Inferenzschritt. Je höher die Geschwindigkeit, desto größer das nutzbare Modell, desto länger der Kontext und desto intelligenter die KI.
Der Token ist ein neues Produkt, dessen Preisgestaltung nach seiner Marktreife gestaffelt sein wird.
Kostenloses Tarifpaket (hoher Durchsatz, niedrige Geschwindigkeit)
Mittlere Stufe (~3 US-Dollar pro Million Token)
Fortgeschrittene Stufe (ca. 6 US-Dollar pro Million Token)
Hochgeschwindigkeitsschicht (~45 $ pro Million Token)
Ultraschnelle Transaktionsschicht (~150 US-Dollar pro Million Token)
Im Vergleich zu Hopper bietet Grace Blackwell einen 35-fach höheren Durchsatz in der höchsten Leistungsstufe und führt völlig neue Leistungsstufen ein. Mit einem vereinfachten Modell, das 25 % der Leistung auf die vier Leistungsstufen verteilt, könnte Grace Blackwell den fünffachen Umsatz von Hopper generieren.
Vera Rubin: Das KI-Computersystem der nächsten Generation
(Es wird ein Video zur Einführung des Vera-Rubin-Systems abgespielt)
Vera Rubin ist ein vollständiges, durchgängig optimiertes System, das speziell für agentenbasierte Workloads entwickelt wurde:
Kern für die Berechnung des groß angelegten Sprachmodells: NVLink 72 GPU-Cluster, zuständig für das Vorbefüllen und den Schlüssel-Wert-Cache.
Die brandneue Vera-CPU: Entwickelt für extrem hohe Single-Thread-Leistung, nutzt sie LPDDR5-Speicher und zeichnet sich durch außergewöhnliche Energieeffizienz aus. Sie ist die weltweit einzige Rechenzentrums-CPU mit LPDDR5 und somit ideal für KI-gestützte Anwendungen.
Speichersystem: BlueField 4 + CX 9, eine brandneue Speicherplattform für das KI-Zeitalter mit 100% globaler Beteiligung in der Speicherindustrie.
CPO Spectrum X Switch: Der weltweit erste optische Ethernet-Switch in einem einzigen Gehäuse, jetzt in Serienproduktion.
Kyber Rack: Ein brandneues Rack-System, das 144 GPUs unterstützt, die eine einzige NVLink-Domäne bilden, mit Front-End-Computing und Back-End-NVLink-Switching, wodurch ein Supercomputer entsteht.
Rubin Ultra: Ein Supercomputer-Knoten der nächsten Generation mit vertikal steckbarem Design, kompatibel mit Kyber-Racks und Unterstützung für NVLink-Verbindungen im größeren Maßstab.
Vera Rubin ist jetzt vollständig flüssigkeitsgekühlt, wodurch sich die Installationszeit von zwei Tagen auf zwei Stunden verkürzt. Die Kühlung erfolgt mit 45 °C warmem Wasser, was die Kühllast in Rechenzentren deutlich reduziert. Ich freue mich sehr, dass Satya Nadella bestätigt hat, dass das erste Vera-Rubin-Rack nun auf Microsoft Azure läuft.
Groq-Integration: Die ultimative Erweiterung der Inferenzleistung
Wir haben das Groq-Team übernommen und eine Technologielizenz erworben. Groq ist ein deterministischer Datenflussprozessor, der statische Kompilierung und Compiler-Scheduling nutzt, über viel SRAM verfügt, für einzelne Inferenz-Workloads optimiert ist und sich durch extrem niedrige Latenz und extrem hohe Token-Generierungsgeschwindigkeit auszeichnet.
Die begrenzte Speicherkapazität von Groq (500 MB On-Chip-SRAM) erschwert jedoch die unabhängige Verwaltung der Parameter und des KV-Caches großer Modelle und schränkt somit den großflächigen Einsatz ein.
Die Lösung ist Dynamo – eine Software zur Inferenzplanung. Wir verwenden Dynamo, um die Inferenzpipeline aufzuteilen:
Das Vorbefüllen und die Dekodierung des Aufmerksamkeitsmechanismus werden auf Vera Rubin durchgeführt (was erhebliche Rechenleistung und KV-Cache-Speicher erfordert).
Die Dekodierung des Feedforward-Netzwerks bzw. die Token-Generierung erfolgt auf Groq (was eine extrem hohe Bandbreite und geringe Latenz erfordert).
Die beiden Systeme sind über Ethernet eng miteinander verbunden, und ein spezieller Modus halbiert die Latenz. Dank der einheitlichen Ablaufplanung von Dynamo, dem „Betriebssystem für KI-Fabriken“, verbessert sich die Gesamtleistung um das 35-Fache, und eine neue, mit NVLink 72 bisher unerreichte Inferenzleistung wird ermöglicht.
Kombinationsempfehlungen für Groq und Vera Rubin:
Bei Arbeitslasten mit überwiegend hohem Durchsatz verwenden Sie 100% Vera Rubin.
Wenn ein großer Teil der Arbeitslast die Generierung hochwertiger Token wie Code beinhaltet, kann Groq eingeführt werden, wobei ein Verhältnis von etwa 25 % Groq + 75 % Vera Rubin empfohlen wird.
Das Groq LP30 wird von Samsung hergestellt und befindet sich derzeit in Serienproduktion; die Auslieferung wird voraussichtlich im dritten Quartal beginnen. Vielen Dank an Samsung für die hervorragende Zusammenarbeit.
Ein historischer Sprung in der Denkleistung
Quantifizierung bisheriger technologischer Fortschritte: Innerhalb von zwei Jahren wird die Token-Generierungsrate einer 1-Gigawatt-KI-Fabrik von 22 Millionen Token pro Sekunde auf 700 Millionen Token pro Sekunde steigen – eine Steigerung um das 350-Fache. Das ist die Macht ultimativer kollaborativer Entwicklung.
Technologie-Roadmap
Blackwell: Aktuell in Produktion, Oberon Standard-Racksystem, Kupferverkabelung bis NVLink 72 erweitert, optionale optische Erweiterung bis NVLink 576.
Vera Rubin (aktuell): Kyber Rack, NVLink 144 (Kupferkabel); Oberon Rack, NVLink 72 + optisch, erweitert auf NVLink 576; Spectrum 6, der weltweit erste CPO-Switch.
Vera Rubin Ultra (demnächst erhältlich): Die nächste Generation der Rubin Ultra GPU, der LP35-Chip (erstmals mit NVFP4-Integration), steigert die Leistung um ein Vielfaches.
Feynman (nächste Generation): Eine brandneue GPU, der LP40-Chip (gemeinsam entwickelt von NVIDIA und dem Groq-Team, mit NVFP4); eine brandneue CPU – Rosa (Rosalyn); BlueField 5; CX 10; und Kyber-Racks, die sowohl Kupferkabel als auch CPO-Erweiterungen unterstützen.
Der Fahrplan ist klar: Drei Wege – der Ausbau der Kupferkabelinfrastruktur, der Ausbau der Glasfaserinfrastruktur (Scale-Up) und der Ausbau der Glasfaserinfrastruktur (Scale-Out) – werden parallel verfolgt. Wir benötigen die kontinuierliche Unterstützung all unserer Partner beim Ausbau der Produktionskapazitäten für Kupferkabel, Glasfasern und CPO.
NVIDIA DSX: Eine digitale Zwillingsplattform für die KI-Fabrik
Die KI-Fabriken werden immer komplexer, aber die verschiedenen Technologieanbieter, aus denen sie bestehen, haben während der Entwurfsphase nie miteinander zusammengearbeitet, sondern sich nur im Rechenzentrum "getroffen" – was eindeutig nicht ausreicht.
Zu diesem Zweck haben wir Omniverse und die darauf aufbauende NVIDIA DSX-Plattform entwickelt – eine Plattform, die es allen Partnern ermöglicht, gemeinsam KI-Fabriken im Gigawatt-Maßstab in einer virtuellen Welt zu entwerfen und zu betreiben. DSX bietet:
Rack-Level-Simulationssysteme für Mechanik, Thermik, Elektrik und Netzwerke
Die Anbindung an das Stromnetz ermöglicht eine koordinierte, energiesparende Einsatzsteuerung.
Dynamische Leistungsaufnahme und Kühlungsoptimierung auf Basis von Max-Q in Rechenzentren
Konservative Schätzungen gehen davon aus, dass dieses System die Energieeffizienz um etwa das Zweifache steigern könnte, was angesichts des angestrebten Umfangs einen erheblichen Vorteil darstellt. Ausgehend von Digital Earth wird Omniverse digitale Zwillinge jeder Größe unterstützen, und wir arbeiten mit globalen Partnern zusammen, um den größten Computer der Menschheitsgeschichte zu bauen.
Darüber hinaus expandiert Nvidia in den Weltraum. Thor-Chips sind strahlungszertifiziert und werden in Satelliten eingesetzt. Gemeinsam mit Partnern entwickeln wir Vera Rubin Space-1 für den Bau von Weltraum-Rechenzentren. Das Wärmemanagement ist im Weltraum eine zentrale Herausforderung, da die Wärmeabfuhr ausschließlich über Strahlung erfolgt. Wir stellen dafür ein Team hochqualifizierter Ingenieure zusammen.
OpenClaw: Das Betriebssystem für das Zeitalter intelligenter Agenten
Peter Steinberger entwickelte eine Software namens OpenClaw. Dies ist das populärste Open-Source-Projekt in der Geschichte der Menschheit und übertraf die dreißigjährigen Erfolge von Linux in nur wenigen Wochen.
OpenClaw ist im Wesentlichen ein agentenbasiertes System, das Folgendes leisten kann:
Ressourcenverwaltung, Zugriff auf Tools, Dateisysteme und große Sprachmodelle.
Termin- und zeitgesteuerte Aufgaben ausführen
Zerlegen Sie das Problem Schritt für Schritt und rufen Sie die Unteragenten an.
Unterstützt Ein- und Ausgabe in allen Modalitäten (Sprache, Video, Text, E-Mail usw.).
Gemäß der Syntax eines Betriebssystems handelt es sich tatsächlich um ein Betriebssystem – ein Betriebssystem für intelligente Agentencomputer. Windows ermöglichte die Entwicklung von Personalcomputern; OpenClaw ermöglicht die Entwicklung persönlicher intelligenter Agenten.
Jedes Unternehmen muss seine eigene OpenClaw-Strategie entwickeln, genau wie wir alle Linux-Strategien, HTML-Strategien und Kubernetes-Strategien benötigen.
Eine vollständige Neugestaltung der Unternehmens-IT
Vor OpenClaw bestand die Unternehmens-IT aus Daten und Dateien, die in Systeme gelangten, durch Tools und Workflows flossen und schließlich zu Werkzeugen für den menschlichen Gebrauch wurden. Softwareunternehmen entwickelten die Tools, während Systemintegratoren und Beratungsfirmen Unternehmen bei deren Anwendung unterstützten.
Enterprise-IT nach OpenClaw: Jedes SaaS-Unternehmen wird sich in ein AaaS-Unternehmen (Agent as a Service) verwandeln – und zwar nicht nur durch die Bereitstellung von Tools, sondern auch durch die Bereitstellung von KI-Agenten, die auf bestimmte Bereiche spezialisiert sind.
Hierbei besteht jedoch eine zentrale Herausforderung: Intelligente Agenten innerhalb eines Unternehmens können auf sensible Daten zugreifen, Code ausführen und mit externen Stellen kommunizieren. Dies muss in einer Unternehmensumgebung streng kontrolliert werden.
Zu diesem Zweck haben wir uns mit Peter zusammengetan, um Sicherheitsfunktionen in die Unternehmensversion zu integrieren, was zu Folgendem geführt hat:
NeMo Claw (Referenzdesign): Ein Referenzframework der Enterprise-Klasse, basierend auf OpenClaw, das die komplette Suite intelligenter Agenten-KI-Toolkits von NVIDIA integriert.
Open Shield (Sicherheitsschicht): Integriert in OpenClaw, bietet eine Richtlinien-Engine, Netzwerkabschirmung und datenschutzorientiertes Routing, um die Datensicherheit im Unternehmen zu gewährleisten.
NeMo Cloud: Herunterladbar und nutzbar sowie kompatibel mit den Strategie-Engines aller SaaS-Unternehmen.
Dies ist eine Renaissance für die Unternehmens-IT, eine Branche, die ursprünglich einen Wert von 2 Billionen Dollar hatte und nun auf ein Volumen von mehreren Billionen Dollar anwachsen wird, wobei sich der Fokus von der Bereitstellung von Tools hin zur Bereitstellung spezialisierter KI-Agentendienste verlagert.
Ich bin überzeugt, dass zukünftig jeder Ingenieur im Unternehmen über ein jährliches Token-Budget verfügen wird. Ihr Jahresgehalt mag Hunderttausende von Dollar betragen, und ich werde ihnen zusätzlich Token im Wert der Hälfte ihres Gehalts zukommen lassen, wodurch sich ihre Leistung verzehnfacht. Die Frage „Wie viele Token erhält man beim Eintritt ins Unternehmen?“ ist zu einem neuen Thema bei der Personalsuche im Silicon Valley geworden.
Zukünftig wird jedes Unternehmen sowohl Token nutzen (für Entwickler) als auch Token produzieren (um seinen Kunden Dienstleistungen anzubieten). Die Bedeutung von OpenClaw darf nicht unterschätzt werden; es ist so wichtig wie HTML und Linux.
NVIDIA Open Model Initiative
Bezüglich der Custom Claws bieten wir NVIDIAs hochmodernes, selbstentwickeltes Modell an:
Zu den Modellierungsdomänen gehören Nemotron (großskaliges Sprachmodell), Cosmos (World Foundation Model), GROOT (universell einsetzbares humanoides Robotermodell), Alpamayo (autonomes Fahren), BioNeMo (digitale Biologie) und Phys-AI (Physik).
Wir sind in allen Bereichen technologisch führend und setzen auf kontinuierliche Weiterentwicklung – auf Nemotron 3 folgte Nemotron 4, auf Cosmos 1 Cosmos 2, und auch Groq wird in die zweite Generation weiterentwickelt.
Nemotron 3 zählt weltweit zu den drei besten Modellen in OpenClaw und ist damit führend auf diesem Gebiet. Nemotron 3 Ultra wird das leistungsstärkste Basismodell aller Zeiten sein und Länder beim Aufbau souveräner KI unterstützen.
Heute geben wir die Gründung des Nemotron-Konsortiums bekannt, das Milliarden von Dollar in die Weiterentwicklung grundlegender KI-Modelle investiert. Zu den Mitgliedern des Konsortiums gehören BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (Indien) und Thinking Machines (das Labor von Mira Murati). Auch Unternehmen der Unternehmenssoftwarebranche schließen sich an und integrieren das NeMo Claw-Referenzdesign und das AI Agent Toolkit von NVIDIA in ihre Produkte.
Physik, KI und Robotik
Digitale intelligente Agenten agieren in der digitalen Welt – sie schreiben Code und analysieren Daten; physische KI hingegen ist ein verkörperter intelligenter Agent, also ein Roboter.
Auf der diesjährigen GTC wurden insgesamt 110 Roboter präsentiert, die nahezu alle Robotik-Forschungs- und Entwicklungsunternehmen weltweit repräsentierten. NVIDIA stellte drei Computer (Trainingscomputer, Simulationscomputer und Bordcomputer) sowie einen kompletten Software-Stack und KI-Modelle zur Verfügung.
Im Bereich des autonomen Fahrens ist der entscheidende Moment gekommen. Wir geben heute vier neue Partner für die NVIDIA RoboTaxi Ready Plattform bekannt: BYD, Hyundai, Nissan und Geely mit einer gemeinsamen jährlichen Produktionskapazität von 18 Millionen Fahrzeugen. Dies stärkt die bestehende Partnerschaft mit Mercedes-Benz, Toyota und GM. Zudem verkünden wir eine bedeutende Partnerschaft mit Uber zur Einführung und Integration von RoboTaxi Ready Fahrzeugen in mehreren Städten.
Im Bereich der Industrieroboter arbeiten viele Roboterhersteller wie ABB, Universal Robots und KUKA mit uns zusammen, um physikalische KI-Modelle mit Simulationssystemen zu kombinieren und so den Einsatz von Robotern in Fertigungslinien weltweit voranzutreiben.
Im Telekommunikationssektor zählen auch Caterpillar und T-Mobile dazu. Zukünftig werden drahtlose Basisstationen nicht mehr nur Kommunikationsknotenpunkte sein, sondern intelligente Edge-Computing-Plattformen wie NVIDIA Aerial AI RAN – die in der Lage sind, den Datenverkehr in Echtzeit zu erfassen, die Strahlformung anzupassen und Energieeinsparungen sowie Effizienz zu erzielen.
Spezialbeitrag: Der Roboter Olaf feiert sein Debüt
(Es wird ein Demonstrationsvideo des Disney-Roboters Olaf abgespielt)
Jensen Huang: Der Schneemann ist da! Newton funktioniert einwandfrei! Omniverse funktioniert auch einwandfrei! Olaf, wie geht es dir?
Olaf: Ich freue mich sehr, dich zu sehen.
Jensen Huang: Ja, weil ich dir den Computer gegeben habe – Jetson!
Olaf: Was ist das?
Huang Renxun: Es ist direkt in deinem Bauch.
Olaf: Das ist fantastisch.
Jensen Huang: Du hast in Omniverse laufen gelernt.
Olaf: Ich gehe gern spazieren. Das ist viel besser, als auf einem Rentier zu reiten und in den schönen Himmel hinaufzuschauen.
Jensen Huang: Das liegt genau an der Physiksimulation – basierend auf dem Newton-Solver, der auf NVIDIA Warp läuft und den wir in Zusammenarbeit mit Disney und DeepMind entwickelt haben. Dadurch können Sie sich an die reale physikalische Welt anpassen.
Olaf: Genau das wollte ich auch sagen.
Jensen Huang: Genau da liegt deine Intelligenz. Ich bin ein Schneemann, kein Schneeball.
Jensen Huang: Können Sie sich das vorstellen? Ein Disneyland der Zukunft – lauter Roboterfiguren, die frei im Park herumlaufen. Aber ehrlich gesagt, ich dachte, Sie wären größer. So einen kleinen Schneemann habe ich noch nie gesehen.
Olaf: (Kein Kommentar)
Jensen Huang: Können Sie mir helfen, meine Rede heute zu beenden?
Olaf: Das ist ja genial!
Zusammenfassung der Hauptrede
Jensen Huang: Heute haben wir gemeinsam die folgenden Kernthemen besprochen:
Der Wendepunkt ist erreicht: Inferenz ist zur Kernaufgabe der KI geworden, Token sind die neue Ware, und die Inferenzleistung bestimmt direkt den Umsatz.
Das Zeitalter der KI-Fabrik: Rechenzentren haben sich von reinen Datenspeichern zu Token-Produktionsstätten entwickelt. Künftig wird jedes Unternehmen seine Wettbewerbsfähigkeit an der Effizienz seiner „KI-Fabrik“ messen.
OpenClaws Revolution intelligenter Agenten: OpenClaw hat das Zeitalter des intelligenten Agenten-Computing eingeläutet. Die Unternehmens-IT vollzieht den Wandel von der Werkzeug- zur Ära intelligenter Agenten, und jedes Unternehmen muss eine OpenClaw-Strategie entwickeln.
Physische KI und Robotik: Verkörperte Intelligenz wird in großem Umfang eingesetzt, wobei autonomes Fahren, Industrieroboter und humanoide Roboter zusammen die nächste große Chance für physische KI darstellen.
Vielen Dank an alle, viel Spaß beim GTC! #黄仁勋 #GTC #AI $BTC $ETH